
Im Jahr 2022 feiern wir das 10-jährige Jubiläum von [at] – Alexander Thamm.
2012 waren wir die erste Beratung im deutschsprachigen Raum, die sich Data & AI auf die Fahne geschrieben hat. Heute lässt sich sagen, künstliche Intelligenz (KI) hat das Potential, einen wichtigen Beitrag bei einigen der großen wirtschaftlichen und gesellschaftlichen Herausforderungen unserer Zeit zu leisten. KI spielt eine Rolle bei der Energiewende und bei der Reaktion auf den Klimawandel, beim autonomen Fahren, bei der Erkennung und Behandlung von Krankheiten oder der Pandemiebekämpfung. KI steigert die Effizienz von Produktionsprozessen und erhöht die Anpassungsfähigkeit von Unternehmen auf Marktveränderungen durch Echtzeitinformationen sowie Vorhersagen.
Die wirtschaftliche Bedeutung der Technologie steigt rasant an. Mittlerweile nutzen mehr als zwei Drittel der deutschen Unternehmen künstliche Intelligenz und Machine Learning (ML).
Mit unseren #AITOP10 zeigen wir euch, was gerade im Bereich Data & AI angesagt ist. Unsere TOP10-Listen präsentieren Podcast-Highlights, industriespezifische KI-Trends, KI-Experten, Tool-Empfehlung und vieles mehr. Hier bekommt ihr einen breiten Querschnitt über das Data & AI-Universum, das uns seit nunmehr 10 Jahren antreibt.
Inhaltsverzeichnis
Unsere Top 10 ML-Algorithmen – Teil II
Recommender, Clustering, Regression, Text Analytics, Anomaly Detection… Machine Learning kann heute für vielfältige Problemstellungen eingesetzt werden und ist dabei schneller und genauer denn je. Aber was hat es mit den Algorithmen dahinter auf sich? Wir schauen hinter die Kulissen und zeigen euch, welche Algorithmen beim Machine Learning wirklich zum Einsatz kommen.
Platz 5 – k-nearest neighbors
Stell dir vor, du suchst nach einem Job. Deine 3 besten Freunde stehen um dich herum und beraten dich, ob du Data Strategist oder Data Scientist werden solltest. Welchen Konsens gäbe es bei den dreien? Und welchen, bei deinen 5, 10 oder gar 20 besten Freunden?
K-NN löst dieses Problem ganz simpel: Derjenige, der am nächsten dran ist, gewinnt. Stehst du also direkt neben einem Data Strategisten, bist du jetzt auch einer. Nun kann es aber sein, dass dieser eine Data Strategist dich unbedingt überzeugen möchte, auch einer zu werden, weil rundherum nur Data Scientisten stehen. Hier naht das “k” zur Rettung: Das k bestimmt, wie viele deiner Freunde, die am nächsten an dir dran stehen, miteinbezogen werden. Bei k=3 stimmen deine 3 nächsten Freunde ab – ganz demokratisch. Nun kann es sein, dass der Data Strategist ganz alleine dasteht und überstimmt wird. So funktioniert die Vorhersage von k-NN.
K-NN ist ein Algorithmus zum Clustern von Daten. Das Ziel ist, einen Wert, der nicht bekannt ist, einer bestimmten Kategorie zuzuordnen. Das geschieht ganz demokratisch: Man stellt alle Datenpunkte beispielweise auf einer zweidimensionalen Fläche dar. Die Daten sind bereits in Kategorien eingeteilt. Nun möchte ich aber erfahren, zu welcher Kategorie einer neuer Datenpunkt gehört. Hier kommt das k ins Spiel. Der Datenpunkt wird auf der Fläche dargestellt und es werden die Kategorien der k nächsten Nachbarn betrachtet. Anschließend wird abgestimmt: Die meisten Nachbarn mit der gleichen Kategorie gewinnen.
K-NN lässt sich in der realen Welt vor allem gut zur Erkennung von Ausreißern nutzen. Das hilft sowohl in der Finanzbranche bei der Bekämpfung von Kreditkartenbetrug als auch in der Überwachung von Computersystem oder Sensornetzwerken. Weiterführend kann k-NN zur Vorverarbeitung und Bereinigung von Daten verwendet werden, wenn anschließend weitere ML-Algorithmen auf einen Datensatz angewendet werden sollen.
