
In order to integrate data groups into a data warehouse and simplify extraction, the ETL process (Extract - Transform - Load) is helpful. They are used especially for larger amounts of data and enable precise management. For this reason, it makes sense to rely on new measures for process automation within the framework of digitalisation and to ensure a link to the operational systems. This gives companies the opportunity to work with data that can be interpreted in business terms and that can simplify management in a holistic way. But what exactly is it about the associated processes?
Inhaltsverzeichnis
What is the ETL process?
In order for a company's business processes to be noticeably simplified, operational company data is a crucial approach. They enable a Continuous control and monitoring of the daily businessto make the right decisions for further content development. The following three steps are important here:
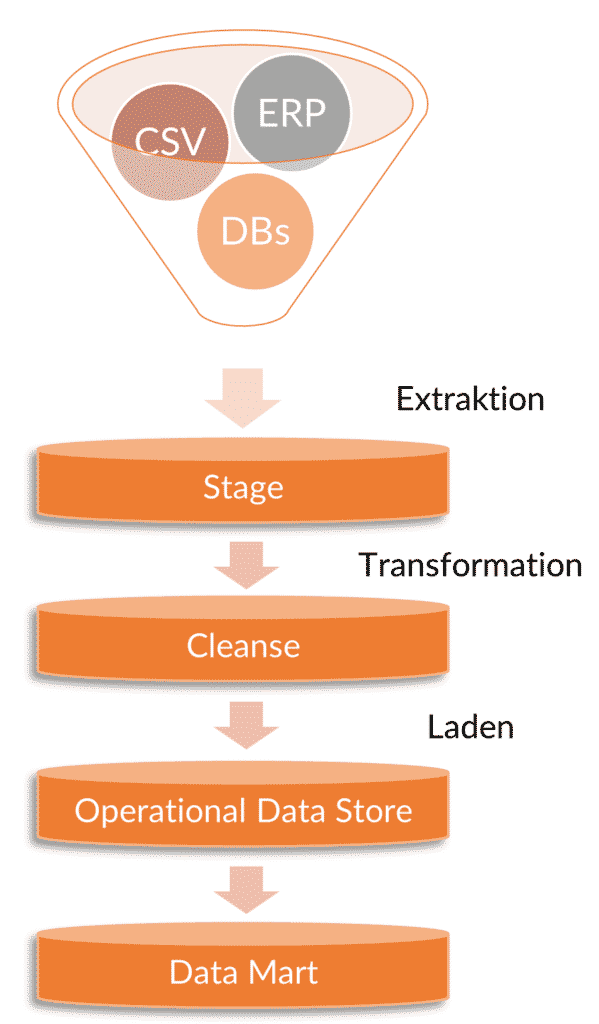
- Extraction
During extraction, performance data is taken from source systems and documents in order to select suitable processing steps for checking and analysis. This does not necessarily have to be done holistically, but can be implemented using partial aspects of the source data. Through the continuous extraction, a constant supply of new data takes place.
- Transformation
In order to make the data sets fully usable, the transformation is important. This ensures that the source data types are converted into a clear target table that can be used to check the content of the data. This makes it easy to identify possible duplicates, to perform calculations and to have a holistic overview of the data basis.
- Shop
In order for the important performance data to be used transparently and comprehensively, it must be finally loaded into the data warehouse. This enables structured and normalised storage. Thanks to the additional historisation, the course of time always remains comprehensible. Logs and clear loggings can of course be implemented to maintain an overview.
The areas of application of the ETL process
When it comes to industry-typical ETL processes, a clear and recognisable simplification can be provided in many application areas. This applies, for example, to the classical data storage in a Data Warehousebut also around the provision of data for BI applications. The migration of data systems between different applications is also one of the central ETL processes to increase the speed of all measures and effectively reduce loading times. Thus, the processes lead to easier data management.
In addition to the areas of application already mentioned, the data extraction of distributed database environments or directly from the Cloud an important ETL process. In all the areas presented, large amounts of detailed data have to be processed, provided and analysed, which is why compact and clear process control is an excellent choice. Around the many database management systems of leading manufacturers such as Oracle, IBM and SAP, there are already some possibilities to manage data systems and the associated applications.
The ETL process has these characteristics
In many cases, the ETL process is directly linked to concrete ETL tools. These provide faster and direct transmission to competently and holistically simplify the implementation of the individual process phases. With the following functions, the ETL processes can be relieved in this way in order to make the best possible use of the modern and practical tools:
- Easy linking with numerous clouds
- User-friendly and optimised application
- Structured visualisation of all ETL phases
- Effective processing with maximum performance
- Clear handling of larger amounts of data
- Linking with hybrid cloud architectures
Especially for larger amounts of data, it therefore makes sense to rely on more advanced solutions for your own data management. In the ETL process, there are many individual steps to be taken into account at this point, which quickly become a burden without a well thought-out strategy. The selection of the appropriate tool therefore becomes a Central basis for success of data optimisation. Through the connection to the additional logging, the individual measures can also be recorded completely at a later point in time. This maintains the transparency of the data system.
ELT vs. ETL process - what are the differences?
All around data processing, the Swap steps transformation and loading. This refers specifically to the abbreviations ELT and ETL, which stand for the arrangement of the process steps. In this specific case, the first step is to upload the data to the cloud as a database and then use special algorithms to ensure effective development. This makes structuring much easier in order to be able to retrieve the changed content at any location.
Especially for the Big Data environment, the ELT process is a popular solution for initially collecting possible data volumes for structured evaluation. Here, no special processes are provided for normalised methods of storage as in the classic warehouse, which means that data processing can be guaranteed synchronously and comprehensively. This makes it noticeably easier for companies to develop raw data into further information and to modify the sequence from the ETL process accordingly.
Conclusion
ETL technologies improve access to data. For example, in a decision-making process Relevant data sets are quickly consulted become. Managing large amounts of data is no small feat. Without the ETL extraction process to organise data and make it understandable, a company would primarily waste resources collecting data. Implementing the ETL process can all collected data is used in a meaningful way.
Do you need help with the planning and implementation of such a project? Then talk to us!






0 Kommentare