
Wussten Sie, dass der erste Porsche, das Modell P1 aus dem Jahr 1898, ein Elektroauto war? Es hatte eine Reichweite von 79 km und ist seitdem in Vergessenheit geraten, während sich die Verbrennungstechnik durchsetzte. Und wussten Sie, dass unsere Vorfahren ihre Felder viel effizienter bewirtschafteten, als es durch moderne landwirtschaftliche Verfahren möglich ist? Heute ist die Agrarwirtschaft charakterisiert durch Monokulturen und den übermäßigen Einsatz von Düngemitteln und Pestiziden – was zu geschädigten Böden, Unterernährung und einem beschleunigten Klimawandel führt.
Erst in jüngster Zeit haben wir begonnen, diese Entwicklungen zu hinterfragen. Was wir aus unseren Erfahrungen lernen können, ist, uns mehr von der Natur inspirieren zu lassen – und so zu nachhaltigeren Antworten zu kommen.
Im Moment erleben wir einen Hype um Deep AI. Branchenexperten gehen davon aus, dass durch KI die Weltwirtschaft bis 2030 um 15 Billionen Dollar wachsen könnte. Laut der jüngsten IDC-Prognose werden weltweit die KI-Ausgaben in den nächsten vier Jahren auf 110 Milliarden Dollar steigen und sich damit verdoppeln. Die Energiekosten für Deep Learning haben sich zwischen 2012 und 2018 um das 300.000-fache erhöht. Das innovativste Sprachmodell im Jahr 2019 hatte 1,5 Milliarden Parameter. Die Version für 2020 hat 175 Milliarden Parameter. Was kommt als Nächstes?
Gibt es ein Ende, eine Grenze – oder sind wir dabei, den gleichen Fehler zu begehen, indem wir einem weiteren, nicht nachhaltigen Hype folgen? Wir müssen uns mit grundlegend anderen KI-Ansätzen beschäftigen!
Inhaltsverzeichnis
Gewöhnliche Intelligenz für eine Artificial General Intelligence
In einem Blog-Post im vergangenen Jahr haben wir die Meilensteine auf dem Weg zu einer „echten künstlichen Intelligenz“ – einer Artificial General Intelligence (AGI) – diskutiert.
Die in der Industrie eingesetzten Lösungen für künstliche Intelligenz werden oft als „narrow AI“ bezeichnet. Sie können meist nur eine Aufgabe erfüllen. Ein natürliches neuronales Netzwerk wie das menschliche Gehirn hingegen ist universell. Ein und dasselbe Netzwerk kann eine unendliche Anzahl von Aufgaben ausführen. Gehirne können dynamisch neue Aufgaben erkennen und übernehmen, die in den jeweiligen Kontext passen.
Auf dem Weg zu einer allgemeineren KI ist es wichtig, sich der Unterschiede zwischen künstlichen und biologischen neuronalen Netzen bewusst zu sein. Mögliche Fallstricke solcher Vergleiche werden in späteren Beiträgen diskutiert. Für den Moment wollen wir die weit verbreitete Idee der Skalierung bestehender Ansätze in Frage stellen und Alternativen untersuchen.
Skalierung ist nicht die Lösung
Sie haben vielleicht schon von den GPT-Modellen (Generative Pre-Trained Transformer Models) von OpenAI gehört. Die 175 Milliarden Parameter in der neusten Version, GPT-3, wurden mit einer unglaublich großen Menge an Textdaten trainiert (das englische Wikipedia macht nur 0,6 % davon aus). Beim Launch schlug das Modell aufgrund seiner erstaunlichen Eigenschaften große Wellen in den Medien.
Angesichts solcher Entwicklungen ist die Versuchung, zu glauben, dass mehr immer besser ist, groß. Es werden immer größere Netzwerke mit immer mehr Daten trainiert. Die Hauptbegründung, diesen Weg weiterzugehen, ist, dass die Skalierung bisher funktioniert hat.
