
Big Data has long since emerged from the famous Hype cycle from Gartner disappeared and is perhaps no longer one of the most popular buzzwords. Nevertheless, it is still one of the most important topics in data science projects. This makes it all the more important to keep asking about current technologies, the opportunities and the success and risk factors. According to Bitkom, the majority of German companies now prioritise the topic of Big Data and rank it alongside Robotics and the Internet of Things as important for their competitiveness.
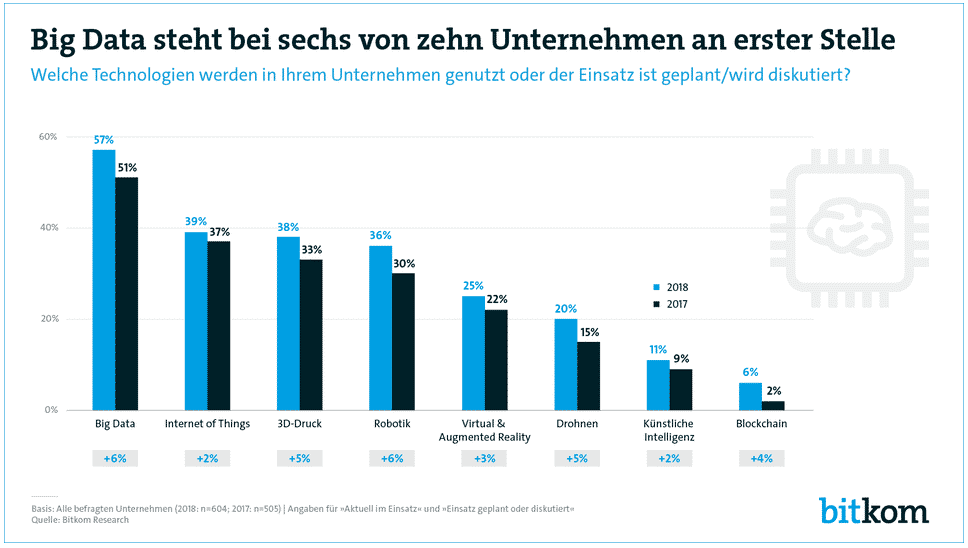
In our Machine Learning Studywhich we conducted together with Computerwoche, we came to a similar conclusion. In our survey, in which multiple responses were also possible, Big Data came in 5th place.
Inhaltsverzeichnis
What is Big Data?
One of the simplest definitions is: Big Data are All data larger than an Excel spreadsheet - i.e. more than 1,048,576 rows and 16,384 columns. In recent years, it has become common to speak of the various "V's" that define Big Data. V stands for Velocity, Variety, Volume, Value, Veracity or Visualisation, for example. The number of Vs increased continuously from 4, 5, 6 to 10 and 12 and finally to 42. But what actually constitutes Big Data? A highly simplified definition is: Big Data means the large-scale collection, storage and analysis of data.
Many of the terms and concepts that have found their way into the definition are rather components of data projects in general. Data visualisations While Big Data analyses are an important aspect, for example in the context of the Visual Data Exploration - but also play a decisive role in data projects without Big Data. In this respect, all attempts at definition must be viewed with a certain degree of caution.
The characteristic features
However, some other characteristics clearly serve to differentiate Big Data. For example, the individual data set plays a subordinate role in Big Data. Rather, it is about Patterns and structures that can be found in the data are. Big Data usually also consists of different types of data and unstructured data. In our view, the four essential characteristic features are as follows:
- The Data volumeAs the word suggests, it is initially a "large" amount of data ("volume"). Since data represent a small section of reality, the following generally applies: the more data available, the more complete the picture of reality that we can form with it.
- The Data varietyIn most cases, big data consists of very different types of data and extremely complex data sets ("variety") - this makes connections and patterns recognisable. The challenge is therefore often to bring the data into a meaningful relationship with each other.
- The Processing speedIn addition to the amount and variety of data, the rapid availability of results is becoming increasingly important. With a corresponding processing speed ("velocity"), which is guaranteed by many hundreds of processors working in parallel, results are sometimes available in real time. If only conventional computers were at work, it would take days or even weeks until the results of analyses were available. The findings would then be largely useless.
- Data must variable be: Data is generated extremely quickly in some cases - the turbine of a wind power plant or an aircraft monitored by sensors delivers up to 15 terabytes of raw and sensor data per hour. However, the relevance of the information that can be derived from this data deteriorates over time ("variability"). Data must therefore be variable or collected again and again in order to remain relevant.
Big Data in data projects
At the end of the day, data has to be interpreted and translated into be translated into meaningful concepts for action. An appealing, clear and comprehension-promoting data visualisationg is a key success factor for the Data Science Projects quite generally. The interplay of the various sub-aspects is also important: how the data is combined, evaluated and visualised. Precisely because the individual data set plays a subordinate role, visualisation is important. But visualisations are more important for another reason.
The decision as to which action follows from the result of data analyses is not usually made by the data scientist. That is why data must be presented in a form that is comprehensible to the decision-makers. Only then is there a time and knowledge advantage that results in a scope for action: The operator knows at an early stage about an impending loss and can take countermeasures even before the actual failure.
Different perspective
In practice, theoretical attempts at definition play a subordinate role. Much more important is the question of who deals with Big Data. When it comes to generating added value from data, the Data Skills and Data Roles decisive. For the Data Engineer only certain, individual aspects are interesting - but he must master these so that the data are ready for analysis. Above all, data quality is the focus of interest here.
For a Data Scientist Big Data is an important subject of his work. He examines large amounts of data with Methods from mathematics, statistics and computer science towards a specific question. The goal is usually to obtain a result at the end of the analysis that is followed by a recommendation for action. This can either run automatically or be a basis for business decisions. From the perspective of decision-makers such as the CTO is again viewed more from a cost-benefit calculation.
Last but not least, there is also a data protection perspective. Although the new GDPR does not recognise the term, certain projects are nevertheless affected by it. The decisive question here is whether only machine data or also personal data is processed. Closely linked to the topic of data protection is data security. Overall, these aspects fall within the scope of the Data governance and are much more likely to determine the success of the project than a comprehensive definition of the term Big Data.

