
Lange Zeit galt das Data Warehouse als zentrale Quelle für sämtliche Datenanalysen. Im Zuge der zunehmenden Digitalisierung und der damit einhergehenden Masse an zur Verfügung stehenden Datenmengen hat mittlerweile der Data Lake dem klassischen Data Warehouse den Rang abgelaufen. Zahlreiche Use Cases aus dem Kontext Industrie 4.0 sind ohne eine geeignete Datenplattform auf Basis des Data Lake Konzepts nicht denkbar.
Inhaltsverzeichnis
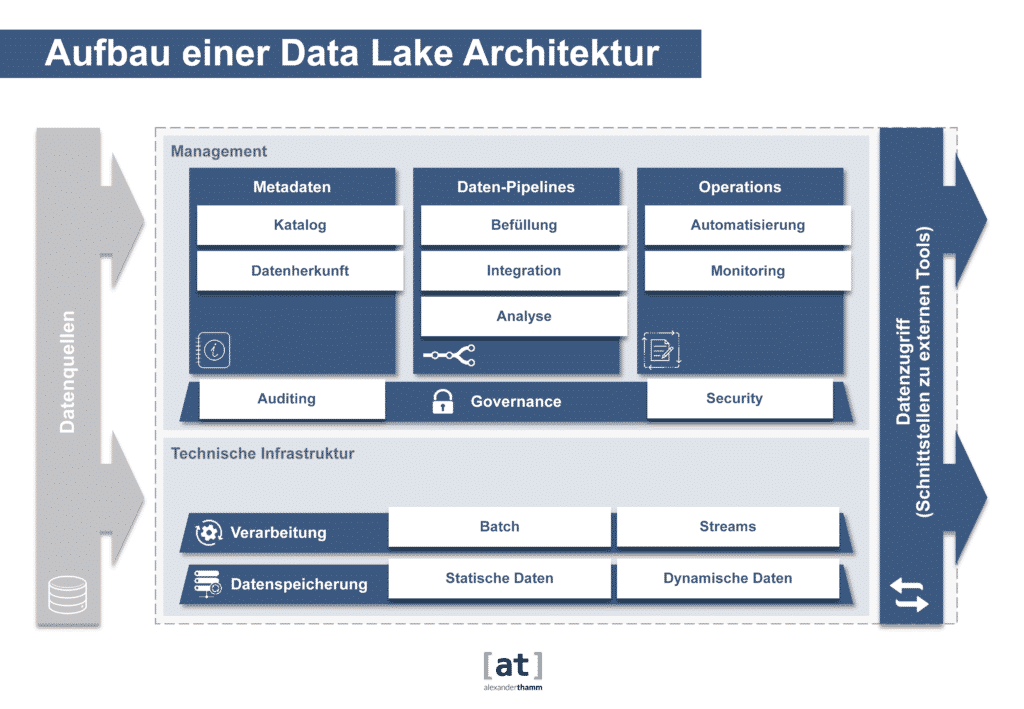
Die Daten Architektur
Die richtige Architektur für die dispositive Datenverarbeitung war seit den 90er Jahren klar definiert. Ein idealtypisch singuläres (Enterprise) Data Warehouse sammelt in einem Hub-&-Spoke-Ansatz aus den unterschiedlichen operativen Quellsystemen die relevanten Daten auf und harmonisiert, integriert und persistiert diese in einem mehrschichtigen Datenintegrations- und Datenveredelungsprozess. So sollte aus einer Datenperspektive ein Single Point-of-Truth entstehen, aus dem wiederum für unterschiedliche Anwendungsfälle anschließend Datenextrakte – in der Regel in einer multidimensionalen Aufbereitung – in abgrenzbaren Data Marts gespeichert werden. Der Anwender greift auf diesen Datenschatz über Berichts- und Analysewerkzeuge (Business Intelligence) zu. Der primäre Fokus liegt dabei auf der eher vergangenheitsorientierten Analyse von Kennzahlen entlang von konsolidierten Auswertungsstrukturen.
