
This article was first published as a cover story in the magazine BI-Spektrum (issue 4 / 2021) under the title ÜThe report was published under the title "Data Lakes of the Second Generation".

As a central element of a data-driven organisation, many companies rely on the development of a data platform based on the data lake concept. However, the high expectations of such data lakes are often not fulfilled in the short term. Instead of discussing the implementation of data-driven use cases, a dispute breaks out about different architectures and possible technologies for the architectural implementation of the data lake. The market dynamics have also led to first-generation on-premise data lakes often being supplemented or replaced by second-generation architectures and technologies after only a short time. As best practices, this paper presents common design principles and the relevant cloud technologies for second-generation data lakes based on a reference architecture.
Inhaltsverzeichnis
Data lake as a further element within an analytical ecosystem
In the 1990s, the data warehouse concept established the idea of a separate data platform for planning reporting and analysis purposes in practice, which integrates and consolidates redundant data from the operational systems [Gluchowski et al. 2008]. The focus of the data warehouse concept was the idea of integrating the usually structured data of the source systems into a predefined and coordinated data model. The high demand for correct and company-wide harmonised data usually meant that it took quite a long time in data warehouse projects until data from a new data source was integrated into this consolidated view, as a lot of conceptualisation and coordination effort was necessary in advance.
After the turn of the millennium, a new idea for an integrating dispositive data platform emerged with the data lake concept in the context of the discussion about big data with a focus on the fast and immediate processing of structured as well as unstructured mass data. The basic idea is commonly attributed to James Dixon, who first coined the image of a data lake in a blog post from 2010 [Dixon 2010]. The data lake makes all source data - internal and external, structured and unstructured - available as raw data, even in its unprocessed form. The data should be available in the data lake as quickly and unadulterated as possible immediately after data generation in order to be able to address current and future analytical questions.
The efficient handling of large polystructured data volumes, fast (often almost real-time) processing of data streams and the mastery of complex analyses for new data science and machine learning applications are in the foreground of the data lake at the expense of data harmonisation and integration. Instead, the focus is on the structure of the data in favour of fast and complete integration into the data lake, not already during storage, but only in the context of downstream analysis. Thus, the goal of a data lake is the creation of flexible structures to tame the complex integration of the multitude of data sources.
While the relationship between the data lake and the data warehouse was often not entirely clear in the general discussion at the time, the understanding of a cooperative coexistence of both concepts, which form the foundation for an analytical ecosystem in the company, is now becoming more and more established [Dittmar 2013]. Both concepts have equal fields of application along their focal points. The following table summarises the essential characteristics of the data warehouse and the data lake. However, it should be noted that the established characteristics are becoming increasingly blurred, especially in connection with current architectural concepts such as the data lake house.
| Data warehouse: database for systems of record | Data Lake: Data basis for Systems of Innovation |
|---|---|
| - Provides 80% of analyses with 20% of data | - Original extension of the DWH staging area |
| - Optimised for repeatable processes | - Stores raw data for current and future exploration and analysis |
| - Supports a wide range of internal information requirements | - Optimises data for analytics solutions in an uncomplicated way |
| - Focus on past-oriented evaluations | - Focus on unknown data discovery and future-oriented data science & artificial intelligence |
| - Schema-on-Write with harmonised data model | - Schema-on-read with real-time raw data management |
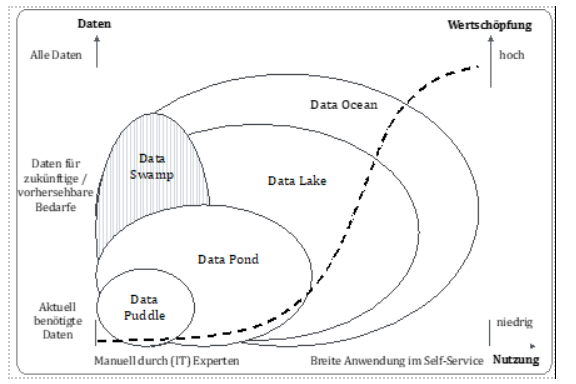
There is no doubt that different forms of data lakes have developed in practice. Depending on the proportion of data from the entire data household available in the data lake and the number and organisational origin of the users, a distinction can be made between data puddles, data ponds, data lakes in the narrower sense or a data ocean [Gorelik 2019].
