
For a long time, the data warehouse was considered the central source for all data analyses. In the course of increasing digitalisation and the resulting mass of available data, the data lake has now overtaken the classic data warehouse. Numerous use cases from the context of Industry 4.0 are inconceivable without a suitable data platform based on the data lake concept.
Inhaltsverzeichnis
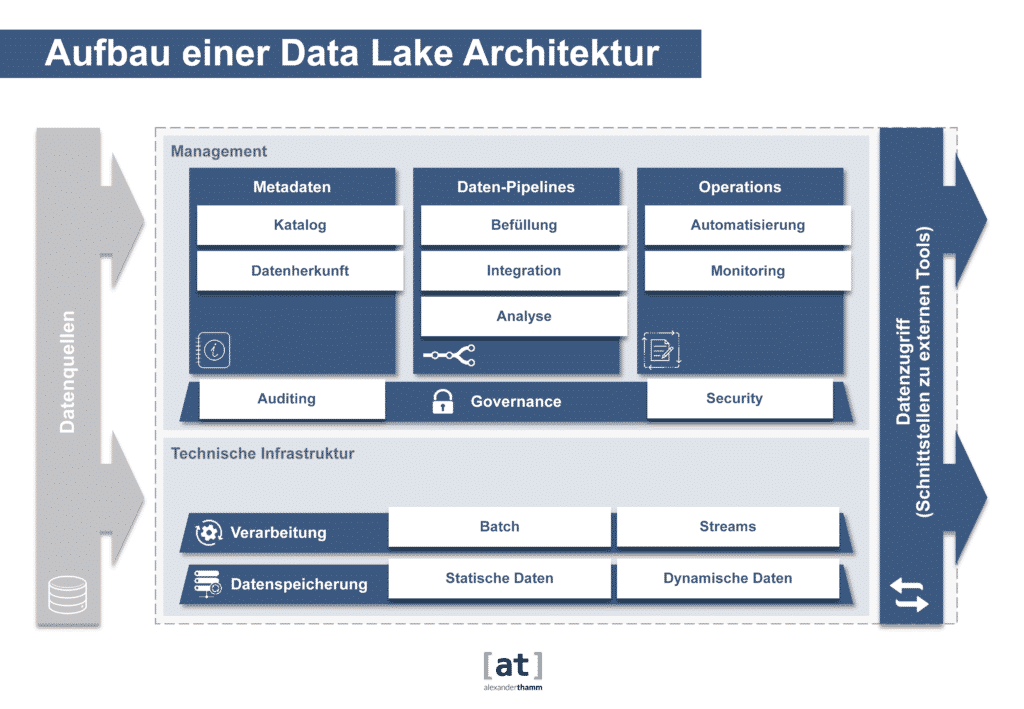
The data architecture
The right architecture for dispositive data processing had been clearly defined since the 1990s. An ideal-typical singular (enterprise) data warehouse collects the relevant data from the various operational source systems in a hub-and-spoke approach and harmonises, integrates and persists them in a multi-layer data integration and data refinement process. In this way, a single point-of-truth should be created from a data perspective, from which in turn data extracts - usually in a multidimensional preparation - are subsequently stored in definable data marts for different use cases. The user accesses this treasure trove of data via reporting and analysis tools (business intelligence). The primary focus is on the more past-oriented analysis of key figures along consolidated evaluation structures.
Characteristics of a data warehouse
The essential characteristic of the data warehouse is to represent a valid and consolidated truth about all structured data in a company. In addition to this uniform view of the company data, the data warehouse makes the data available for evaluation optimised in a strict and predefined data model. This High demand for correctness and degree of harmonisation usually resulted in it taking quite a long time for Data from a new data source are integrated into the consolidated view, because a lot of conceptual and coordination effort is required in advance.
Fast data preparation with the Data Lake
With the emergence of new data sources, such as social media or IoT data, the need to make them available on a data platform has increased. Much of this data is then available in semi-structured or unstructured form. With the increasing relevance of these data sources, the idea of the data lake was born. The Data Lake aims to make all source data - internal and external, structured and polystructured - available as raw data, even in their unprocessed form, in order to have them available as quickly as possible. The Efficient handling of large amounts of dataThe focus of the data lake is on the rapid processing of data streams and the mastery of complex analyses at the expense of data harmonisation and integration.
