Inhaltsverzeichnis
[at] bildet eigene Daten- und KI-Experten aus
[at] bildet seit einigen Jahren Data Scientists und Data Engineers durch ein Traineeprogramm selbst aus. Während des einjährigen Programms rotieren die Trainees durch mehrere [at]-Teams, um an unterschiedlichen Projekten zu arbeiten und so Expertise auf verschiedenen Gebieten aufzubauen.
Als Novum wurde 2020 das data.camp eingeführt – ein viertägiger Workshop, bei dem alle Trainees zusammen an einem gemeinsamen Projekt ihrer Wahl arbeiten. Ziel dabei ist es, Teamarbeit zu fördern und praktische Erfahrungen zu sammeln.
Um nicht durch das Tagesgeschäft abgelenkt zu werden, findet das data.camp in der Regel in den [at] Projekträumen in Österreich statt. Aufgrund der Corona-Pandemie musste das erste data.camp im Oktober 2020 im Münchner Büro stattfinden. Das Team konnte jedoch die neuen [at]-Büroräume (im selben Gebäude) nutzen, um zumindest eine Art ‚Camp‘-Feeling zu haben.
Hier finden sich weitere Informationen zu den Traineeprogrammen für Data Scientists und Data Engineers.

Thema des ersten data.camps: automatisiertes Googeln
Das Thema des ersten data.camp orientierte sich an einem laufenden [at]-Kundenprojekt. Wir wählten das Thema automatisiertes Googeln, da es drei Kernbereiche abdeckt: Analytics, Engineering und Visualisierung. Das ursprüngliche Projektsetting war wie folgt:
Immer wenn Mitarbeiter eines [at]-Kunden einen Lieferanten für einen bestimmten Bedarf benötigten, schickten sie ihre Anforderungen an das Lieferantenmanagement. Dort suchte ein anderer Mitarbeiter im Internet nach einem passenden Lieferanten – zum Beispiel eine Anfrage über KI-Schulungen. Die Aufgabe für [at] war es, diesen Prozess zu automatisieren.
Zu Beginn hatten die [at]-Kollegen bereits einen Algorithmus entwickelt, dessen Input ein Bedarfstext war und der als Output eine Liste möglicher Lieferanten lieferte (siehe unten). Dabei extrahierte der Algorithmus zunächst Schlüsselphrasen aus dem Bedarfstext und erstellte daraus Suchanfragen. Diese Suchanfragen wurden an Google gesendet, um eine Liste potenzieller Unternehmen zu erhalten. Um sicherzustellen, dass es sich bei diesen Unternehmen tatsächlich um Unternehmen handelt, wurden diese mit der Unternehmensdatenbank Crunchbase abgeglichen. Von allen verifizierten Unternehmen wurde eine Beschreibung aus dem Web abgerufen (wiederum eine Google-Suche), die dann mit dem ursprünglichen Anfragentext verglichen wurde (unter Verwendung von natürlicher Sprachverarbeitung). Schließlich gab der Algorithmus alle Unternehmen aus, deren Beschreibungen dem Bedarfstext ausreichend ähnlich waren.
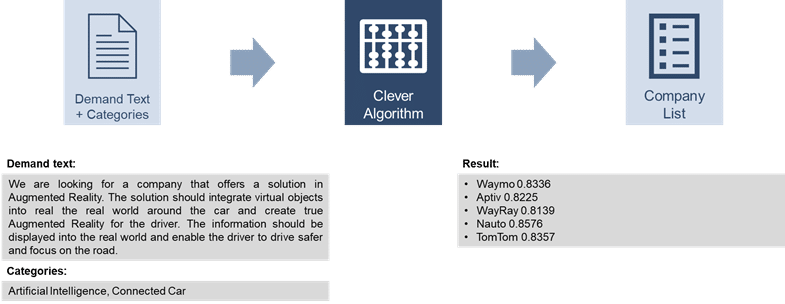
Projektsetting: Natürlich agil
Da sich Datenprojekte ständig mit neuen Entwicklungen verändern, nutzten wir Scrum als Rahmen, um agil zu arbeiten.
Dazu ernannten wir einen Scrum Master, einen Product Owner und fünf Entwickler. Jeden Tag hatten wir mehrere Scrum-Meetings, um uns abzustimmen. Das machte das data.camp zu einer guten Gelegenheit dafür, Scrum und all seine Konzepte auszuprobieren.
Hinter den Kulissen standen uns erfahrene [at]-Kollegen als Ressource für unsere Fragen zur Verfügung. Dies ermöglichte es uns, sehr schnell voranzukommen und professionelle Lösungen zu entwickeln.

