
Was haben eine Maschinenhalle und ein Pflegeheim gemeinsam? Die Antwort: Beide Bereiche profitieren von einer Lösung, die Pfützen auf dem Boden erkennt und so Unfälle vermeiden kann.
In diesem Beitrag stellen wir ein Forschungsprojekt vor, an dem wir an dieser Aufgabenstellung arbeiten. Sie erhalten einen Einblick in unsere Rolle dabei als Data-Science-Beratung, in unsere Herausforderungen beim Projekt, wichtige Entscheidungen und schlussendlich das Ergebnis.



Inhaltsverzeichnis
Unternehmensziele und die Rolle von Forschungsprojekten bei [at]
Eine Beratung ist auf die speziellen Bedürfnisse der Kunden ausgerichtet. Zu den regelmäßigen Projekten gehört es, bestehende State-of-the-Art-Technologien auf Anwendungsfälle anzuwenden oder dem Kunden die Denkweise eines digitalen Unternehmens näherzubringen. Aber ist das alles, was eine Beratung ausmacht? Glücklicherweise haben wir bei [at] die Möglichkeit, die KI-Forschung in mehreren innovativen Projekten zu unterstützen. Eines unserer aktuellen Projekte nennt sich S³.
S³ – kurz für „Sicherheitssensorik für Serviceroboter in der Produktionslogistik und stationären Pflege“ – ist ein Kooperationsprojekt, in dem sich Partner aus den Bereichen Logistik, Gesundheitswesen und Robotik sowie von Universitäten zusammenfinden, um einen Schritt nach vorne in der angewandten Forschung (Elektronikforschung des Bundesministeriums für Bildung und Forschung) zu machen. Das Projekt wird vom Bundesministerium für Bildung und Forschung gefördert und wir arbeiten mit den folgenden Partnern zusammen:
- Institut für Fördertechnik und Logistik (IFT), Universität Stuttgart
- Fraunhofer-Institut für Produktionstechnik und Automatisierung (IPA), Abteilung für Roboter- und Assistenzsysteme
- Pilz GmbH
- Bruderhaus Diakonie
Das langfristige Ziel von S³ ist die Ableitung der Roboterunterstützung im industriellen Kontext sowie in Gesundheitseinrichtungen. Mit dem Wissen um dieses weite Feld der Forschung, welche Rolle spielt [at] als Berater in dieser Kooperation? Unserer Erfahrung nach funktioniert Zusammenarbeit dann reibungslos, wenn jeder Teilnehmer seinen eigenen Aufgabenbereich hat. Für uns bedeutet das die Umsetzung von Machine-Learning Use Cases:
- Automatische Erkennung von verschütteten Flüssigkeiten auf dem Boden (für Industrie und Gesundheitswesen)
- Füllstanderkennung von Gläsern und Flaschen (für das Gesundheitswesen)
- Erkennung von Anomalien bei Objekten und Menschen (für Industrie und Gesundheitswesen)


Im Folgenden schildern wir das Vorgehen – vom Greenfield bis zum trainierten Modell.
Vorteile und Herausforderungen der Erkennung verschütteter Flüssigkeiten
Auf hohem Niveau ist das Ziel des Use Cases „Spillage detection“ ein Modell zu entwerfen, das industrielle Flüssigkeiten auf dem Boden sowie verschüttete Flüssigkeiten in Einrichtungen des Gesundheitswesens (z. B. in Pflegeheimen) automatisch erkennt. In Zukunft sollen Roboter mit dieser Technologie ausgestattet werden, die es ihnen ermöglicht, Pfützen auf dem Boden zu lokalisieren und so Unfälle zu vermeiden, indem das Wartungspersonal alarmiert wird. Zudem sollte der Roboter selbst nicht durch die Flüssigkeit behindert werden.
Verschüttete Flüssigkeiten auf dem Boden sind eine potenzielle Gefahr für autonome Systeme und Menschen. Elektronik kann ausfallen und Menschen können ausrutschen und sich verletzen. Darüber hinaus kann die Flüssigkeit auf dem Boden chemische, biologische oder anderweitig gefährliche Bestandteile haben, die nicht weiter verbreitet werden sollen. Roboter, die derzeit in der Industrie und im Gesundheitswesen eingesetzt werden, erkennen normalerweise nur eine Anomalie auf dem Boden, halten an und warten, bis sich ein Mensch um die Situation kümmert. Deshalb kann ein Modell, das die Pfütze präzise erkennen, einen Alarm senden und die Pfütze sicher umfahren kann, viel Zeit sparen, mögliche Zwischenfälle verringern und den Betriebsablauf reibungsloser gestalten. Nichtsdestotrotz stellt die Anforderung, ausgelaufene Flüssigkeiten in unterschiedlichen Innenräumen zu erkennen, die Herausforderung dafür dar, ein Modell zu entwickeln, das eine breite Anwendung hat.