Wir scheinen jedoch einem sich selbst erhaltenden Hype aufzusitzen. Die aktuellen Modelle werden immer größer, weil “wir es können“. Wir wissen, wie wir sie skalieren können. Wir wissen, wie wir sie trainieren können. Uns wird immer leistungsfähigere Hardware zur Verfügung gestellt. Und es wird Geld investiert, um noch weiter voranzukommen. Man fühlt sich an Hightech-Trends in der Landwirtschaft erinnert, wie z.B. die moderne Bewirtschaftung von Monokulturen für größere Erträge profitabler Nutzpflanzen, die letztlich die Böden auslaugen. Die Ernte skaliert dabei aber nicht über die Zeit. Und doch sind diese nicht nachhaltigen Praktiken weit verbreitet und das Problem weitgehend unerkannt. Eine aktuelle Netflix-Dokumentation mit dem Titel „Kiss the ground“ versucht, etwas Licht ins Dunkel zu bringen.
In ähnlicher Weise weist ein Aufsatz des Allen Institute for AI aus dem Jahr 2019 auf die abnehmenden Erträge der Modellgröße in allen KI-Teilbereichen hin. Viele der hinzugefügten Knoten in den Netzwerken werden nach dem Training nicht ausgenutzt – sie erhöhen nur die Flexibilität während des Trainings. Ähnlich wie die meisten Neuronen und Verbindungen in den Gehirnen von heranwachsenden Kindern entstehen, während sie die Welt erleben. Stattdessen werden ungenutzte Synapsen und Zellkörper in Gehirnen entfernt und recycelt (siehe Video unten). Daher verbrauchen nur wesentliche Teile des Netzwerks Energie. Das ist beim klassischen nicht-adaptiven Deep Learning nicht der Fall, wo die Dimensionen eines Netzwerks fix bleiben, sobald sie einmal eingerichtet sind.
Während die Modelle vielleicht um ein paar Prozent an Genauigkeit und Leistung gewonnen haben, ist ihr Energieverbrauch überproportional gestiegen. Das geschah, obwohl die Computerhardware effizienter wurde. Die Kosten für das Erforschen und Trainieren eines hochmodernen Sprachmodells wie BERT Transformer entsprechen den Kosten eines 747-Jets, der von New York nach San Francisco fliegt. Um dies ins rechte Licht zu rücken: Das ist ungefähr die gleiche Menge an CO², wie fünf durchschnittliche Autos während ihrer Lebenszeit ausstoßen (inklusive Treibstoff). Das US-Energieministerium schätzt den Beitrag von Rechenzentren auf etwa 2 Prozent des gesamten Energieverbrauchs im Land. Das entspricht ziemlich genau dem Stromverbrauch des Agrarsektors und dem Zehnfachen des öffentlichen Verkehrs.
Heute stammt diese Energie hauptsächlich aus traditionellen Energiequellen. Die großen Tech-Unternehmen sind sich dieses Problems bewusst. Google, Microsoft, Amazon und Facebook behaupten, kohlenstoffneutral zu sein oder sogar auf dem Weg dazu zu sein, negative Emissionen zu haben. Es ist wichtig zu beachten, dass ihr Fokus nicht darauf liegt, weniger Energie zu verbrauchen, sondern sauberere Energie zu nutzen. Was wir sehen, ist schlicht eine wachsende Nachfrage nach Energie in diesem Bereich. Und die Menge an grüner Energie, die zur Verfügung steht, ist immer noch begrenzt (zwischen 11 % und 27 % des globalen Stromerzeugungsmixes). Weitere Zahlen zu den ökologischen Kosten von KI finden Sie im WIRED-Magazin und in der MIT Technology Review. Das DIN Deutsches Institut für Normung e. V. und das Bundesministerium für Wirtschaft und Energie haben in Zusammenarbeit mit 300 Fachleuten einen aktuellen Branchenleitfaden veröffentlicht. Es ist nicht verwunderlich, dass es in dem Leitfaden heißt “Es muss sichergestellt werden, dass die energieeffizienteste Variante der Analyse gewählt wird“.