Charakteristik eines Data Warehouse
Wesentliches Charakteristikum des Data Warehouse ist es eine, gültige und konsolidierte Wahrheit zu allen strukturierten Daten in einem Unternehmen zu repräsentieren. Neben dieser einheitlichen Sicht auf die Unternehmensdaten stellt das Data Warehouse die Daten für die Auswertung optimiert in einem strikten und vorab definierten Datenmodell zur Verfügung. Dieser hohe Anspruch an Korrektheit und Harmonisierungsgrad führte in der Regel dazu, dass es recht lange dauert, bis Daten aus einer neuen Datenquelle in die konsolidierte Sicht integriert sind, weil im Vorfeld viel Konzeptions- und Abstimmungsaufwand nötig wird.
Schnelle Datenaufbereitung mit dem Data Lake
Mit dem Aufkommen neuer Datenquellen, wie Social Media oder IoT-Daten stieg der Bedarf auch diese an einer Datenplattform zur Verfügung zu stellen. Viele dieser Daten liegen dann in semistrukturierter oder unstrukturierter Form vor. Mit der steigenden Relevanz dieser Datenquellen wurde die Idee des Data Lake geboren. Der Data Lake möchte alle Quelldaten – interne und externe, strukturierte und polystrukturierte – auch in ihrer nicht aufbereiteten Form als Rohdaten zur Verfügung stellen, um sie möglichst schnell verfügbar zu haben. Der effiziente Umgang mit großen Datenmengen, eine schnelle Verarbeitung von Datenströmen und die Beherrschung komplexer Analysen steht beim Data Lake zulasten der Harmonisierung und Integration der Daten im Vordergrund.
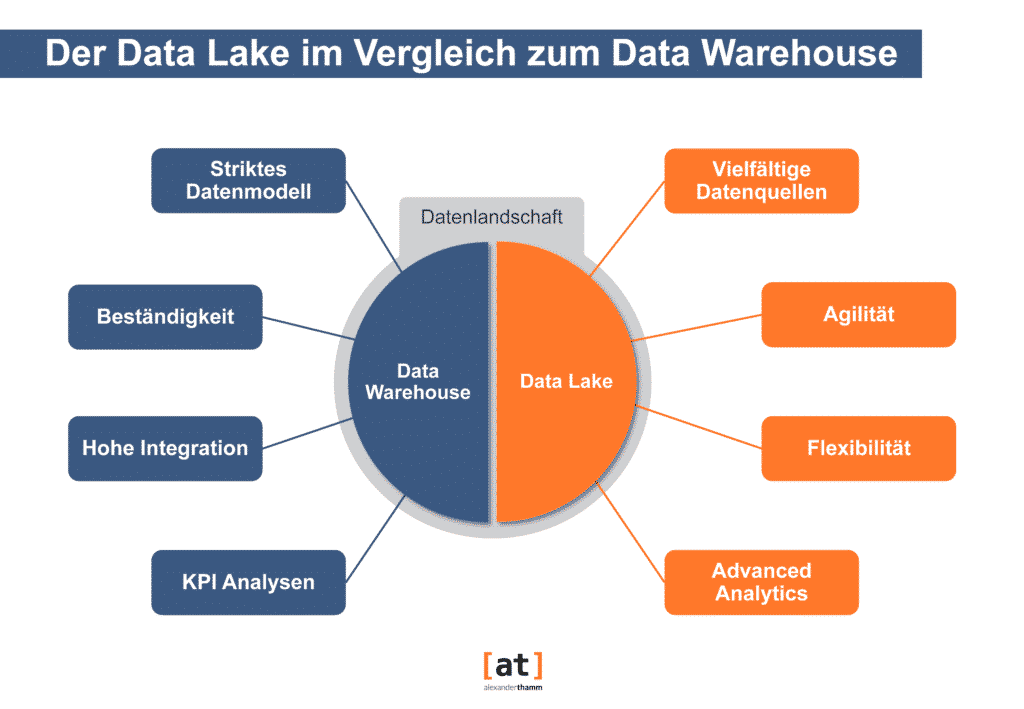
Data Warehouse vs. Data Lake
Im Vergleich zum Data Warehouse steht also beim Data Lake eher die Integration vielfältiger Datenquellen bei einer möglichst hohen Agilität und Flexibilität im Vordergrund, um so die Datenbasis für vielfältige fortgeschrittenen Datenanalysen zu schaffen, die in der Regel zum Zeitpunkt der Datenspeicherung noch gar nicht festgelegt sind. Der Data Lake bildet also das Eldorado für den Data Scientist, der explorative Analysen wie Cluster-/Assoziationsanalysen, Simulationen und Vorhersagen über komplexe Algorithmen durchführen möchte. Damit ist auch klar, dass ein Data Lake ein Data Warehouse nicht ersetzt, sondern ergänzt. Beide Architekturkonzepte haben ihre Relevanz und bedienen zueinander unterschiedliche Use Cases.
