Inhaltsverzeichnis
[at] trains its own data and AI experts
For several years, [at] has been training data scientists and data engineers itself through a trainee programme. During the one-year programme, the trainees rotate through several [at] teams to work on different projects and thus build up expertise in various fields.
As a novelty, the data.camp was introduced in 2020 - a four-day workshop in which all trainees work together on a joint project of their choice. The aim is to promote teamwork and gain practical experience.
In order not to be distracted by day-to-day business, the data.camp usually takes place in the [at] project rooms in Austria. Due to the Corona pandemic, the first data.camp in October 2020 had to take place in the Munich office. However, the team was able to use the new [at] office space (in the same building) to at least have a kind of 'camp' feeling.
Here you can find more information about the trainee programmes for Data Scientists and Data Engineers.

Topic of the first data.camp: automated googling
The theme of the first data.camp was based on an ongoing [at] customer project. We chose the topic of automated googling because it covers three core areas: analytics, engineering and visualisation. The original project setting was as follows:
Whenever employees of an [at] customer needed a supplier for a specific requirement, they sent their requests to supplier management. There, another employee searched the internet for a suitable supplier - for example, a request about AI training. The task for [at] was to automate this process.
At the beginning, the [at] colleagues had already developed an algorithm whose input was a demand text and whose output was a list of possible suppliers (see below). The algorithm first extracted key phrases from the demand text and created search queries from them. These search queries were sent to Google to get a list of potential companies. To ensure that these were indeed businesses, they were matched against the Crunchbase business database. From all verified businesses, a description was retrieved from the web (again, a Google search), which was then compared to the original query text (using natural language processing). Finally, the algorithm returned all companies whose descriptions were sufficiently similar to the request text.
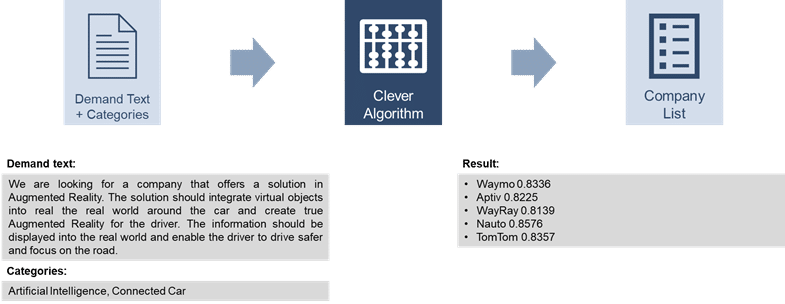
Project setting: Naturally agile
As data projects are constantly changing with new developments, we used Scrum as a framework to work in an agile way.
We appointed a Scrum Master, a Product Owner and five developers. Every day we had several Scrum meetings to coordinate. This made the data.camp a good opportunity to try out Scrum and all its concepts.
Behind the scenes, experienced [at] colleagues were available as a resource for our questions. This allowed us to move forward very quickly and develop professional solutions.

Learning progress in the areas of analytics, engineering and visualisation
Anyone who has ever taken part in a hackathon might know how much you can achieve in just a few days. That was our approach:
In one workstream, we improved the algorithm's natural language processing capabilities. Since the query texts were usually about technologies, we taught the algorithm examples of words we were interested in (e.g. "augmented reality" or "machine learning"). This allowed us to create better queries from the demand texts.
The runtime of the entire algorithm was around 30 minutes at the beginning. As this not only leads to a poor customer experience, but also makes development much more difficult (imagine waiting 30 minutes every time you want to try something), another workstream aimed to reduce the runtime. We increased compute power by moving the project to the cloud, and downloaded the Crunchbase database (for enterprise verification) to use locally instead of making API calls for each verification. Both of these measures reduced the runtime to just 2.5 minutes.

© [at] 
© [at]
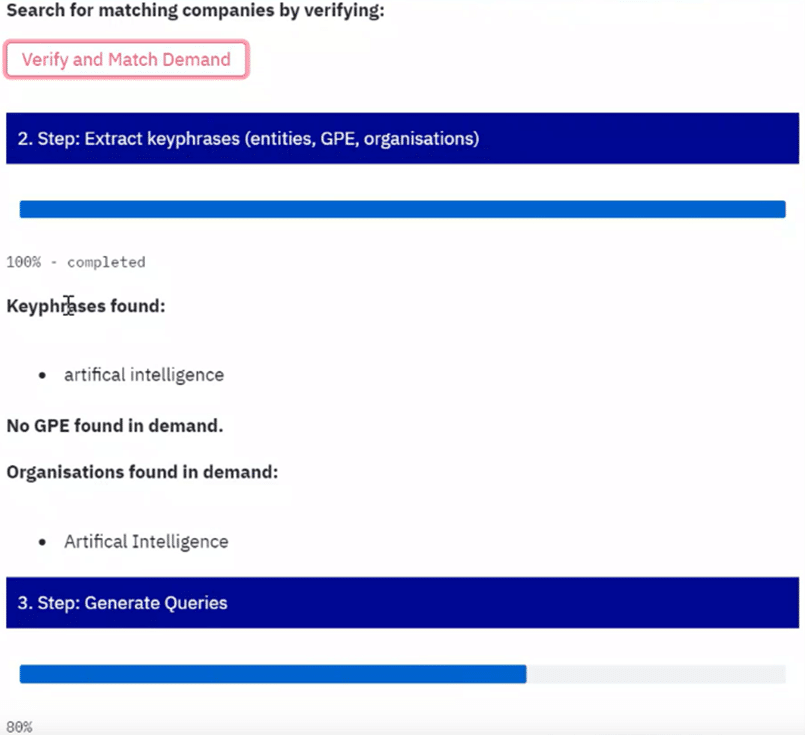
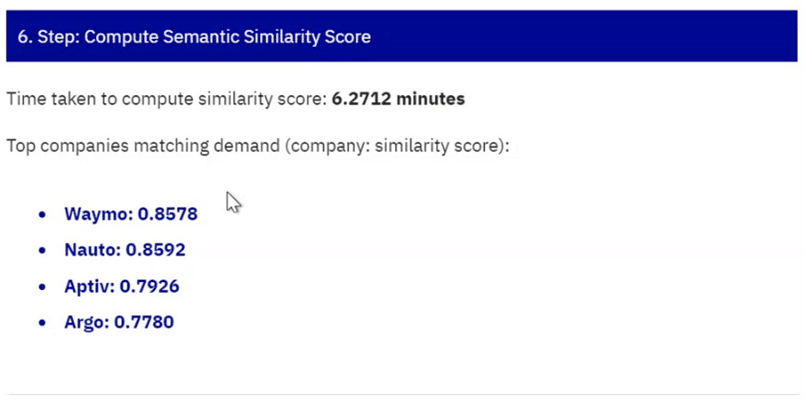
Generally, there is a lot going on behind the scenes of a machine learning service - just think of all the steps in our algorithm to convert a simple query text into a company list. While it can be very convenient for the end user that all this complexity is hidden, some may need to understand how the final result was retrieved. Therefore, in the last workstream, all intermediate results were output and displayed in an app in real time.
Summary and Take-Aways
"We learned a lot and had a lot of fun in the process" is a very good summary of the first data.camp. In addition to the technical learning in analytics, engineering and visualisation, we gained very valuable experience in working with Scrum. Furthermore, this kind of cooperation has strengthened the team spirit of the trainees, which we will benefit from long after this data.camp.

Our trainees from October 20
Daniel, Louis, Thanos, Simon, Sebastian, Julian, Luca (at the laptop screen)



0 Kommentare