Der Bereich der Erkennung von Objekten auf Bildern durch ML-Techniken ist sehr gut entwickelt. Was macht unseren Anwendungsfall so herausfordernd? Warum können vortrainierte Modelle dieses Problem nicht von Haus aus lösen? Lassen Sie uns mit der allgemeinen Schwierigkeit beginnen. Verschüttete Flüssigkeiten sind von unterschiedlicher Form und Farbe und ihre Textur hängt stark von der Umgebung ab. Zusätzlich erschwert die Reflexion der Pfützenoberfläche den Out-of-the-Box-Objekterkennungsalgorithmen das richtige Lernen. Eine noch gravierendere (und in der ML-Forschung weit verbreitete) Herausforderung ist die Tatsache, dass es bisher keine gelabelten Datensätze für die Erkennung von Flüssigkeiten in Innenräumen gibt.
Daten: Ein erster Ansatzpunkt in ML-Projekten
Die Untersuchung von State-of-the-Art-Ansätzen für unseren Use Case weist direkt auf Datensätze für autonomes Fahren hin, da selbstfahrende Autos auch Flüssigkeiten auf dem Boden erkennen müssen. Der Puddle-1000-Datensatz und das von australischen Forschern entwickelte Modell (https://github.com/Cow911/SingleImageWaterHazardDetectionWithRAU) haben bewiesen, dass Bildsegmentierungsansätze in Bezug auf die Erkennung von Wasserpfützen im Freien vielversprechend sind. Das in diesem Projekt verwendete Modell basierte auf Reflection Attention Units mit einem TensorFlow-Setup im Hintergrund. Wir haben dazu als ersten Ansatz ein dynamisches UNET von fast.ai auf dem Puddle-100-Datensatz implementiert. Neben schnellen Ergebnissen war ein wertvolles Ergebnis dieser Vorgehensweise ein besseres Gefühl und Verständnis für die Natur von Pfützen: Einen großen Einfluss auf Pfützen haben die Umgebung (z.B. durch Spiegelung), die Perspektive, aus der die Bilder aufgenommen wurden, und vor allem die Lichteinwirkung. Da all diese Eigenschaften in Außen- und Innenszenarien enorm unterschiedlich sind, beschlossen wir, dass ein neuer und selbst produzierter Datensatz, angepasst an unseren Anwendungsfall in Innenräumen, benötigt wurde.
Nachdem wir diese Entscheidung getroffen hatten, stellten sich viele Fragen: Welche Daten brauchen wir? Wie sammeln wir sie? Welche Metadaten sind wertvoll? Als Ausgangspunkt erstellten wir eine Liste mit wichtigen Einflussfaktoren, die bei der Videoaufzeichnung berücksichtigt werden sollten:
- Licht (elektrisch vs. natürlich, hell vs. dunkel, Schatten, Position der Lichtquelle)
- Hintergrund der Innenraumszene (Farbe und Textur des Bodens, natürliche Reflexionen auf trockenem Boden, Anzahl und Beweglichkeit der Objekte in der Szene)
- Größe/Menge des verschütteten Wassers (kein Verschütten, kleiner Fleck vs. ganzer Boden, ein Fleck vs. viele Flecken)
- Ausrichtung der Kamera (horizontal, Blick nach oben vs. Blick nach unten)
- Bewegung in der Szene (stehend vs. fahrend, Richtungswechsel)
- Art der Pfütze (Wasser, Kaffee, gefärbtes Wasser zur Nachahmung gefährlicher Flüssigkeiten)
Daher entschieden wir uns, Videos zu erstellen, die Roboter in den Bewegungen nachahmen und einen gleichmäßig verteilten medizinischen und industriellen Hintergrund verwenden. Das Ergebnis waren 51 Videos, jeweils 30-60 Sekunden, zusammen mit einer Excel-Tabelle, die die Metadaten jedes Videos komprimiert.