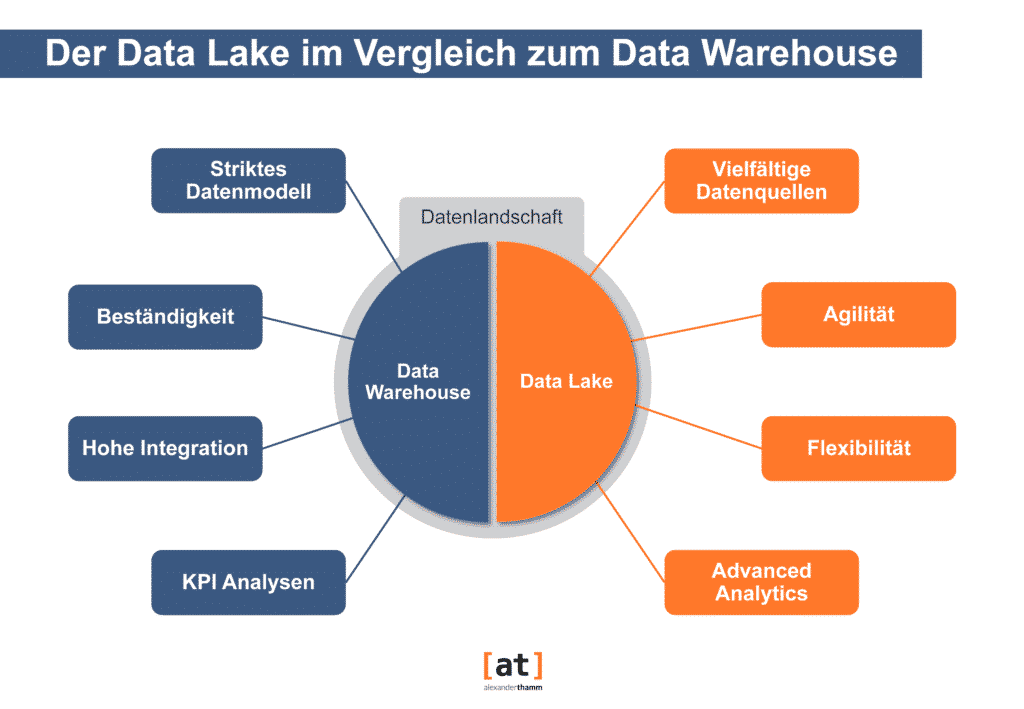
Data warehouse vs. data lake
Compared to the data warehouse, the data lake is more about the Integration of diverse data sources with the highest possible agility and flexibility in the foreground, in order to create the data basis for diverse advanced data analyses, which are usually not even determined at the time of data storage. The data lake is therefore the Eldorado for the Data Scientistwho wants to perform exploratory analyses such as cluster/association analyses, simulations and predictions via complex algorithms. This also makes it clear that a data lake does not replace a data warehouse, but complements it. Both architectural concepts have their relevance and serve different use cases.
| Data Warehouse | Data Lake | |
| Data | - No raw data storage - Structured data - Schema-on-write: Data is transformed into a specific schema before being loaded into the data warehouse. | - Raw data storage - Flexible in terms of data structure (unstructured and structured) - Schema-on-read: Automatic recognition of the schema during the reading process |
| Processing | Data layer inseparable from processing layer | Very flexible because different frameworks are available for processing for different tasks |
| Analytics | Descriptive statistics | Advanced Analytics |
| Agility | - Reduced agility - Fixed configuration - Ad-hoc analyses not possible | - High agility - Configuration customisable - Ad-hoc analyses possible |
| Security | Mature | - Due to the multitude of technologies that are used within a data lake, multiple configurations are necessary. - Security guidelines are more complex |
In industry, there are two major professional drivers for the use of Data Lakes: The Production optimisation and the Offer better or new productsand in some cases completely new business models. The basis of use cases here is the "digital twin", i.e. the digital image of one's own produced machines and the connection of these to the data lake with almost real-time data updates. Two major obstacles have to be overcome in practice: The required master data on materials and components are located in systems of different organisational units that have not yet communicated with each other automatically. In addition, different technical protocols are used at the technical level, so that communication components must first be retrofitted as a prerequisite for data availability.
The technology
The first generation of Data Lakes were systems based on the Apache Hadoop stack in their own data centre. With these early platforms, the complexity of the technology, consisting of numerous open source components, as well as the connection in the required timeliness were also challenging. Due to the change in the market situation of the commercial distribution providers and the general strategy of increased cloud use, this is shifting for second-generation data lakes: In the case of Use of native cloud services and or Dedicated managed Hadoop environments the complexity of managing the basic platform has been massively simplified. This has lowered the barrier to entry and now makes it possible for almost any size of company to use it.
However, the recommendation remains valid that technology should only be deployed once a clear use case assessment and prioritisation has been defined on a roadmap as the cornerstone of the deployment!
Choosing the right technology
The choice of components to be used initially must be made carefully and a continuous search for and evaluation of alternatives from the commercial, open-source and Cloud services options in order to be able to create optimal added value for the company.
When selecting the components to be used for one's own company, the focus in industrial use is not only on functional requirements, but also on protecting business secrets from (global) competitors and legal aspects, such as the use of the platform with data from countries in which legal requirements geographically restrict the exchange of data. A special feature for machine manufacturers is the additional challenge of accessing the data of their own machines in the customer context, as machines from different manufacturers are often used in combination and customers in turn do not disclose all data to protect their company.
Another area of tension is formed by the requirements of productive Use Cases vis-à-vis the needs of the Data Science Users. Here, too, the approach has changed over time: Initially, platforms were built that could serve all user profiles - from providing an API for a customer portal with high response time requirements, to complex analytical queries - but it has become more feasible to split these across different technical platforms.
The key conditions in practice
When setting up a data lake initiative, the key conditions for successful implementation are similar to those for the implementation of a central data warehouse: a strong management decision to set up and use a central platform initiative and the resulting close cooperation between business and production IT, and possibly also product development, which has often not been practised so far, are elementary. This not only brings together a wide range of data, but also unites the knowledge about this data, such as the signals of individual sensors and the interpretation of the states as a system.
Last but not least, the operation of a data lake must be set up in a correspondingly flexible and holistic manner: Best practice has been a DevOps team, which continuously develops the platform and keeps it stable in operation.
Conclusion
In summary, every Industrie 4.0 initiative needs a data lake platform. The technological barrier to entry has fallen, but still requires sound planning of the architecture. The basis should be a roadmap for deployment for use cases. In order to maximise the resulting long-term value creation, it is also important to create the necessary organisational conditions for the successful use of a data lake platform in addition to the technology.







0 Kommentare