Lernfortschritte in den Bereichen Analytics, Engineering und Visualisierung
Jeder, der schon einmal an einem Hackathon teilgenommen hat, weiß vielleicht, wie viel man innerhalb weniger Tage erreichen kann. Das war unser Vorgehen:
In einem Workstream wurden die Fähigkeiten des Algorithmus zur Verarbeitung natürlicher Sprache verbessert. Da sich die Anfragetexte in der Regel um Technologien drehten, haben wir dem Algorithmus Beispiele für Wörter beigebracht, die uns interessieren (z. B. „augmented reality“ oder „machine learning“). Dies ermöglichte es uns, bessere Suchanfragen aus den Bedarfstexten zu erstellen.
Die Laufzeit des gesamten Algorithmus lag zu Beginn bei etwa 30 Minuten. Da dies nicht nur zu einem schlechten Kundenerlebnis führt, sondern auch die Entwicklung erheblich erschwert (stellen Sie sich vor, jedes Mal 30 Minuten zu warten, wenn Sie etwas ausprobieren wollen), zielte ein weiterer Workstream darauf ab, die Laufzeit zu reduzieren. Wir erhöhten die Rechenleistung, indem wir das Projekt in die Cloud verlegten, und luden die Crunchbase-Datenbank (für die Unternehmensverifizierung) herunter, um sie lokal zu nutzen, anstatt für jede Verifizierung API-Aufrufe zu tätigen. Beide Maßnahmen führten zu einer Reduzierung der Laufzeit auf nur 2,5 Minuten.

© [at] 
© [at]
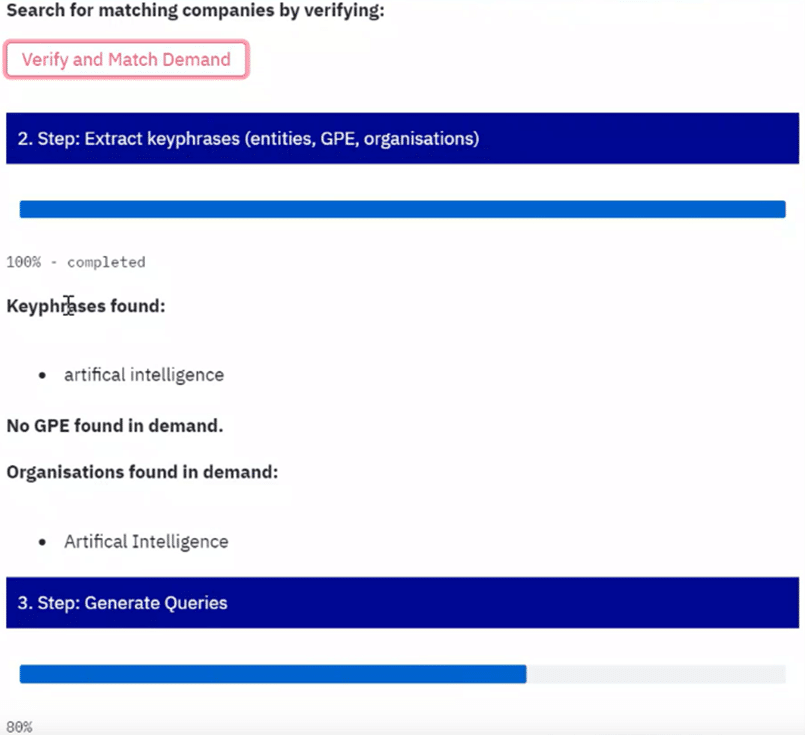
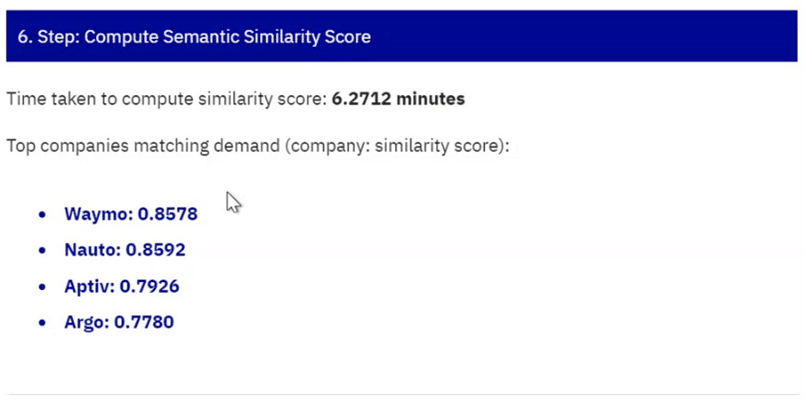
Generell läuft hinter den Kulissen eines maschinellen Lerndienstes eine Menge ab – man denke nur an all die Schritte unseres Algorithmus, um einen einfachen Anfragetext in eine Firmenliste umzuwandeln. Obwohl es für den Endnutzer sehr bequem sein kann, dass all diese Komplexität verborgen ist, müssen einige vielleicht verstehen, wie das Endergebnis abgerufen wurde. Daher wurden im letzten Workstream alle Zwischenergebnisse ausgegeben und in einer App in Echtzeit angezeigt.
Zusammenfassung und Take-Aways
“Wir haben viel gelernt und hatten dabei eine Menge Spaß“ ist eine sehr gute Zusammenfassung des ersten data.camps. Neben den technischen Lernerfolgen in Analytics, Engineering und Visualisierung haben wir sehr wertvolle Erfahrungen in der Arbeit mit Scrum gesammelt. Außerdem hat diese Art der Zusammenarbeit den Teamgeist der Trainees sehr gestärkt, wovon wir noch lange nach diesem data.camp profitieren werden.

Unsere Trainees vom Oktober 20
Daniel, Louis, Thanos, Simon, Sebastian, Julian, Luca (am Laptop-Bildschirm)



0 Kommentare