Mitte: Wasserpfütze in Industriehalle, rechts: Kaffeepfütze auf Fliesen
Eine wichtige Lektion war, dass die Verteilung der Umgebungsvariablen vor Beginn der Aufzeichnung geklärt werden muss, um einen wertvollen Datensatz zum Trainieren eines Modells für unseren speziellen Anwendungsfall zu erstellen.
Das Labeling der Daten: Aufwendig, aber unverzichtbar
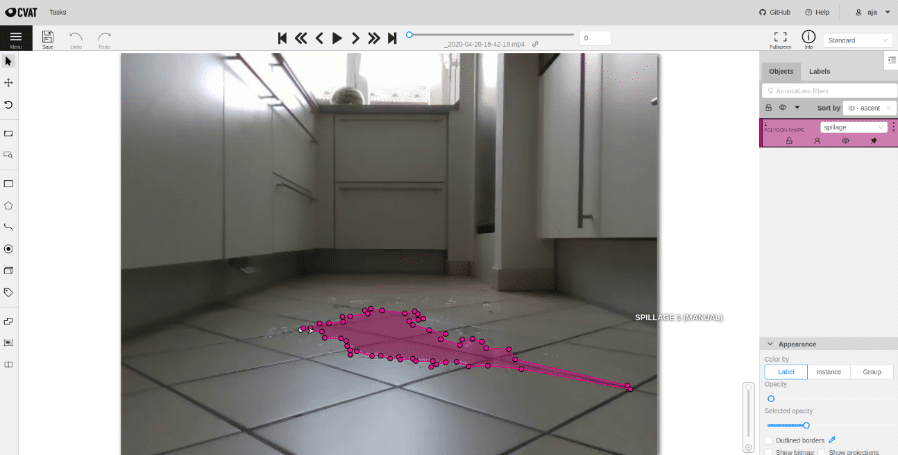
Nun, da wir unseren eigenen Datensatz haben, steht die nächste große Aufgabe für das überwachte Lernen an: das Labeln der Daten! Für Segmentierungsaufgaben ist dies der wichtigste und aufwendigste Teil, um einen Datensatz wertvoll zu machen. Da die Anforderung in unserem Anwendungsfall der Segmentierung darin besteht, präzise Grenzen der Pfütze zu erkennen, mussten wir in jedem Bild hochkomplexe Polygone zeichnen. Aufgrund des geschätzten hohen Aufwand des Labeling sahen wir die Notwendigkeit für eine geeignete Plattform, auf der viele Leute (nicht unbedingt mit tiefem Domänenwissen, z.B. Werkstudenten) gemeinsam arbeiten können.
Das Ergebnis war die Einrichtung eines hochautomatisierten Tools namens CVAT (Computer Vision Annotation Tool, entwickelt von Intel und OpenCV) mit Anbindung an einen Cloud-Server und Speicher. Ein Vorteil dieser Lösung ist die Möglichkeit, sie im Web einzusetzen und dadurch eine einfach zu bedienende Oberfläche (kann in einem Browser ausgeführt werden) für alle Benutzer zu haben. Zusätzlich ermöglicht sie eine einfache Automatisierung von Aufgaben durch die Verwendung einer Rest-API. Erfahren Sie mehr über diese Implementierung in einem unserer zukünftigen Blog-Beiträge über Best Practices beim Labeling!
So finden Sie das richtige Modell
Der erste Schritt, bevor wir mit dem ML Coding beginnen, ist die Einrichtung einer Entwicklungsumgebung, die kollaboratives Arbeiten in schnellen Iterationen ermöglicht und die Grundlage für eine skalierbare und reproduzierbare Lösung schafft. Der Einfachheit halber haben wir uns für die Entwicklung in Jupyter Notebooks entschieden, die auf einem On-Premise GPU Cluster mit vier GPU-Knoten mit jeweils ~12 GB Speicher gehostet werden. Die On-Premise-Lösung hatte für uns zwei große Vorteile: niedrigere Kosten in Bezug auf Cloud-Preise und Zeitersparnis beim Onboarding neuer Mitarbeiter beim Projekt. Für eine reibungslose Teamarbeit haben wir Coding-Richtlinien eingeführt. Diese legt fest, dass jede einsatzbereite Funktion in einem Python-Modul mit Git-Verfolgung gespeichert wird und eine gemeinsame Umgebungsdatei auf dem neuesten Stand gehalten wird, um abweichende Paketversionen zu beheben.