Platz 4 – Boosting
Boosting-Algorithmen halten für Data Scientists so einige Lebensweisheiten bereit. Dabei handelt es sich beim Boosting um einen relativ generischen Algorithmus, der in Kombination mit verschiedenen Algorithmen angewendet werden kann. Dabei konstruiert ein Boosting-Algorithmus aus mehreren schwachen ML-Modellen ein einzelnes starkes ML-Modell. Aber wie?
Verbunden werden auch die Schwachen mächtig.
Friedrich Schiller in Wilhelm Tell
Wir lernen schon früh im Leben, dass wir gemeinsam stärker und schlauer sind als allein. Den schweren Küchentisch zu verschieben ist alleine fast unmöglich, zu zwei schwierig und zu viert gar kein Problem. Genau dieses Konzept machen sich Boosting-Algorithmen zunutze. Es werden unterschiedliche Modelle trainiert, die zwar einzeln einen hohe Fehlerrate und schlechte Vorhersagegenauigkeit haben, zusammen aber eine deutlich bessere. Wer Teil 1 unserer ML-Algorithmen Serie verfolgt hat, der hat eventuell ein Deja-Vu: Random Forests. Aber wo liegt der Unterschied?
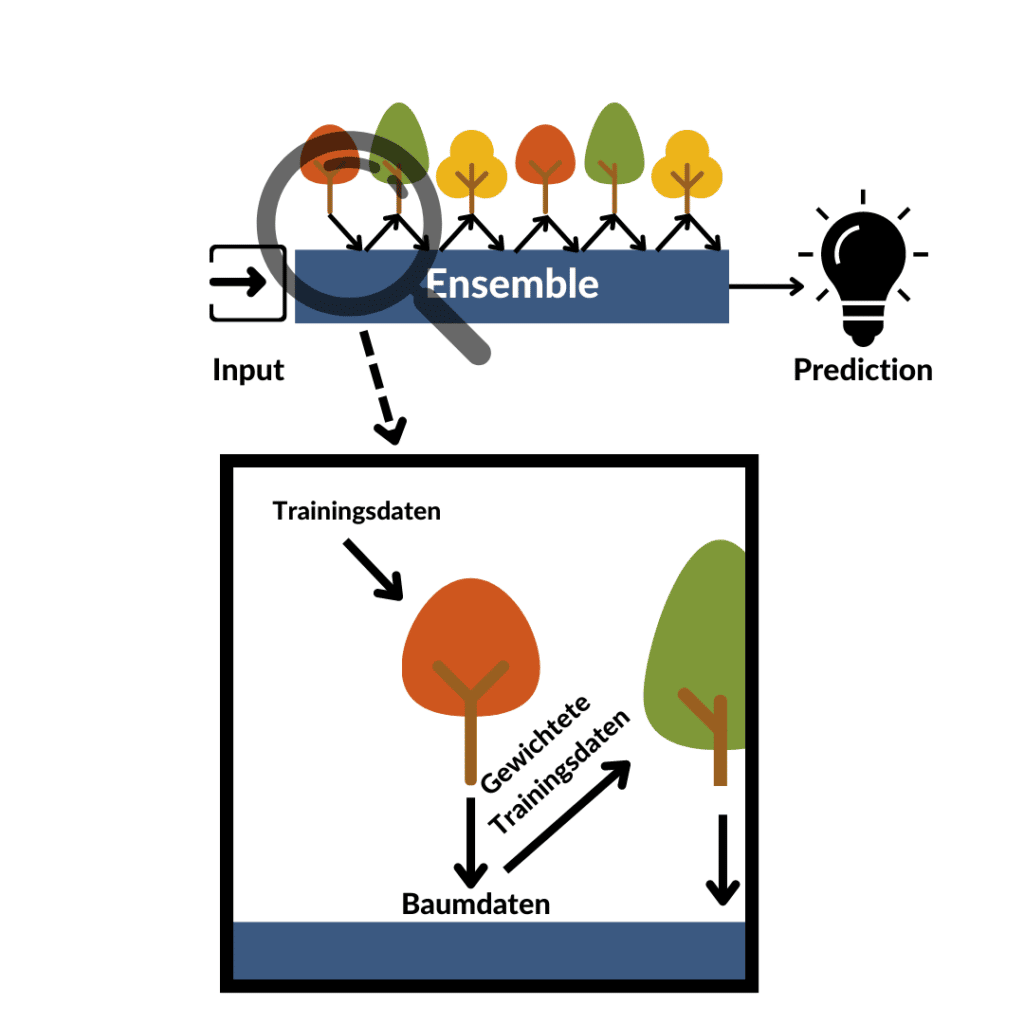
Boosting-Algorithmen machen sich ein weiteres sehr bekanntes Konzept zu Nutze: Lernen aus den Schwächen anderer. Hat eine:r meiner Komilliton:innen die Statistik-Klausur vor mir geschrieben und bei der linearen Regression kläglich versagt, wird er oder sie mir dazu raten, mich vor allem damit zu beschäftigen. Natürlich übt man vor der Klausur jetzt verstärkt die lineare Regression, die anderen Klausurthemen werden aber nicht außer Acht gelassen. So funktioniert Boosting – lerne aus der Vergangenheit und nutze dafür ein ganzes Ensemble aus Modellen.
Verbunden werden diese beiden Techniken durch Iteration: Das erste Modell lernt, wird im Hinblick auf die Vorhersagegenauigkeit getestet und abgespeichert. Schwächen bei der Vorhersage des Modells werden identifiziert, die zugehörigen Daten etwas mehr gewichtet und das nächste Modell wird trainiert. Alle Modelle werden in einem Ensemble gespeichert und treffen somit am Ende zusammen die Vorhersage. Bei der Ermittlung der Schwäche bzw. falsch klassifizierten Datenpunkte gibt es bei Boosting-Algorithmen verschiedene Versionen: Bei AdaBoost wird dafür die Fehlerrate genutzt, beim Gradient Boosting der Abstand des vorhergesagten Punktes zum wahren Wert.