| Data Warehouse | Data Lake | |
| Daten | – Keine Rohdatenspeicherung – Strukturierte Daten – Schema-on-write: Daten werden vor dem Laden ins Data Warehouse in ein bestimmtes Schema transformiert | – Rohdatenspeicherung – Flexibel bezüglich der Datenstruktur (unstrukturiert und strukturiert) – Schema-on-read: Automatische Erkennung des Schemas beim Lesevorgang |
| Verarbeitung | Datenschicht mit Verarbeitungsschicht untrennbar verbunden | Sehr flexibel, weil verschiedene Frameworks zur Verarbeitung für verschiedene Aufgabenbereiche vorhanden sind |
| Analytics | Deskriptive Statistiken | Advanced Analytics |
| Agilität | – Geringere Agilität – Festgelegte Konfiguration – Ad-hoc Analysen nicht möglich | – Hohe Agilität – Konfiguration anpassbar – Ad-hoc Analysen möglich |
| Sicherheit | Ausgereift | – Durch die Vielzahl an Technologien, die innerhalb eines Data Lakes Anwendung finden, sind Mehrfachkonfigurationen notwendig – Sicherheitsrichtlinien sind komplexer |
In der Industrie sind zwei große fachliche Treiber für den Einsatz von Data Lakes zu nennen: Die Optimierung der Produktion und das Angebot besserer oder neuer Produkte, teilweise auch ganz neuer Geschäftsmodelle. Die Basis Use Cases bilden hier der „Digitale Zwilling“, also das digitale Abbild der eigenen produzierten Maschinen und die Anbindung dieser an den Data Lake mit fast Echtzeit-Datenaktualität. Zwei große Hindernisse sind in der Praxis dabei zu bewältigen: Die benötigten Stammdaten zu Materialien und Komponenten liegen in bisher nicht maschinell miteinander kommunizierenden Systemen unterschiedlicher Organisationseinheiten. Zudem werden auf der technischen Ebene unterschiedliche technische Protokolle verwendet, sodass als Voraussetzung für die Datenverfügbarkeit erst noch Nachrüstungen von Kommunikationskomponenten erfolgen müssen.
Die Technologie
Die Data Lakes der ersten Generation waren auf dem Apache Hadoop Stack basierende Systeme im eigenen Rechenzentrum. Bei diesen frühen Plattformen waren zusätzlich die Komplexität der Technologie, bestehend aus zahlreichen Open Source Komponenten sowie die Anbindung in der benötigten zeitlichen Aktualität herausfordernd. Durch die Veränderung der Marktsituation der kommerziellen Distributionsanbieter und die allgemeine Strategie der verstärkten Cloud-Nutzung verlagern sich dieses bei Data Lakes der zweiten Generation: Bei Nutzung von nativen Cloud-Services und oder dedizierten managed Hadoop Umgebungen vereinfacht sich die Komplexität des Managements der Basisplattform massiv. Somit ist die Eintrittsbarriere gesunken und ermöglicht heute den Einsatz für nahezu jede Unternehmensgröße.