Natürlich sollten wir nicht vergessen, dass KI auch zur Energieeinsparung beiträgt, indem sie effizientere Prozesse ermöglicht. Ein Beispiel für den gewinnbringenden Einsatz von KI zur Energieeinsparung sind intelligente Gebäude. KI kann einen starken Beitrag zu mehr Nachhaltigkeit leisten, wenn sie richtig eingesetzt wird, indem sie ökologische, ökonomische und soziale Aspekte berücksichtigt.
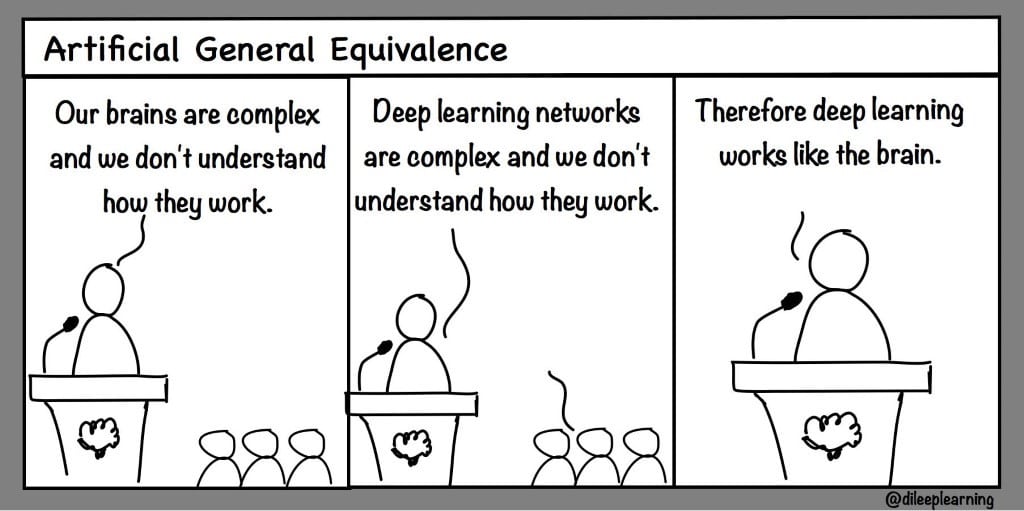
Der Erfolg der Skalierung von GPT-2 auf GPT-3 löste weit verbreitete Vorhersagen darüber aus, wann wir die künstliche allgemeine Intelligenz erreichen werden. Solche Thesen beruhen oft auf falschen Annahmen und irreführenden Vergleichen mit Zahlen in der Natur. Das veranlasste die Deep-Learning-Legende Geoffrey Hinton (UCL) zu einem Twitter-Witz:
Mit dem Laden des Tweets akzeptieren Sie die Datenschutzerklärung von Twitter.
Mehr erfahren
Was verstehen wir wirklich?
Es ist selten, dass Data Scientists ein komplexes neuronales Netzwerkmodell ohne Versuch und Irrtum entwerfen und trainieren.
Mit zunehmender Größe und Menge der verallgemeinerten Trainingsdaten geht die Intuition hinter diesen Modellen bereits mehr und mehr verloren. Ihre Schöpfer sind oft von den Ergebnissen ihres eigenen Modells überrascht – seien es nun schlechte oder gute Ergebnisse. Sicher, Formeln können aufgeschrieben werden. Diagramme können gezeichnet werden, und wir haben vielleicht sogar eine vage Vorstellung von dem Informationsfluss und den stattfindenden Transformationen. Auch können wir recht erfolgreich verschiedene Netzwerke zusammenstellen, bei denen wir eine Vorstellung davon haben, was passiert. Doch die Vorhersage, welche Modellarchitektur für eine bestimmte Aufgabe am besten geeignet ist, wird mit zunehmend wachsenden Modellen und Datenmengen immer schwieriger.

