
Explainable AI (XAI) is currently one of the most discussed topics in the field of AI. Developments such as the AI Act of the European Unionwhich makes explainability a mandatory property of AI models in critical domains, have brought XAI into the focus of many companies developing or applying AI models. As this now applies to a large part of the economy, the demand for methods that can describe the decisions of models in a comprehensible way has increased immensely.
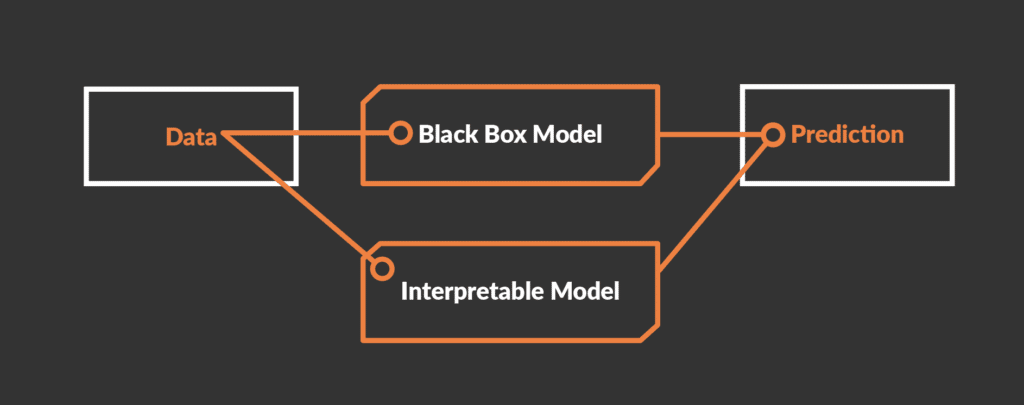
But why is explainability such an important property? What methods from the field of XAI can help us understand the decisions of a complex data-driven AI algorithm? We want to get to the bottom of these questions in this article with a slightly more technical focus. The basic mechanism of many AI models is that patterns are learned from a large amount of data and these are then used as the basis for decisions for new examples. Unfortunately, in many cases it is not obvious or difficult to understand which patterns the AI model has learned. For the creator and the user, the model forms an Black boxwhere we do not know the logic that leads from an input to a certain output. In this article, we will focus on AI models for tabular data because they are central to a large set of business use cases.
By nature, there are several models that are more explainable than others: Linear regressions and decision trees, for example, are relatively explainable by design alone. So if you are developing a model from scratch in which explainability plays a central role, you should opt for these or similar models. However, this is not sufficient in many use cases. In more complex use cases, where e.g. Deep Learning or ensembles are used, an attempt is made to establish explanatory power with the so-called post-hoc (after the fact) analysis of models.
Inhaltsverzeichnis
Post-Hoc Approaches for XAI
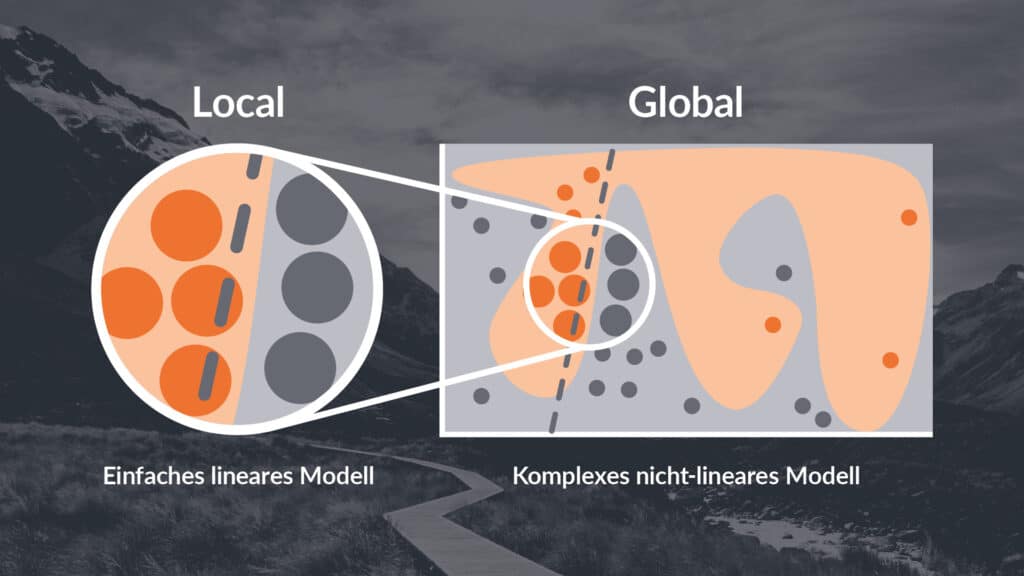
In the meantime, there is a well-filled toolbox of methods that make it possible to analyse and evaluate the decision logic of a black box model - i.e. a model in which the decision logic is not comprehensible. In principle, however, many methods follow similar approaches. Therefore, we describe here a number of approaches with which a black box can be made transparent or at least dark-tinted instead of deep black, depending on the approach and complexity. As a rule, a distinction is made in post-hoc methods between global and local approaches.