A data puddle as the first form of adaptation of the data lake concept is characterised by its limited data pool, which only covers the current use case, and local use by (IT) experts, which requires a high degree of manual activities for use. A data pond construct is a multitude of isolated data puddles standing next to each other.
A data lake in the narrower sense differs from a data pond in two essential factors: Firstly, self-service use by users is made possible without the involvement of IT. Secondly, a data lake in the narrower sense contains data that is not currently used but could become interesting in the future. The data ocean is seen as the ultimate answer to data-driven decisions, based on all of a company's (business) data and with simple, understandable access for all employees. However, the resulting value creation can only be marginally increased compared to a well-positioned data lake in the narrower sense.
A special form is the notorious data swamp. It is an accumulation of different data that is not organised and processed at all or not very well. Furthermore, there is a lack of metadata that prevents use by a broader user base.
Design principles of a Date Lake
Best practices are only just emerging in the design of data lakes. Using design principles, essential characteristics of a data lake can be defined across the board from individual characteristics. Within the data processing process, these design principles can be divided into the three steps of connecting data sources, data storage and access to the data. In addition, there are design principles that describe the characteristic properties of the underlying data lake platform.
The following figure provides an overview of the design principles of a data lake, which of course vary in different project contexts.

Data sources should be connected to the data lake in such a way that rapid (and agile) testing and the subsequent productive implementation of current and potentially new use cases is made possible. Source data should be connected as broadly as possible along the primary sources with the finest available data granularity.
In the area of data storage, keeping the original raw data format is a decisive factor in order to enable any reinterpretation of the data. The use of a zone concept has established itself as a sensible organisational unit within a data lake architecture. Especially after the amendment of data protection regulations, it has become common practice in many data lakes to avoid the use of personal data through complete anonymisation. In contrast to the data warehouse, the implementation of a balanced rather than a unified data model is a defining characteristic of a data lake. In the data lake, deviating definitions that can be justified by different use cases are permitted, so that a costly and lengthy reconciliation process for harmonising the data is not required.
Liberal access to a data lake ideally allows many users to access the data. Only in justified exceptional cases is access to be controlled on a fine-grained basis. Examples are personal, confidential or company code-related data. Access should also be technically possible without restriction.
The data lake platform itself should be stable, scalable and cost-efficient. Suitable means for this are the implementation as 'infrastructure as a code' and the use of open standards. Contrary to the original principle of the Apache Hadoop architecture, a separation of storage and compute resources should be aimed for. Data Lakes should have all ingest and data management capabilities necessary for data integration and processing. The latter should also be usable via central scheduling and monitoring processes. In order to avoid a data swamp, it is of elementary importance to capture professional and operational metadata as automatically as possible with a suitable tool and to make it usable for all users. When used in a (large) company, it is also important to integrate it into the general IT. This includes, among other things, integration into the central identity management system, billing options for use, auditability of use (in accordance with the applicable requirements) and the provision of a continuous integration/continuous deployment (CI/CD) process.
Zone-oriented reference architecture of a data lake
The data architecture of the data lake is usually oriented towards so-called zones, which is why it is often referred to as a zone-based data lake [Madsen 2015]. A zone determines the degree of processing of the data contained in the zone. A typical zone structure differentiates four zones, as shown in the following figure.
