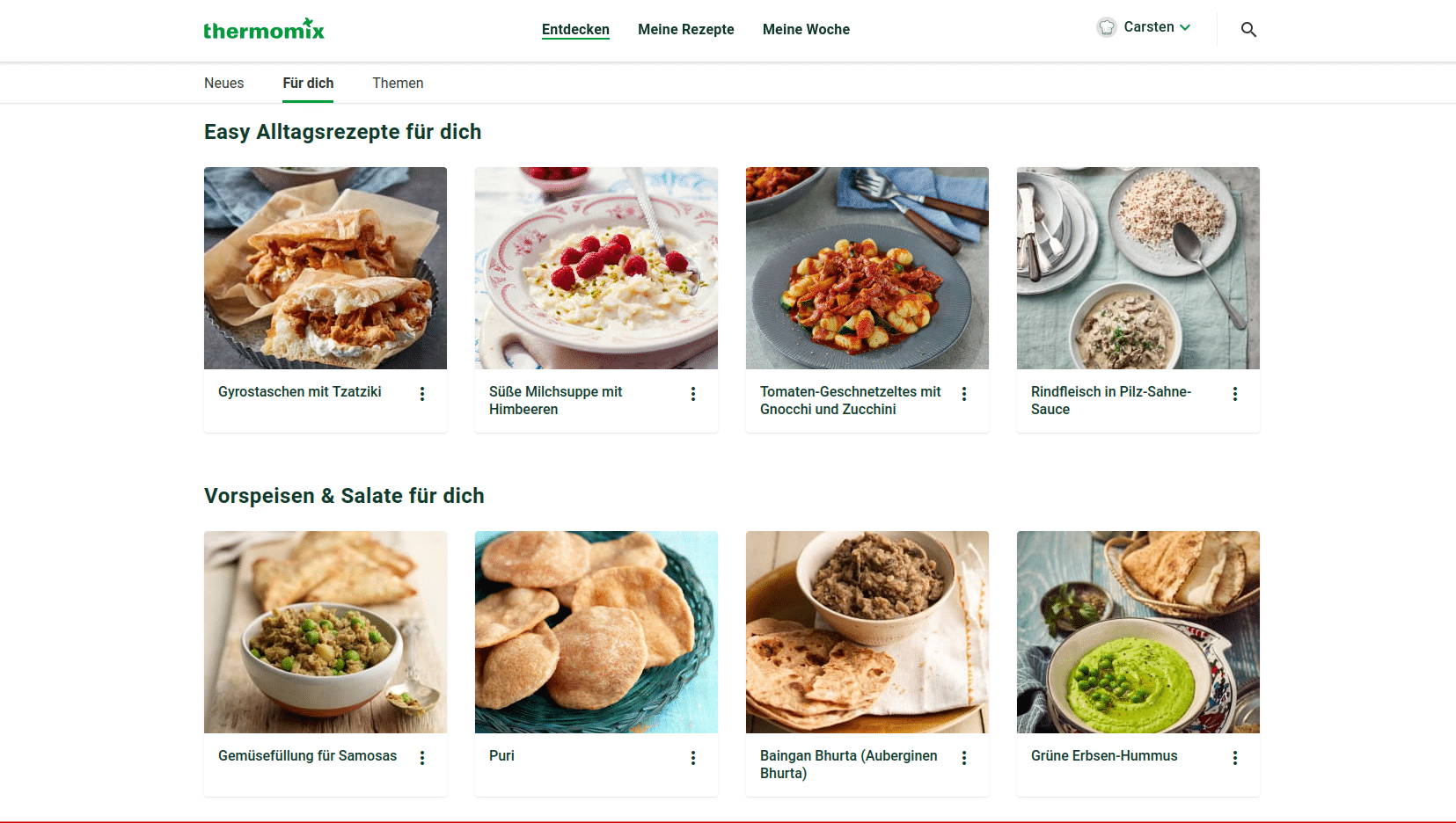
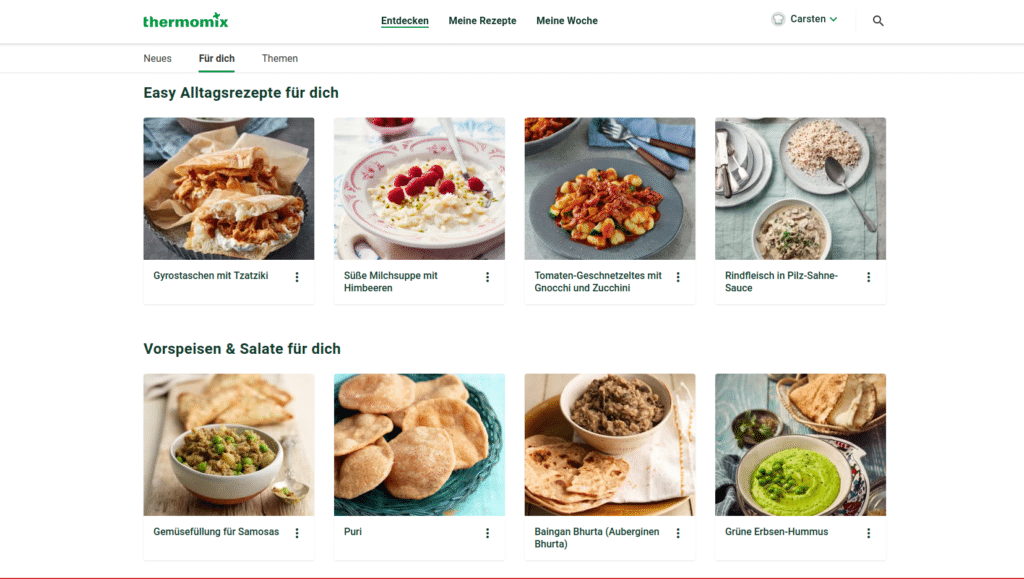
In the screenshot, you can see some of our personalized recommendations on Cookidoothe recipe platform for the smart cooking device Thermomix. In this post, I want to provide you with practical insights on building the recommender system for Cookidoo. To do this, I'll walk you through the steps and describe the challenges we faced, the choices we made, and the lessons we learned from building the first iteration of our recipe recommender system.