- Global methods attempt to map and interpret an entire model. The aim is to understand the general decision logic of the model. An example is to train an explainable model with all available inputs and outputs of a black box model and to examine the new explainable model for its decision logic.
- Local methods examine the decision of a model for a specific input in order to understand how this specific input leads to the corresponding output. An example of this are methods that change a specific input slightly over and over again and use these new variants to investigate the behaviour of the model.
In addition, the methods can be model-agnostic or model-specific. We focus here on model-agnostic methods that can be applied to any type of AI model. Model-specific methods are methods that are only applied to a specific type of AI model. Below we summarise some of the most common model-agnostic XAI methods for tabular data.
Global methods
Global Surrogate Models
In this approach, the behaviour of a black box model is analysed with the help of an explainable model. All that is needed is a data set of inputs and outputs of the black box. With the help of this data set, an explainable model, such as a linear regression, can then be trained. However, caution is advised because the quality of this "explanation" depends heavily on the quality of the data set. Moreover, the simpler explainable models may not be able to represent the complex decision logic of the black box model. Conversely, if a simplified substitute model can be found that can fully replicate the output of the complex model, then of course the complexity of the model under investigation can be questioned.
Permutation Feature Importance
The concept behind this method is relatively simple: if a feature is important for the decision of an AI model, the prediction quality of the model should deteriorate if this feature is made unrecognisable. To test this, in a dataset, the values of a feature are randomly shuffled across all examples so that there is no longer a meaningful relationship between the new value of the feature and the target value for an example. If this significantly increases the error that the AI model makes in its predictions, the feature is rated as important. If this is not the case, or only to a lesser extent, the feature is considered less important.
Causal Discovery
An interesting, but somewhat more complex method is Causal Discovery. Here, an undirected graph is created based on the correlation matrix of the data. This graph connects all features and outcome variables in a network - the graph. This network is then reduced to the necessary size and complexity using optimisation techniques. The result is a graph from which causalities can be derived. To be more precise, one can intuitively infer the effect of the individual features on the result of the model from the graph. However, even such methods do not come with guarantees. Reliable and stable results for such explanatory models are difficult to obtain insofar as the resulting graphs often depend very sensitively on the selected input.
Local methods
Local Surrogate Models (LIME)
LIME (Local interpretable model-agnostic explanations) is about training a local "surrogate model" for an example. In simple terms, LIME takes a defined input (an example), processes it through the black box model and then analyses the output. Now the features of the example are slightly changed one by one and the new example is sent through the black box model again. This process is repeated many times. In this way, at least around the point of the initial example, an explicable model can be created that makes the influence of the features on the output apparent. Using the example of automatic claim processing for a car insurer, this would mean changing the features of a claim slightly again and again (vehicle type, age, gender, amount, etc.) and testing how the decision of the AI model changes as a result.