Um nun zur Modellentwicklung zu kommen, werden wir uns auf zwei Hauptaspekte konzentrieren: die Modellauswahl und die Modellabstimmung (obwohl es noch viele weitere Schritte gibt, die berücksichtigt werden müssen, aber den Rahmen dieses Blogbeitrags sprengen würden).
Da der Fast.ai-Ansatz uns schnelle und gute Ergebnisse auf dem Puddle-100-Datensatz lieferte, haben wir uns entschlossen, diesen Anwendungsfall auch auf unserem eigenen Datensatz zu starten und einige weitere Weiterentwicklungen darauf zu implementieren. Wir möchten hier einige wichtige Herausforderungen und unsere Ergebnisse vorstellen:
- Das Nachdenken über eine sinnvolle Test-Train-Aufteilung ist wichtig, um den Ergebnissen des Modelltrainings vertrauen zu können. Wir haben uns entschieden, die Hintergründe gleichmäßig auf den Test- und Train-Split zu verteilen und haben außerdem eine Funktion (wie den Blocking-Faktor aus dem MLR-Paket) angewendet, die die aus einem Video extrahierten Bilder gleichmäßig verteilt.
- Bei Verlustfunktionen für Segmentierungsaufgaben empfiehlt sich die Verwendung von Focal Loss und Dice Loss (als informative Lektüre: How to segment buildings on drone imagery … ). Sehr interessant war, dass die Verwendung der beiden bekanntesten Verlustfunktionen – nämlich Cross Entropy Loss und Binary Entropy Loss – uns ein verstreutes Ergebnis lieferte (d.h. die Pfütze wurde zwar erkannt, aber nicht in einer zusammenhängenden Form).
- Die richtige Wahl der Metriken ist entscheidend, wenn es um die Auswertung geht. Wir haben verschiedene Metrikfunktionen definiert, wie dice_iou, accuracy, recall, negative_predicted_value, specificity und f1_score. Alle Metriken sind auf Pixel- und auf Bildbasis implementiert, z.B. ein Anteil der erkannten Pfützenpixel, die tatsächlich Pfützen waren, vs. ein Anteil der vorhergesagten Pfützenbilder, die tatsächlich Pfützenbilder waren. Für uns war es am sinnvollsten, die dice_iou-Metrik genauer unter die Lupe zu nehmen.
- Zusätzlich zur numerischen Messung fanden wir es hilfreich, eine weniger automatisierte, aber angepasste Validierungsfunktion zu haben. Hier haben wir festgestellt, dass ein Vergleich von Ground Truth und vorhergesagten Masken, gruppiert nach Metadaten (z.B. Hintergrund, industriell oder nicht, verschüttet oder nicht) besonders nützlich sein kann, um die Leistung unseres Trainings zu klassifizieren.
Eines unserer größten Learnings aus der Arbeit mit dem fast.ai-Paket war, dass es ein einfach zu bedienender Out-of-the-Box-Ansatz ist, aber wenn es um Anpassungen und Modifikationen geht, kann es ziemlich schnell kompliziert werden.

Funktion für den Gruppenhintergrund ‚Halle‘ ausgegeben wurde (linkes Feld: gekleidete Wahrheit, rechtes Feld: Vorhersage
Als wir bereit waren, das Modell zu trainieren, mussten wichtige Entscheidungen über die Modellarchitektur getroffen werden. Wir spielten mit verschiedenen Einstellungen herum, entschieden uns aber schnell für eine U-Net-Architektur, die gut auf dem vortrainierten Encoder resnet18 aufbaut. U-Nets wurden in den letzten Jahren für Bildsegmentierungsaufgaben bekannt. Die Idee stammt aus dem Paper „U-Net: Convolutional Networks for Biomedical Image Segmentation“ von Olaf Ronneberger, Philipp Fischer und Thomas Brox aus dem Jahr 2015. Kurz zusammengefasst besteht die Idee dieser Architektur darin, eine Downsampling-Routine auf dem Eingangsbild durchzuführen, gefolgt von einem anschließenden Upsampling zur Wiederherstellung der ursprünglichen Eingangsgröße. Dies ermöglicht die präzise Lokalisierung von Objekten auf dem Bild. Zusätzlich besteht die Architektur aus einem contracting path zur Erfassung von Kontext.