Eine Implementation von Boosting-Algorithmen ist beispielsweise das XGBoost-Framework. Mithilfe von Regressionsbäumen, der Minimierung der Verlustfunktion durch Extreme Gradient Boosting, Parallel-Processing und Regularisierungsparametern ist XGBoost schneller und genauer als AdaBoost oder Random Forest.
Platz 3 – Naive Bayes
Spam-Mails nerven. Umso mehr, wenn sie nicht im Spam-Order, sondern im normalen Postfach landen. So könnten sie mitunter viel Schaden anrichten und ganze Intranets lahmlegen. Deshalb nehmen wir uns dieses Problems nun an – mit Naive Bayes.
Der Algorithmus macht es sich zunächst leicht: Um ein ML-Modell mit Naive Bayes zu trainieren, werden zunächst alle bereits im Spam-Ordner vorhandenen Mails in Wörter unterteilt. Die Häufigkeit der vorhandenen Wörter wird anschließend ermittelt. Zum Beispiel: Wie oft kommt das Wort “Spam” in einer Spam-Mail vor? Wie oft kommt das Wort “Hallo” in einer normalen Mail vor?
Das Gröbste haben wir nun schon hinter uns. Jetzt können wir anhand einer neuen Mail entscheiden, ob diese wahrscheinlich eine Spam-Mail ist oder nicht. Aber wie? Mithilfe des Satz von Bayes! Dieser besagt: Wie groß die Wahrscheinlichkeit ist, dass A eintritt, wenn B schon eingetreten ist. Anders gesagt, wie groß die Wahrscheinlichkeit ist, dass die E-Mail Spam ist, wenn ein bestimmtes Wort darin vorkommt.
Wer aufmerksam mitgelesen hat, wird festgestellt haben, das Wort “Spam” – das wir vorher gezählt haben – wird wohl kaum in einer Spam-Mail stehen. Die Wahrscheinlichkeit dafür wird also 0 betragen. Wer bei der Wahrscheinlichkeitsrechnung in der Schule gut zugehört hat weiß: Wahrscheinlichkeiten werden miteinander multipliziert. 0 * 100% sind aber immer noch 0 … wie jetzt?