Weiterhin bleibt jedoch die Empfehlung gültig, Technologie erst dann einzusetzen, wenn eine klare Use Case Bewertung und Priorisierung auf einer Roadmap als Grundstein des Einsatzes definiert wurde!
Auswahl der richtigen Technologie
Die Auswahlentscheidung der initial einzusetzenden Komponenten ist wohlüberlegt zu treffen und es ist eine kontinuierliche Suche und Bewertung von Alternativen aus dem Markt der kommerziellen, Open Source und Cloud Services Optionen durchzuführen, um einen optimalen Mehrwert für das Unternehmen schaffen zu können.
Bei der Auswahl der für das eigene Unternehmen zu wählenden Komponenten steht im industriellen Einsatz neben den funktionalen Anforderungen insbesondere der Schutz der Wahrung von Geschäftsgeheimnissen gegenüber (globalen) Mitbewerbern zu und legale Aspekte, wie z.B. die Nutzung der Plattform mit Daten aus Länder, in denen gesetzliche Auflagen den Datenaustausch geografisch beschränken, im Vordergrund. Besonderheit bei Maschinenherstellern ist die zusätzliche Herausforderung, an die Daten der eigenen Maschinen im Kundenkontext zu gelangen, da häufig Maschinen unterschiedlicher Hersteller kombiniert eingesetzt werden und Kunden wiederum nicht alle Daten zum Schutz ihres Unternehmens preisgeben.
Ein weiteres Spannungsfeld bilden die Anforderungen produktiver Use Cases gegenüber den Bedürfnissen der Data Science Nutzer. Auch hier hat sich der Ansatz mit der Zeit gewandelt: Versuchte man zunächst Plattformen aufzubauen, die alle Nutzungsprofile – von Bereitstellung einer API für ein Kundenportal mit hohen Anforderungen an die Antwortzeit, bis hin zu komplexen analytischen Anfragen – gleichsam bedienen konnten, hat sich die Aufteilung dieser auf verschiedene technische Plattformen als praktikabler erwiesen.
Die Schlüsselbedingungen in der Praxis
Beim Aufbau einer Data Lake Initiative zeigen sich in der Praxis Schlüsselbedingungen als Grundlage für eine erfolgreiche Durchführung, die denen der Implementierung eines zentralen Data Warehouse ähneln: Eine starke Managemententscheidung für den Aufbau und die Nutzung einer zentralen Plattforminitiative und die daraus resultierende, vielfach bisher nicht gelebte, enge Zusammenarbeit zwischen Fach- und Produktions-IT, ggfs. auch Produktentwicklung sind elementar. Somit werden nicht nur vielfältige Daten zusammengeführt, sondern auch das Wissen über diese Daten, wie z.B. der Signale einzelner Sensoren und der Interpretation der Zustände als System, wird vereint.
Nicht zuletzt der Betrieb eine Data Lakes ist entsprechend flexibel und ganzheitlich aufzustellen: Als Best Practice hat sich ein DevOps Team bewährt, welches die Plattform kontinuierlich weiterentwickelt und stabil im Betrieb hält.
Fazit
Als Fazit lässt sich zusammenfassen, dass jede Industrie 4.0 Initiative eine Data Lake Plattform benötigt. Die technologische Eintrittsbarriere ist gesunken, bedingt aber weiterhin eine fundierte Planung der Architektur. Die Basis sollte eine Roadmap zum Einsatz für Use Cases bilden. Für eine Maximierung der resultierenden langfristigen Wertschöpfung ist es zudem wichtig, flankierend zur Technologie die notwendigen organisatorischen Voraussetzungen für den erfolgreichen Einsatz einer Data Lake Plattform zu schaffen.







0 Kommentare