Unter diesem Gesichtspunkt ist es nicht verwunderlich, dass die Ergebnisse des GPT-3 Modells so verblüffend waren. Die Architektur dessen ist sehr komplex und seine Trainingsdaten extrem unspezifisch, weshalb es kein klares intuitives Verständnis für ein solches Modell gibt.
Obwohl der Output überraschend sein kann ist es letztendlich aber „nur“ ein „normales“ Modell ohne Magie und kommt nicht einmal annähernd an das heran, was ein menschliches Gehirn leisten kann. Es wurde ohne ein bestimmtes Ziel trainiert, außer eine kohärente Abfolge von Wörtern zu erstellen, und daher waren seine Ergebnisse nicht vorhersehbar. Dies gilt für unüberwachte Lernmethoden im Allgemeinen. Besonders, wenn sie auf massive unstrukturierte Daten angewendet werden.
Das wirft eine grundlegende Frage auf: Müssen wir – angesichts des Erfolgs von GPT-3 – überhaupt jedes Element eines Modells vollständig verstehen? Es scheint einen Konsens auf dem Gebiet zu geben: Verstehen ist ein „nice to have“, aber für KI-Anwendungen nicht unbedingt erforderlich. Dies kommt in den ersten beiden Worten des folgenden Zitats von Terrence Sejnowski, Miterfinder der Boltzmann-Maschine, zum Ausdruck:
„Vielleicht wird eines Tages eine Analyse der Struktur von Deep-Learning-Netzwerken zu theoretischen Vorhersagen führen und tiefe Einblicke in die Natur der Intelligenz offenbaren.“ – Terrence J. Sejnowski
Es werden tolle Tricks erfunden, um die Genauigkeit eines Modells zu erhöhen, ohne wirklich zu wissen, warum sie funktionieren. So hat sich die Microsoft-Forschungsgruppe kürzlich an die Lösung von „three mysteries of deep learning“ gemacht. Erklärungen für den Erfolg von Methoden werden im Nachhinein angeboten, nachdem sie schon lange im Einsatz sind. Dies ist typisch für die Branche.
Eine weitere typische Strategie im Deep Learning ist es, bestehende Architekturen aufzublähen und mehr Daten für das Training zu verwenden (wie bei der Entwicklung von GPT-2 zu GPT-3). Oft lautet die Devise „Einfach mal ausprobieren!“. Im Falle von GPT-3 hatte dies zur Folge, dass es – obwohl seine Modellarchitektur keine Grundlage für ein richtiges Verstehen bietet (wie es für eine künstliche allgemeine Intelligenz erforderlich wäre) – aufgrund der riesigen Datenmenge in der Lage ist, das Schreibverhalten von Menschen sehr gut zu imitieren. Das liegt daran, dass in dem riesigen Textkorpus, der zum Training zur Verfügung gestellt wird, eine Beschreibung für fast alles enthalten ist.
Angesichts der Attraktivität solcher Ansätze ist es nicht verwunderlich, dass wir in der Praxis kaum Netzarchitekturen sehen, die grundlegend anders sind. Modelle, die nicht differenzierbar sind, sind unterrepräsentiert. In solchen Modellen können die Ansätze, die zu einer optimalen Lösung führen, nicht berechnet werden. Das Training der Parameter solcher Netze gleicht wiederum einer blinden Vermutung.