Um das zu vermeiden, addieren wir zu jedem Wort, was wir gezählt haben ein imaginäres Wort dazu. Das bedeutet, unser Wort “Spam” wurde nun nicht 0-mal gezählt, sondern 1 Mal. So lässt sich mit Naive Bayes voraussagen, ob unsere E-Mail Spam ist oder nicht.
Ein klassischer Use Case für Naive Bayes ist die Dokumentenklassifikation. Ein Naive Bayes Classifier kann bestimmen, ob ein Dokument eher der einen oder der anderen Kategorie angehört. Hierzu zählt auch die Identifizierung von Spam. Weiter können Sprache oder Text auf Stimmung analysiert werden (werden hier positive oder negative Emotionen ausgedrückt?). Naive Bayes stellt eine Alternative zu vielen, komplizierteren Algorithmen dar, gerade wenn die Menge an Trainingsdaten vergleichsweise gering ist.
Platz 2 – Support Vector Machines

Wer schon mal auf einer Landstraße unterwegs war, hat mit annähend hundertprozentiger Sicherheit dort mal einen Baum gesehen. Meist sogar mehrere – einen sogenannten Wald. Diese Bäume stehen oft schon länger da, als die Straße, auf der man fährt. Falls diese aber direkt am Wegesrand wachsen, kommt es schonmal vor, dass sich Wurzeln unter den Asphalt verirren und nervige Huckel oder Straßenschäden entstehen. Das möchten wir verhindern. Aber wie?
Landstraßen führen oft an Wäldern vorbei oder durch Wälder hindurch. Um zwei kleine Dörfer zu verbinden, möchten wir eine Straße zwischen einem Misch- und einem Nadelwald bauen. Dabei helfen uns Support Vector Machines. Um den Asphalt noch Jahre später befahren zu können und die Ruhe der Wälder zu bewahren, ist es nötig, die Straße möglichst weit weg von beiden Wäldern zu bauen. Support Vector Machines machen genau das möglich: Sie ermitteln eine Linie, die zwei Klassen von Daten (Misch- und Tannenwald) optimal separieren. Doch was bedeutet hier optimal?
Optimal bedeutet, die beiden Klassen möglich weit voneinander zu separieren. Das hat einen ganz praktischen Vorteil: Vergrößert sich einer der Wälder, wachsen die jungen Ausläufer nicht zu nah an der Straße und der Asphalt bleibt noch Jahre später frei von Straßenschäden. Ermittelt wird diese optimale Trennlinie durch Vektoren. Das hört sich zwar mathematisch an, ist aber gar nicht so kompliziert.
Wir führen rechts und links von der Straße Korridore ein, die parallel zur Straße verlaufen. Anschließen verbreitern wir diese, bis sie an den nächsten Baum treffen. Nun kann es sein, dass wir uns beim Planen verschätzt haben und den Korridor noch verbreitern könnten, wenn die Straße eine andere Richtung nimmt. Dazu messen wir orthogonal den Vektor vom Korridor zum zweitnächsten Punkt. Können wir diesen noch weiter minimieren, besteht Verbesserungsbedarf. Liegt der Korridor an 2 Punkten an, ist unsere Straße optimal geplant.
Sprießt nun ein neuer Baum aus dem Boden (ähnlich einer Vorhersage) kann aufgrund des Korridors ziemlich genau gesagt werden, zu welcher Klasse der Punkt bzw. zu welchem Wald der Baum gehört. Umso breiter der Korridor, umso vielversprechender die Vorhersage.
In unserem Bespiel haben wir uns eine zweidimensionale Fläche angeschaut. Support Vector Machines können das Gleiche jedoch sogar in einem drei-dimensionalen Feld. Liegen die Punkte nicht wie hier in 2 Klassen nebeneinander, sondern wird eine von der anderen eingekesselt, kann eine weitere Dimension mit einer Transferfunktion hinzugefügt werden. So lassen sich die Punkte wieder mit einer linearen Linie unterteilen.