Modelltuning
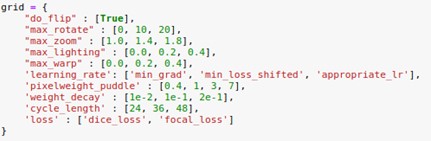
Unser nächster Schritt war die Abstimmung der Hyperparameter. Diese Aufgabe umfasst zwei Teile: das Testen der Datenerweiterung und der Modellparameter. Die größte Herausforderung war hier, einen automatisierten Weg zu finden, um den Lernratenparameter richtig einzustellen. In einigen Stichproben von Lernkurven entdeckten wir viele verschiedene Formen und einen großen Einfluss der Wahl der Lernrate auf die Vorhersagegenauigkeit. Daher haben wir drei Möglichkeiten implementiert, um eine „optimale“ Lernrate zu finden und diese als Parameter in das Tuning einbezogen:
- Minimal Gradient: Auswählen der Lernrate, die den minimalen Gradienten hat. Dieser Wert kann direkt aus der Funktion lr_find von fast.ai übernommen werden.
- Minimal Loss Shifted: Die Lernrate wird so ermittelt: Finden Sie den minimalen Wert und verschieben Sie ihn um ein Zehntel nach links. Dieser Ansatz basiert auf einer Art Faustregel, die auf Jeremy Howard (Mitbegründer von fast.ai) zurückgeht. Dieser Wert kann (mit etwas zusätzlichem Aufwand) aus der Funktion lr_find von fast.ai extrahiert werden.
- Appropriate Learning Rate: Da die zuvor genannten direkten Wege zur Ermittlung der Lernrate in manchen Fällen nicht richtig funktionieren, führen wir einen dritten Ansatz ein, der auf einer Diskussion in einem fast.ai-Forum basiert. Die Idee ist, ein Gitter zu konstruieren, das vom rechten Rand des Lernkurvendiagramms so lange nach links verschoben wird, bis eine Abbruchbedingung erfüllt ist. Dies zielt darauf ab, eine Lernrate zu erhalten, die einen minimalen Verlustgradienten hat, bevor der Verlust stark ansteigt. Beachten Sie, dass bei diesem Ansatz für jede verwendete Verlustfunktion zuvor eindeutige Schwellenwerte definiert werden müssen.
Nachdem alles eingerichtet war, führten wir eine typische Rastersuche in dem in der folgenden Abbildung dargestellten Parameterraum durch. Aus Laufzeitgründen haben wir diese Abstimmung an Bildern durchgeführt, die auf 25 % verkleinert wurden.
In jedem Schritt haben wir den Lernratenplot, den Verlustplot für Test- und Validierungsdaten, die Metrikplots (am wichtigsten für uns das dice_iou-Maß) und die Validierungsbilder gespeichert, die wir in der oben beschriebenen Funktion inspect results definiert haben. Nachdem wir das Hyperparametertraining über ein Wochenende laufen ließen, können wir mit folgenden Ergebnissen abschließen:
- Es sind keine eindeutigen „Bestwerte“ für die Parameterabstimmung erkennbar.
- Der Wert für „dice_iou“ konnte gegenüber den Standardparametern um ca. 5 % erhöht werden.
- Der „f1_score“ konnte gleichzeitig um 2% auf die Standard-Parametereinstellung angehoben werden.