Es wird sogar behauptet, dass GPT-3 Rechnen gelernt hat. Ja, es kann einige einfache Berechnungen durchführen – so, wie sie in den Trainingsdaten zu finden sind. Es kann die Konzepte sogar bis zu einem gewissen Grad verallgemeinern. Allerdings hatte GPT-3 das Ziel, die gemeinsame Wahrscheinlichkeitsstruktur einer massiv großen Textmenge zu lernen. Ein Mathematiker weiß mit Sicherheit, dass das Ergebnis 123 ist (mit einer Wahrscheinlichkeit von 100%), wenn er 12345.678/12344.678 berechnet. Ein generatives Modell wie GPT-3 kann das Ergebnis nur mit einer Restunsicherheit erraten. Es macht eine beste Schätzung. Wahrscheinlich wird es in diesem Fall sogar ein ganz anderes Ergebnis vorschlagen. Möglicherweise hat es diese Zahlen vorher noch nicht gesehen. Daher wird die gemeinsame Wahrscheinlichkeitsverteilung dieser Eingabe unzureichend dargestellt. Der Input kann nicht mit dem korrekten Output in Verbindung gebracht werden.
Es ist keine Überraschung, dass der Hype um dieses Modell sogar den CEO von openAI zum Einschreiten veranlasst hat:
Mit dem Laden des Tweets akzeptieren Sie die Datenschutzerklärung von Twitter.
Mehr erfahren
Es gibt Alternativen
Neuronen unter Beschuss
Die überwiegende Mehrheit der im maschinellen Lernen und in der KI verwendeten neuronalen Netze besteht aus stark vereinfachten Neuronen. Im Gegensatz dazu versuchen so genannte Spiking-Neuron-Modelle, biologische Neuronen strenger zu imitieren, was mit dem Preis einer höheren Komplexität kommt. Diese Komplexität ermöglicht wiederum eine reichere Funktionalität und leistungsfähigere Berechnungen. Eines der einfachsten und bekanntesten Spiking-Neuronen-Modelle ist das Leaky-Integrate-and-Fire-Modell. Mit den technologischen Fortschritten bei der Implementierung solcher Modelle direkt in Hardware ist es fast sicher, dass wir mehr von solchen Neuronenmodellen hören werden.
Reservoir Computing
In einigen Bereichen der KI ist das Reservoir Computing ein vielversprechender Ansatz. Kurz gesagt, nutzt dieser Ansatz die Komplexität hochgradig nichtlinearer dynamischer Systeme wie rekurrente neuronale Netze mit festen Parametern. Das sequentielle Einspeisen von Daten in ein solches System löst ein Resonanzverhalten aus. Es ist wie das Aufprallen eines Steins oder eines Regentropfens auf die Oberfläche eines kleinen Teiches. Oder das Erzeugen eines Echos in einer Höhle. Die Reaktionen innerhalb solcher Systeme sind schwer vorherzusagen.
Auch wenn der größte Teil des Netzwerks nur chaotischen Unsinn zu machen scheint, kann ein Teil des Systems tatsächlich etwas so Komplexes wie eine Frequenzanalyse durchführen. Ein anderer Teil führt vielleicht eine Glättung oder eine Klassifizierung durch.
Beim Reservoir Computing wird nicht einmal versucht, die Parameter solcher Systeme zu trainieren. Stattdessen wird gelernt, wo die interessante Berechnung innerhalb solcher Systeme zu finden ist. Das ist äußerst vielversprechend, wenn man bedenkt, wie viel Zeit aktuell mit dem Trainieren von Netzwerkparametern verbracht wird. Außerdem ist es hier nicht einmal erforderlich, Netzwerke zu simulieren. Wir können – oder könnten – einfach physikalische Systeme wie einen einfachen Wassereimer verwenden. Da keine riesigen Computercluster zum Anlernen von Netzwerken betrieben werden müssen, kann Reservoir Computing mit minimalem Energieverbrauch arbeiten. Noch ist nicht klar, wie man das Potenzial dieses Ansatzes optimal ausschöpfen kann, aber das Gebiet entwickelt sich weiter.