Anwendung finden Support Vector Machines in nahezu allen Bereichen: Zur Gesichtserkennung kann die Grenze zwischen Hintergrund und Körper gezogen werden, bei der Handschrifterkennung dient der Algorithmus zu Zeichenerkennung oder hilft bei der Klassifizierung von Artikel in verschiedene Kategorien. Der Algorithmus erfordert nur kurze Trainingszeiten und ist daher für manche Probleme eleganter und besser geeignet als ein aufwendig zu trainierendes künstliches neuronales Netz.
Platz 1 – Artificial Neural Networks
Ein künstliches neuronales Netz ist die “Königsklasse” der ML-Algorithmen. Es benötigt viel Rechenpower und hat teilweise lange Trainingszeiten. Dafür kann es aber komplexe Probleme in nahezu allen Bereichen lösen. Beispielweise Bild- und Videoerkennung mit ImageNet, NLP mit GPT-3 (und bald OpenGPT-X), oder Bilderstellung mit DALL:E 2 sind bekannte Aufgaben, die mit künstlichen neuronalen Netzen bewältigt werden. Der Haken an der Sache: künstliches neuronale Netze sind unglaublich kompliziert zu durchblicken und verstehen.
Das Vorbild von künstlichen neuronalen Netzen ist das menschliche Gehirn. Daher ähneln sich die die Funktionsprinzipien dieser beiden Systeme. Da wir aber (leider) keine Neurowissenschaftler sind, bringt uns diese Metapher nicht wirklich näher zum Verständnis künstlicher neuronaler Netze. Also ein etwas realitätsnäheres Beispiel, das selbstfahrende Auto.
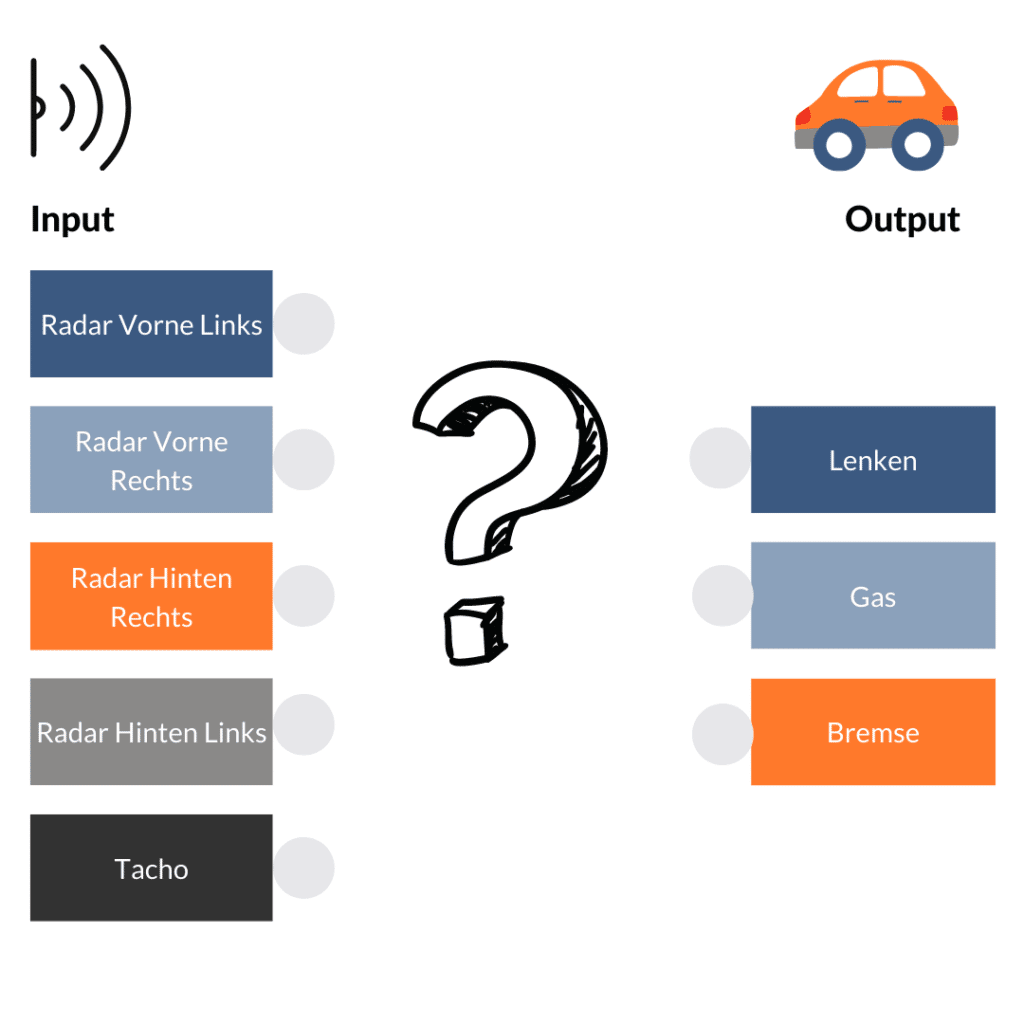