The Challenge
Cookidoo is the recipe platform for Vorwerk's digitally powered cooking appliance Thermomix. Currently, over 5 million users can find over 80 thousand recipes in twelve different languages on the Cookidoo platform. One of the central values of the platform is to enable users to find and cook recipes they love. Cookidoo has an excellent team of content creators and some simple rules for curating recipes automatically, such as top trending recipes. But users have different tastes and highly value personalized experiences (also because they are used to recommendations from services such as Spotify and Netflix). Having personalized recipe recommendations at their fingertips can be the difference between a platform the users love and a suboptimal experience where users feel that "there are no recipes for me." Furthermore, a well-crafted personalized experience can reduce meal choice and preparation efforts during busy days, inspire users with new culinary ideas, and support a healthy diet. Accordingly, our team's vision is To make your daily "What to cook?" decision easy and joyful.
General Structure Of Recommender Systems
People are often under the impression that recommender systems are end-to-end machine learning models that you throw data into to get out polished recommendations. That couldn't be further from the truth. Modeling is just one of many steps in building recommender systems. Also, surprisingly, these steps usually include a large number of rule-based filters and business logic.
For our recommender problem, it helped us to conceptually divide our system into three components:
- Model SelectionDefine training data and find the best model for your use case.
- Candidate SelectionSelect items that you consider a candidate for a recommendation.
- Scoring & RankingScore all user-item combinations and create an individual item ranking for each user.
Next, I'll go through each of our components in more detail. Since this article is part of a two-part series, I'll cover Model Selection next and tackle the remaining components in a second blog post.
For a more comprehensive overview of the components of recommender systems, I highly recommend this talk by Even Oldridge, the blog post by Karl Higley, as well as System Design for Recommendations and Search by Eugene Yan. However, keep in mind that most of the information on recommender systems comes from companies and experts facing challenges at the scale of billions of users and items. So, be sceptical about adding components, methods, and technologies to your system and thoroughly evaluate what you need to create a valuable experience for your users.
Model Selection
Use Interaction Data Over Explicit Data
For recommendation problems where you want to recommend items to users, you can get a good 60-80% solution by using some variant of a matrix factorization1 model on interaction data.
Interaction data is data on the interactions between your users and items. In our case, this includes:
- User A cooked recipe Gazpacho.
- User B added recipe Asparagus and Mango Salad to his cooking list.
- User A viewed the recipe details page of the recipe Vegan Bean Burgers.
Simple cooking interactions might look like this in our data:
| datetime | user | recipe |
|---|---|---|
| 2020-07-14 09:59:28 | User A | Recipe 6643 |
| 2020-04-30 07:42:56 | User B | Recipe 6493 |
| 2020-06-15 14:51:44 | User C | Recipe 7393 |
| 2020-04-13 14:30:24 | User C | Recipe 8404 |
| 2020-06-15 18:27:12 | User D | Recipe 8389 |
This interaction data is much more valuable than ratings, so if you have both, always start with the interaction data! We prioritized the cooking data and plan to experiment with additional interaction data soon.
From the beginning, a big concern for us was to keep user data private, secure, and, as a minimum requirement, GDPR compliant. Of course, good privacy practices can lead to higher efforts. However, building them right at the start is absolutely necessary and reduces efforts in the long term. For example, ask yourself:
- What user data do I need to store, and for how long? How can I minimize my need for data?
- How can I ensure that the users and their interactions stay anonymous?
- How can we delete data when users opt-out from data sharing?
Training Data Selection - Global vs. Local
We had three main options for selecting interactions to train our model on:
- Training one global model with all cooking interactions
- Training one model per language
- Training one model per language and geographic region (e.g., one model for interactions of English speaking US users, another model for English speaking users from the UK)
Cooking behaviour is very different around the world, and localizing a recipe is not as easy as changing audio tracks or adding subtitles in the case of movies. Furthermore, on Cookidoo, most recipes only exist in one language. Even for familiar recipes like pancakes, ingredients and how ingredients are balanced might be highly specific to a language and geographic region. This rules out option 1.