Lass den Affen das Modell entwerfen
Ein grundlegend anderer, aber vielversprechender Ansatz, der im nächsten Jahr an Aufmerksamkeit gewinnen wird, ist Neural Architecture Search (NAS) und damit verwandte Techniken. Hier werden viele verschiedene Netzwerkarchitekturen ausprobiert und dann nur die besten Optionen ausgewählt. Die Art und Weise, wie die Architekturen aufgebaut werden, kann völlig zufällig sein und führt dennoch zu sehr guten Ergebnissen. Das ist, als würde ein Affe vor dem Computer sitzen und die nächste bahnbrechende Architektur entwerfen. Folgendes berichten die Autoren eines Aufsatzes von Facebook aus dem Jahr 2019:
„Die Ergebnisse sind überraschend: Mehrere Varianten dieser Zufallsgeneratoren liefern Netzwerkinstanzen, die eine konkurrenzfähige Genauigkeit beim ImageNet-Benchmark aufweisen. Diese Ergebnisse deuten darauf hin, dass neue Bemühungen, die sich auf das Design besserer Netzwerkgeneratoren konzentrieren, zu Durchbrüchen führen können, indem sie weniger eingeschränkte Suchräume mit mehr Raum für neuartiges Design erkunden.“ – (Xie et al. 2019, Facebook AI Research)
Natürlich können wir den Affen auch erziehen und weniger zufällig zu tippen. Eine Suchstrategie, die sich in diesem Zusammenhang anbietet, ist die Klasse der evolutionären Algorithmen.
Modelle schlauer machen
Forscher aus Boston und Zürich haben erst vor wenigen Monaten eine vielversprechende Idee an die Öffentlichkeit gebracht: Shapeshifter Networks. Anstatt Neuronen innerhalb eines Netzwerks wie in Gehirnen wiederzuverwenden, schlagen sie vor, zumindest einen Teil der Verbindungen zwischen Neuronen erneut zu benutzen. Damit kann die effektive Anzahl der anzulernenden Parameter drastisch reduziert werden: Sie erstellen leistungsstarke Modelle, selbst wenn sie nur 1% der Parameter der bestehenden Modelle verwenden. Das wiederum führt zu einer Senkung der Trainingszeit und des Energieverbrauchs.
Free lunch in the depth?
Wir haben mehrere alternative KI-Strategien vorgestellt. Es ist jedoch wichtig zu wissen, dass es nicht eine universelle Lösung für alle Optimierungsprobleme gibt. Dieses Theorem wird als das „no-free-lunch-problem“ (NFLP) des maschinellen Lernens bezeichnet. Deep-Learning-Methoden können oft recht universell eingesetzt werden. Dennoch gilt das Theorem weiterhin.
Festsitzen im tiefsten Tal
Die Diskussion alternativer Ansätze für traditionelles maschinelles Lernen wird in Zukunft von einer zentralen Erkenntnis aus der Biologie geleitet werden: Es gibt keine optimale Lösung, wenn es um Interaktionen mit einer unglaublich komplexen und dynamischen physikalischen Realität geht. Die Evolution stellt sich nicht dem NFLP, weil sie nicht auf eine optimale Lösung hinarbeitet. Dennoch ist es der erfolgreichste Weg zur Intelligenz, den wir bisher entdeckt haben.
Die Biologie macht sich die Existenz von mehreren suboptimalen Lösungen zunutze. So kann zwischen diesen hin- und hergesprungen werden, wodurch das flexible Agieren von Lebewesen erst ermöglicht wird. So funktionieren auch die Nanomaschinen, aus denen unser Körper besteht. Sehen Sie sich zum Beispiel das Öffnen und Schließen des Ionenkanals eines biologischen Neurons in Abbildung 6 an.