SHAP
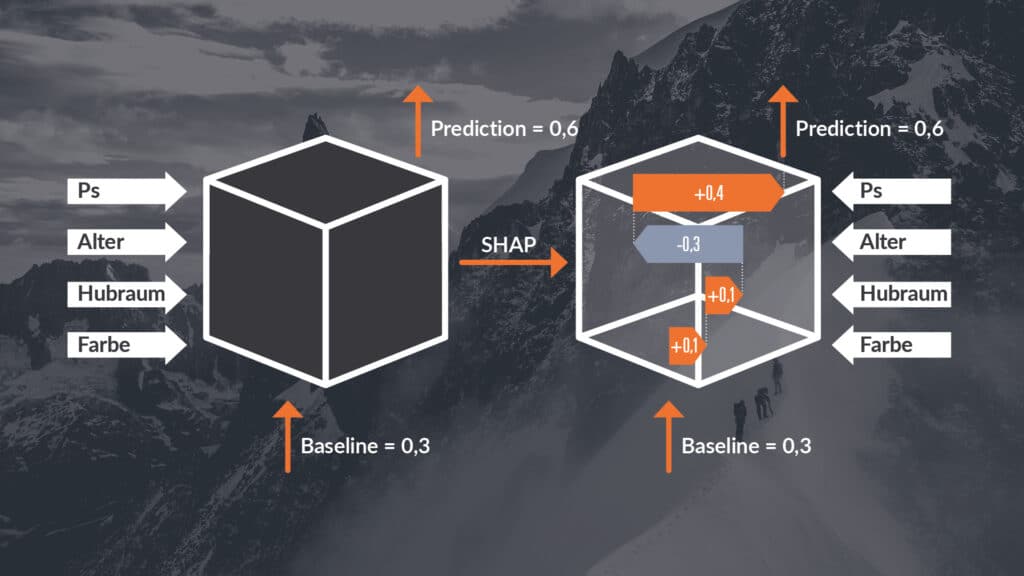
SHAP (SHapley Additive exPlanations) can be used to analyse how much influence which features have on the prediction of the model for a particular example. SHAP works by permuting the features of the input to analyse how important certain features are for the output. Permutation in this case means that the values for certain features are replaced with the values of other examples in the data set. This idea is based on Shapley Values, which come from game theory. The output of a model is understood as the winnings of a cooperative game, while the features represent the players. Permutations are used to determine how much each "player" (feature) contributes to the "win" (output). A major advantage of SHAP is that it can produce both local and global explanations. SHAP is one of the most popular XAI methods, although the very high number of permutations requires considerable computing capacity.
CXPlain
CXPlain is a newer method that tries to preserve the strengths of methods such as LIME or SHAP, but avoid the drawbacks, such as high computation times. Instead of training an explainable model that emulates the black-box AI model or testing a high number of permutations, CXPlain trains a standalone model that estimates the importance of each feature. The model is trained based on the errors of the original black-box AI model and can thus provide an estimate of which features contribute the most to the prediction of the black-box AI model. In addition, CXPlain provides an estimate of how confident the model is in its predictions - and thus how uncertain the results are. This is not the case with other XAI methods.
Counterfactuals
What would have to change in the input for the output to change? This question is asked when using counterfactuals. Here, it is determined what the minimum necessary changes are for the output of a model to change. To make this possible, new synthetic examples are generated and the best ones are selected. Using the example of "credit scoring": by how much must the age or assets of the person making the request be changed so that a loan is granted instead of rejected. For example, does changing the gender from "female" to "male" cause the credit to be granted? For example, unwanted biases in the predictions of the model can be identified. The example of automatic claim processing for a car insurance company is similar. We ask the question: "What are the minimum characteristics of the policyholder that would have to be changed to alter the model's decision?"
Why not build white-box models directly?
In general, all methods described here refer to post-hoc interpretation of models. However, it should not be forgotten that many problems can also be solved with existing comprehensible models. Methods like regressions or decision trees can solve many business usecases and are explainable. However, particularly complicated or larger problems make it necessary to use more complex models. To make these explainable, we use the methods described here, among others, in practice. Producing explainable models is currently one of the core application areas of AI. This is particularly underlined by current legislation such as the European AI Act, which makes explainability a mandatory property of AI models in critical areas. Of course, it also makes intuitive sense to prefer explainable models. Who would want to sit in an autonomous driving car controlled by an AI that is so complex that not even the manufacturers know how and why the AI makes its decisions.










0 Kommentare