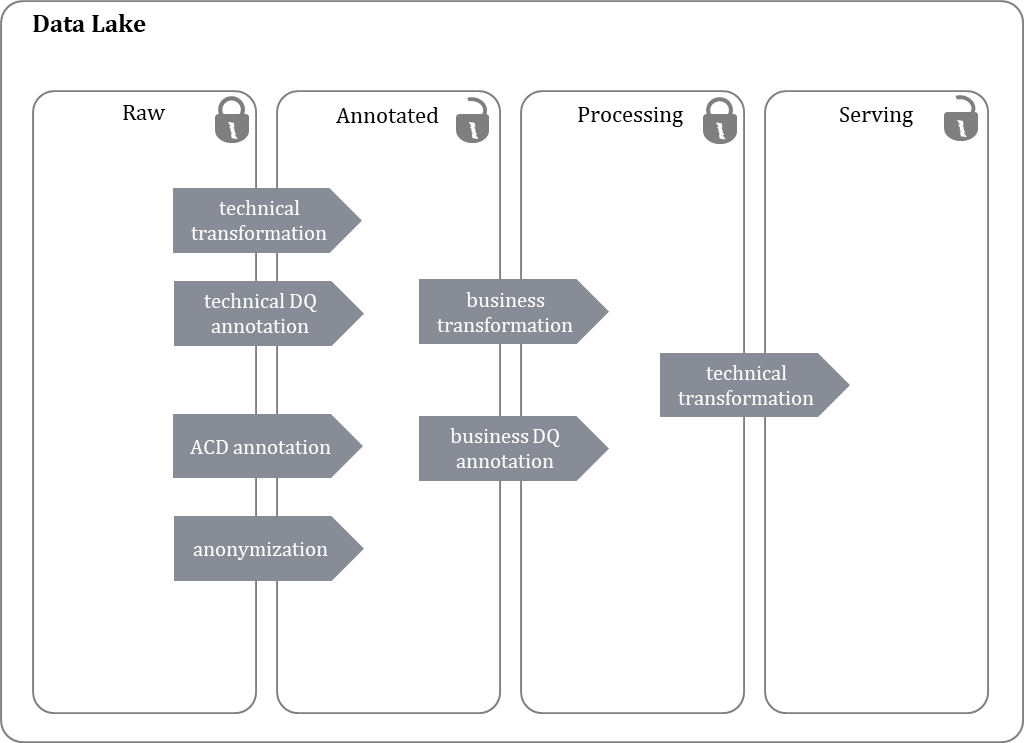
As a rule, the first zone, the raw zone, contains the incoming data in its raw, unprocessed form. The data in the raw zone is retained even after further processing and is generally not deleted.
In the subsequent annotated zone, the data from the sources are prepared in such a way that user access is possible. For this purpose, technical format transformations are carried out to enable easier access, and technical data quality information is added. Furthermore, information on uniform data access authorisation control is added via reference to uniformly defined Access Control Dimensions (ACDs). At the latest here, personal data is anonymised for use.
In the subsequent processing zone, the data is prepared for easy use by the user. For this purpose, technical transformations are carried out in order to combine data from different sources, to carry out enrichments and calculations and to add technical data quality information.
Finally, the Serving Zone is logically not a zone of its own, but is used exclusively for the technical optimisation of data access to data that is already available in the zones below it. In this zone, different storage organisation forms such as Row vs. Column based are used to support known access types as quickly as possible.
Generations of Data Lakes
The large data lakes of the first generation were primarily built in the company's own data centre with large dimensioned nodes. The goal for many companies was to build one data platform for all purposes of use. This approach brought numerous challenges, as requirements such as "deep analytic queries on very large data sets" and "API for customer-facing website with expected response time behaviour in the range of seconds" partly contradict each other in their architecture patterns.
Furthermore, the original basic paradigm of the Apache Hadoop stacks in the form of dedicated coupling of storage and compute in the nodes of a cluster. Data Lakes of the first generation are mostly based on commercial distributions of the Apache Hadoop stack. It was hoped that this would reduce the necessary know-how for productive use. In retrospect, however, it must be noted that despite the use of commercial distributions, a higher level of know-how was required for productive support compared to other common commercial applications. In addition, the market of providers of commercial distributions has consolidated in recent years. As a result, the commercial conditions for users have generally deteriorated.