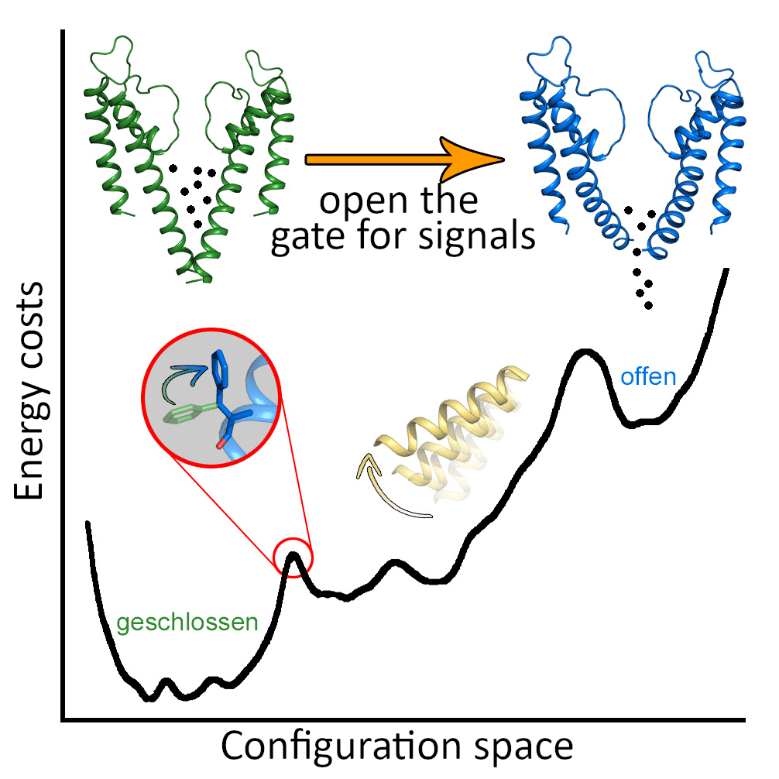
Würde alles nur auf ein globales Optimum zusteuern, wäre jegliche Eigendynamik dahin. Nehmen wir unseren Körper als weiteres Beispiel: Er würde in einer optimalen Pose feststecken, solange es keine wesentlichen Veränderungen in der Umgebung gibt, die das Optimum verschieben und eine neue Suche danach auslösen. Eine sich verändernde Welt kann schlicht nicht durch eine feste Gewichtsmatrix beschrieben werden, die auf nur eine endliche Anzahl von Aufgaben trainiert wurde.
Derzeit geht die Industrie dieses Problem mit aktiven und adaptiven Lernansätzen an, bei denen die Gewichte aufgrund neuer Erfahrungen kontinuierlich aktualisiert werden. Ein plötzlicher Sprung von einer Konfiguration (suboptimale Lösung) zu einer anderen, ausgelöst durch wechselnde Umstände, wird jedoch noch nicht wirklich berücksichtigt. Stattdessen werden unter der Haube Teilnetze mit einer massiven Anzahl von Knoten für jede der möglichen Umstände (die man als verschiedene Aufgaben bezeichnen könnte) trainiert. Aber wie wir gesehen haben, ist das Kultivieren immer größerer Netzwerke nicht die einzige Lösung! Eleganter wäre es, wenn KI-Systeme veränderte Umstände erkennen und darauf reagieren könnten. Vor allem im Zusammenhang mit der Hyper-Automatisierung, die von Gartner als einer der aktuellen Top-Trends in der Technologie identifiziert wurde. KI-Systeme müssen in die Lage versetzt werden, die Konfiguration ihrer bestehenden Architektur automatisch zu ändern. Oder eben die Auslesung ihres Berechnungsreservoirs dynamisch zu verändern. Wie in der Natur.
Früher oder später sollten wir uns daher wohl von der Idee verabschieden, die optimalen Gewichte eines neuronalen Netzwerks anzulernen. Solche Parameter können nur in Bezug auf stabile Bedingungen optimiert werden.