- Es ist schwierig, die Ergebnisse aus verschiedenen Verlustläufen nur durch die Betrachtung der Validierungsmaße zu vergleichen. Daher haben wir auf einigen der gespeicherten Plots/Maße eine Stichprobenauswahl für die Parameter mit den höchsten Genauigkeiten durchgeführt. Dabei haben wir uns für den folgenden Hyperparametersatz entschieden (alle anderen Parameter sind auf ihren Standardwert gesetzt):
Max_rotate=0,
max_zoom=1.4,
kind_of_lr=’min_grad‘,
loss=’dice_loss‘,
cycle_length=48
Zusammenfassend lässt sich sagen, dass dieses zeitaufwändige Hyperparameter-Tuning uns nicht den gewünschten Schub in der Modellleistung gebracht hat, aber uns geholfen hat, das Modell besser zu verstehen und die Basis für ein automatisiertes Training in einer Pipeline zu schaffen. Als abschließendes Experiment für unseren Trainingsprozess haben wir ein Verfahren mit iterativem Training bei gleichzeitiger Größenänderung der Bilder implementiert. Die Idee stammt von Jeremy Howard (Mitbegründer von fast.ai) aus dem fast.ai-Kurs, der kostenlos online besucht werden kann (https://course.fast.ai/). Die Idee hinter diesem Ansatz ist, dass das Modell in den ersten Durchläufen (Modelltraining auf einer kleinen Bildgröße) das Gesamtverhalten der Segmentierungsformen lernt. So kann sich das Modell in jeder Schleife zunehmend auf die genauen Grenzen der zu erkennenden Objekte konzentrieren. In unserem Experiment haben wir mit verkleinerten Bildern von 25 % begonnen, auf 50 % skaliert und dann auf 75 %, um das Training mit den ursprünglichen Bildgrößen zu beenden. In jeder Iteration haben wir die Lernrate zweimal manuell eingestellt (jedes Mal, nachdem wir die Lernratenkurve gesehen haben). Um diesen Trainingsprozess in eine finale Pipeline überführen zu können, haben wir auch einen automatischen Lernraten-Finder implementiert, bei dem der Benutzer aus den drei oben beschriebenen Möglichkeiten der automatischen Lernratenfindung (Minimal Gradient, Minimal Loss Shifted und Appropriate Learning Rate) wählen kann. Das Ergebnis der dice_iou-Maßnahme ist das folgende:
| Bildgröße | 0.25 | 0.5 | 0.75 | 1.0 |
|---|---|---|---|---|
| Ausgewertet an verkleinerten Bildern | 53,9% | 67,9% | 78,8% | 76,8% |
| Ausgewertet an Bildern in Originalgröße | 22,6% | 55,6% | 73,2% | 76,8% |
Diese Steigerung der Genauigkeit ist auch in den Validierungsbildern zu erkennen. Daher scheint dieses Verfahren in unserem Aufbau sehr nützlich zu sein.
Zusammenfassung und Ausblick
Für uns als Data Scientists steht im Hintergrund immer eine Frage im Raum: Wie kann man messen, ob ein Modell gut ist? Was sagt uns der Genauigkeitswert wirklich? Schauen wir auf die richtigen Dinge? Natürlich zeigt uns eine Genauigkeit von 77 % auf unserem Validierungsset, dass das Modell etwas lernt. Aber ist das genug? An dieser Stelle ist es gut, zu unserer anfänglichen Motivation und der realen Anwendung zurückzukehren, für die unser Modell verwendet werden soll: das Erkennen von Pfützen auf dem Boden mithilfe von Unterstützungsrobotern in der Pflege und im industriellen Kontext. Die Pfütze muss erkannt werden und die Grenzen der Gesamtform sollten klar sein, aber es ist nicht notwendig, dass die Form zu 100 % korrekt erkannt wird, wie es bei einer Aufgabe wie dem Greifen eines Objekts durch einen Roboter der Fall wäre. Als Zwischenimplementierung könnte der Roboter anhalten und einen Alarm senden, wenn er eine Pfütze erkennt. Klar ist, dass in unserem Anwendungsfall ein falsches Positiv (Erkennen einer Pfütze, wenn keine vorhanden ist) weniger fatal ist, als die Pfütze nicht zu erkennen und die unerwünschte Flüssigkeit noch weiterzuverteilen.
Bei der Bewertung der Frage, ob unser Modell „gut“ arbeitet, war eine Antwort für uns, einige Bilder gezielt auf geschickte Weise herauszusuchen. Zum einen haben wir uns die Bilder nach unseren gesammelten Metadaten gruppiert angeschaut und zum anderen fanden wir es hilfreich, die Bilder wieder mit den Originalvideos zusammenzuführen, um das Vorhersageverhalten beim Abspielen des Videos zu sehen. Wir möchten es dem Leser überlassen, über einen solchen Output zu urteilen:

By loading the video you accept YouTube’s privacy policy.
Learn more
Zusammenfassend können wir sagen, dass die ersten Ergebnisse für unseren Anwendungsfall sehr vielversprechend aussehen. Pfützen werden in den meisten Fällen erkannt und in den Videos lässt sich ein nachvollziehbarer Trend erkennen. Natürlich gibt es – wie immer – Verbesserungsmöglichkeiten, die in Zukunft angegangen werden können. Unsere nächsten Schritte sind das Testen des Modells an zusätzlichen Daten (die derzeit aufgezeichnet werden) und das Testen, wie gut unser Modell verallgemeinert werden kann, und anschließend die Implementierung des Modells in das Robotersystem und Tests in der realen Welt.





0 Kommentare