Die heute von verschiedenen Automobilherstellern entwickelten Autos nutzen diverse Technologien wie Kameras, LIDAR Technologie und Näherungssensoren. Natürlich wissen wir alle, wie man Auto fährt, ein künstliches neuronales Netz weiß das jedoch nicht. Wir nutzen als Eingänge also vier Radarsensoren (vorne links/rechts, hinten links/rechts) und messen die Geschwindigkeit des Fahrzeugs. Unsere Möglichkeiten das Fahrzeug zu steuern, also die Ausgänge beschränken sich auf Gas, Bremse und Lenken. Und wie verkabeln wir das Ganze?
Ganz einfach: Alles mit jedem. Jeder Input und jeder Output stellt dabei ein Neuron dar. Das bedeutet aber leider auch, dass ein Signal vom hinteren Radarsensor die Bremse triggern würde oder ein Signal vom vorderen Radar das Gas. So wird unser Auto vorerst nicht in Fahrt kommen. Nun kommt aber der Clou und Grund, warum künstliche neuronale Netze so schwer zu durchblicken sind. Bislang besteht unser künstliches neuronales Netz aus 2 Schichten: Input und Output. Dazwischen fügen wir jetzt aber eine Schicht weiterer Neuronen ein, ein sogenanntes “hidden layer”. Dieses ist mit der Input- und Output-Schicht kreuz und quer verbunden. Durch verschiedene Rechenoperationen kann es die Eingangssignale addieren, umkehren, aggregieren oder auch subtrahieren. Dadurch verändert sich der Signalfluss je nach Eingang. Aber kann unser Auto dadurch schon fahren? Leider immer noch nicht.
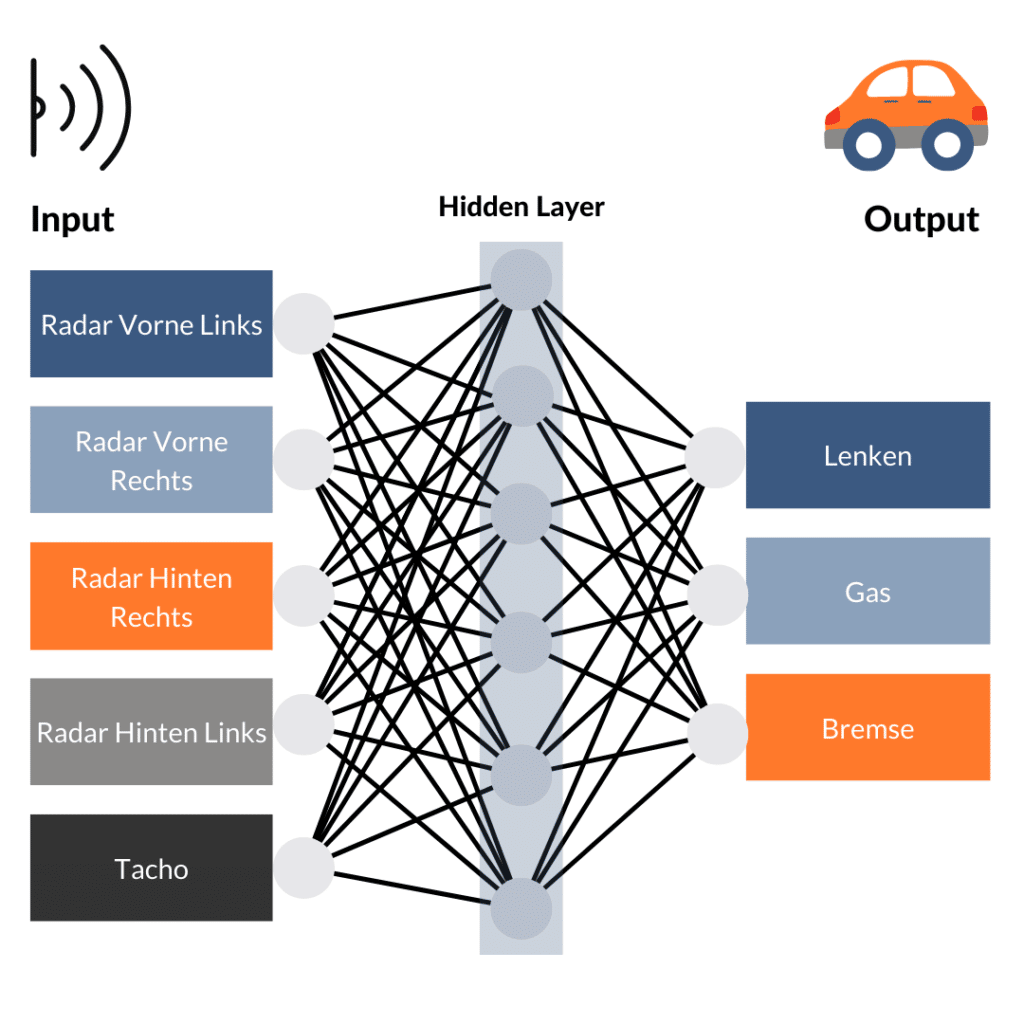
Nun wird dieses Modell trainiert. Bei diesem Prozess versucht es, durch Trial-and-Error beim vorgegebenen Input auf den richtigen Output, also die richtige Reaktion, zu kommen. Mithilfe von Trainingsdaten wird das Modell trainiert und findet dabei heraus, welche Verbindungen bei bestimmter Transformation in dem “hidden layer” zum