The success factors of Big Data projects
We were able to gather a lot of experience with the handling of Big Data in the course of more than 500 successfully implemented data projects. In the process, we were able to determine that there were essentially four factors that were responsible for the failure of Big Data projects. Conversely, this means that the success factors can also be located in these four areas.
- Data Skills: A lack of data literacy in companies.
- Data governance: A lack of distribution of responsibilities.
- Data Engineering: Underestimating the technical effort
- Data Science: Unrealistic idea of possibilities
Methods, tools and technologies
methods such as machine learning, Supervised LearningUnsupersived Learning and Deep Learning are among the most widespread and currently most important methods in analysis. The method used in a data project depends very much on the respective question. The latter is the actual focus that must not be lost sight of here. The goal of a project is always to solve a specific question and not necessarily to do something with Big Data.
In our experience, an important technical solution approach in Big Data projects is the Data Lake. Here data from all possible sources and contexts together. The data lake thus gathers data in a large quantity and variety.t available. Cloud solutions can also be an important aspect of Big Data solutions for a variety of reasons - especially when it comes to speed in the availability of data.
However, when it comes to concrete tools and technologies, an almost confusing situation has emerged in recent years. The following chart shows the multitude of Big Data solutions that have emerged in the different areas. Which technology and which tool is used in each individual case depends on various factors and ultimately on the skills and experience of the data scientists.

From buzzword to standard
The development that has taken place in recent years and is reflected in this market overview clearly shows that Big Data has long since emancipated itself from the initial hype phase. Rather, it is now a new industry standard that has become an essential component in the value chain. In view of the sometimes high financial expenditure associated with data management, it is now more important than ever to generate added value from data. We call this: Data2Value.









0 Kommentare