Es ist nicht falsch den Mainstream-Ansätzen gegenüber misstrauisch zu sein. Geoffrey Hinton ermutigt sogar dazu über den Tellerrand zu schauen:
„Die Zukunft hängt von irgendeinem Doktoranden ab, der allem, was ich gesagt habe, zutiefst misstraut… Meine Ansicht ist, alles wegzuwerfen und neu anzufangen.“ (Geoffrey Hinton, UCL)
Neue Leistungsindikatoren werden benötigt
Normalerweise wird ein künstliches neuronales Netz anhand seiner Genauigkeit (oder einer anderen Leistungsmetrik) in einer Aufgabe bewertet. Eine interessante Alternative, die in Zukunft immer mehr an Bedeutung gewinnen wird, ist die Genauigkeit im Verhältnis zum Energieverbrauch. Bei der Skalierung eines Netzwerks benötigt jede zusätzliche Einheit auch mehr Energie und Energie ist teuer. Neben dem Einfluss auf die Umwelt wird ein niedriger Energieverbrauch auch in der Welt von IOT, kleinen medizinischen Geräten und Blockchains eine essentielle Rolle für riesige für die Wirtschaft spielen. So ist im Rahmen von allgemeiner einsetzbarer KI ist ein weiterer Leistungsindikator für den Vergleich verschiedener Netzwerkarchitekturen entscheidend: Die Anzahl der möglichen Anwendungen bezogen auf den Energieverbrauch. Wie viele Aufgaben kann das Netzwerk bei welchen Energiekosten bewältigen?
„Das menschliche Gehirn – die ursprüngliche Quelle der Intelligenz – liefert hier eine wichtige Inspiration. Unsere Gehirne sind im Vergleich zu den heutigen Deep-Learning-Methoden unglaublich effizient. Sie wiegen ein paar Pfund und benötigen etwa 20 Watt Energie, kaum genug, um eine schwache Glühbirne zu betreiben. Und doch stellen sie die mächtigste Form der Intelligenz im bekannten Universum dar.“ – Rob Toews @ Forbes Magazin
Energieverbrauch kostet nicht nur Geld, sondern auch CO2. Ein kürzlich veröffentlichter ML CO2 Impact hilft Ihnen bei der Abschätzung des CO2-Verbrauchs von Machine-Learning-Anwendungen. Tools wie dieses helfen bei der Umsetzung der vorgeschlagenen KPIs für Ihr nächstes KI-Projekt.
Free lunch for you
Eine wichtige Botschaft für Führungskräfte ist sicherlich, dass bereits der Wunsch, eine Intelligenz zu schaffen, die dem Menschen nahe kommt, immer wieder enorme Talente fördert und vielversprechende Technologien hervorbringt, die ihren Weg in die Praxis finden. Es ist daher wichtig, sich weder von hochtrabenden Versprechungen blenden zu lassen, noch sich innovativen Ansätzen jenseits der etablierten zu verschließen. Hochgesteckte Ziele mögen riskanter sein, aber wenn sie erfolgreich sind, ist der positive Effekt umso größer.
Ja, es ist ein guter Rat Versprechen im Bereich der KI zu bewerten indem man sie mit dem vergleicht, was wir in der Natur vorfinden. Dieser Vergleich sollte jedoch mit Vorsicht erfolgen. Die Natur ist ein unglaublich guter Leitfaden und liefert Inspiration für die vielversprechendsten und nachhaltigsten Technologien. Und bisher funktioniert sie (viel) besser als alles, was die Menschheit erfunden hat – einschließlich KI.
Fazit
In den 1940er Jahren ahmten KI-Pioniere die Struktur des menschlichen Gehirns nach. Seitdem hat sich KI weiterentwickelt und selbst enorme Erfolge erzielt, aber der heutige Stand der Technik des Deep Learnings ist noch weit von menschlicher Intelligenz entfernt. Die Industrie wendet die Disziplin gerne „so wie sie ist“ an. Jüngste Forschungen zeigen jedoch, wie fruchtbar der Einsatz von biologisch inspirierter Hard- und Software sein könnte. Dieser Artikel soll einige vielversprechende Arbeiten in dieser Richtung aufzeigen und diejenigen, die KI einsetzen, dazu ermutigen, diesen Fortschritten gegenüber aufgeschlossen zu sein.









0 Kommentare