richtigen Ergebnis führen. Ist der Output falsch, werden die Funktionen der Neuronen verändert und es wird erneut trainiert. Hat es eine gewisse Genauigkeit erreicht, kann es mit unbekannten Daten getestet werden und bei Bestehen im selbstfahrenden Auto implementiert werden.
In der Realität haben künstliche neuronale Netze mehrere Layer. Auch der Input ist unterschiedlich: Mal sind es Zahlen, aber auch Wörter oder auch Bilder bzw. Videos. Als Output haben komplizierte Modelle wie beispielweise DALL:E 2 gleich ein ganzes Bild, also sehr viele einzelne Werte. Bei anderen Modellen geht es nur um die Erkennung einer handgeschriebenen Zahl – also genau einen Output. Genau diese Vielseitigkeit machen künstliche neuronale Netze aber aus. Sie können die unterschiedlichsten Probleme in nahezu jeder Branche lösen, egal um welche Datentypen es sich handelt. Lediglich die Menge an Trainingsdaten und die verfügbare Rechenpower muss vergleichsweise relativ groß sein, um effektive künstliche neuronale Netze zu trainieren.
Künstliche neuronale Netze werden von nahezu allen Tech-Konzernen genutzt – wie Google, Facebook, Apple, Netflix Amazon, Microsoft – und können für die verschiedensten Zwecke genutzt werden: Zur Generierung von User-Insights, Text-Analyse, Recommender-Systeme, Entdeckung von Medikamenten oder auch für bahnbrechende wissenschaftliche Erkenntnisse wie bspw. AlphaFold von Deepmind.
Teste neuronale Netzwerke selbst
Das sind unsere Top 10 ML Algorithmen. Falls du Part I verpasst hast, lies hier nochmal nach und erfahre, was Bäume und Machine Learning außerdem gemeinsam haben.









0 Kommentare