On the downside, this implies that we cannot leverage the full potential of our data for training the model. After all, taste clusters like vegetarianism or a "taste for curry dishes" are stable across regions. Furthermore, limiting training data by slicing by language (and geographic region) makes getting good results for languages with small user bases incredibly challenging.
We chose option 2training one model per language_to balance these two concerns. In addition, to respect each user's regional preferences, we filter out recipes that don't fit their region or measurement system (metric vs. imperial) in the candidate selection stage (more on that in the following article of this series).
Choosing An Implementation - Start Simple
As we wanted to release the first version of our recommender to users as fast as possible, we evaluated two open-source packages, Implicit and LightFM. The implicit package implements a very efficient version of the matrix factorization algorithm for interaction data (for algorithm details, see this paper Collaborative Filtering for Implicit Feedback Datasets). The LightFM package also implements a matrix factorization algorithm but allows including side-information (e.g., recipe categories or recipe tags).
In the end, we went with the LightFM package. It was vital for us to get a decent working solution as fast as possible and iteratively improve from there. Both, Implicit and LightFM work pretty well out of the box and implement matrix factorization efficiently, so you don't have to worry about performance too much. However, in contrast to the Implicit package, LightFM allows adding user and recipe metadata to quickly improve upon simple matrix factorization.
Deep learning Doesn't Automatically Equal Better Recommendations
Deep learning has lately gained lots of popularity in the recommender field. However, you should only expect significant recommendation improvements from deep learning when using massive interaction datasets, lots of context data, or unstructured metadata such as pictures or texts. Another problem that deep learning solves well is recommending the next item in a sequence (e.g., click-through prediction in online advertisements or next item recommendations in browsing sessions).
Of course, there might be other reasons to use a deep learning framework such as Pytorch or Tensorflow, e.g., a fantastic ecosystem around model monitoring, versioning, and serving. However, we were convinced to make faster progress with LightFM, and switching later to a more expressive and flexible DL framework is always possible.
On Spark ML
When starting our recommender journey, we were restricted to an on-premises Hadoop cluster and used the spark.ml package. I wouldn't recommend going this way. Matrix factorization is pretty inefficient in Spark due to the data shuffling overhead, and you'll probably train your model much faster on a single node with the packages above. Often, when you think that you have too much data for a single machine, you are okay after properly preparing your data and converting it to a sparse format. In my experience, distributed machine learning is seldom worth it and creates much unnecessary complexity.
Model Evaluation - Don't Worry Too Much About Offline Evaluation
There are two evaluation modes for recommender systems offline evaluation and online evaluation. Offline evaluation is analogous to evaluating other machine learning models (like classification), i.e., you hold out test data and evaluate the models' predictions on this test data. You try to evaluate your recommendations without actually showing the recommendations to anyone. In contrast, online evaluation tests the model live on your users, usually through A/B testing.2.
My key takeaway for offline recommendation success measurement is not to worry too much about it. We spent too much time deliberating on the best offline metric to use when we should have invested the time elsewhere.
Some guidance I can offer from our experience:
- Don't rely too strongly on offline metrics. It is difficult to interpret these metrics and even more difficult to relate them to your business problem. Instead, use offline metrics only as a directional indication for comparing your different models.
- If you start with recommender systems, use either NDCG, Precision@k, or Mean Reciprocal Rank and worry later about offline metrics that might better fit your business case and recommendation design.
- Don't just focus on hyper-parameters and offline metrics but make qualitative judgments on the recommended items. For example, we found that recommendations tend to be heavily biased towards popular recipes. We counteracted this by subtracting the trained item biases from the final score. You can think of item biases capturing popularity.
- Invest early into a nice A/B testing setup and the definition of online success metrics! Unfortunately, we started too late with this and underestimated the technical and organisational difficulties we would face.
For more advice, I'll leave you with some further readings that helped me a lot:
- Karl Higley in Top Model - How to Evaluate The Models You Train dives deeply into the topic. He has fantastic suggestions like segmenting your online and offline metrics by users, and item attributes to see how performance is distributed (e.g., frequent users vs. occasional users, dramas vs. comedies) to identify underserved groups and make relevant improvements.
- In The Netflix Recommender System: Algorithms, Business Value, and Innovationyou'll find an excellent description of how Netflix decided on online metrics that support training recommender models that positively impact their subscription-based business model.
Summary And Outlook
I hope you learned something new from our experience with pre-filtering training data and model selection for recommender systems. In the next blog post, I'll discuss the surprising amount of simple filtering rules used in modern recommendation systems and the engineering challenges in serving recommendations to users efficiently.
I thoroughly enjoy tackling all kinds of challenges with the incredible team at Vorwerk Elektrowerke GmbH & Co. KG and Alexander Thamm GmbH. If you also find these challenges exciting and want to work with us, have a look at the
and


- For an excellent introduction to matrix factorization algorithms, I recommend the blog post Intro to Implicit Matrix Factorization by Ethan Rosenthal.
- I won't go into more detail here; our A/B Testing Journey is worth another blog article in the future.









0 Kommentare