Driven by the changed market situation of the commercial distribution providers and by the general strategy of increased cloud use, the basis of the second generation Data Lakes is shifting: the separation of storage and compute is becoming more and more important in the Cloud computing (inexpensive) object stores are thus largely replacing the Hadoop Distributed File System (HDFS). In this second generation, a mixture of cloud native services and Apache Hadoop Stack components is used. Thus, the monolithic approach is discarded and multiple, dedicated clusters are used for individual tasks. Commercial distribution providers are also shifting their offerings away from on-premise installable software to service offerings on the infrastructure of the large cloud providers.
Technology classes for building a data lake
The second generation Data Lakes can be divided into two classes with typical development patterns, divided by the zones shown in Figure 2.
The first type is a migration of the Hadoop stack approach to the cloud. Here, the RAW zone is no longer mapped in HDFS, but mostly as object storage of the cloud provider used, i.e. ADLSv2 in MS Azure or S3 in AWS. The storage of the other zones is also mapped as object storage, but often supplemented by performance-optimised storage organisations in the serving zone, e.g. Apache Impala in the Cloudera CDP offering. Data management is also taken from the classic data lake stack and is carried out in particular with Apache Spark. Typical representatives of this genre are AWS EMR, MS Azure HDInsights, Cloudera CDP or Databricks ECS.
The second type shares the mapping of the RAW zone in cloud object storage, but follows a different approach in the mapping of the other zones: the data is loaded as early as possible into a cloud-based relational database in the MPP (massive parallel processing) embodiment and then processed in parallel within this. Here, the ELT (Extract-Load-Tranform) pattern is applied, which distributes the parallel processing of tasks among the available nodes. Typical representatives are, for example, AWS Redshift, Snowflake and Teradata Vantage.
Both types mostly use cloud-native services for ingest, such as MS Azure Data Factory or AWS Glue, if the data is accessible for them, or the widespread Apache NiFi, which also enables the integration of various on-premise data sources.
On the usage side, a distinction is made between two types: classic dashboarding and reporting on the one hand and advanced analytics environments on the other. For dashboarding and reporting, data in relational representation (either via e.g. Apache HIVE, Apache Impala in type one or the relational MPP database in type two) is essentially accessed via classic JDBC (Java Database Connectivity). Typical representatives are AWS Quick Sight, MS PowerBI, Tableau, Qlik. In addition, advanced analytics environments provide the basis for working via code (e.g. Python, Apache Spark, R). The user interfaces are so-called notebooks, which are equipped with allocated compute resources and can access the data. Examples are the open source project Jupyter and the commercial cloud offerings Amazon Sage Maker, MS Azure ML, Cloudera ML and Databricks ECS.
Furthermore, there has been great progress in easy-to-use integrated services. These include the entire spectrum necessary for building and using a data lake platform. Current examples are AWS Lake Formation, Azure Synapse, Databricks ECS. In addition, there are numerous niche providers who are trying to implement this approach.
Conclusion
Data Lakes have become established as a central instrument of digitisation in recent years. The principles for setting up data lakes have evolved: Essential principles such as "if possible, completely connect a source with its data immediately, even if only a subset is needed for the use case currently to be implemented" still apply. Others have undergone an evolution: today, Apache Hadoop HDFS is predominantly no longer the standard for storing raw data, there is a strict separation of storage and compute - and thus there are no longer any large new monoliths. Only for very large data volumes and query volumes is a solution in one's own data centre based on the classic Hadoop stack more economical.
Through the diversification of the solutions offered, previous obstacles such as the extreme complexity and the lack of necessary skills to set up a data lake in the company have significantly decreased.







0 Kommentare