
Writing product descriptions is time-consuming - especially for providers who have a very large product portfolio. However, in order to be successful in online sales, these descriptive texts are extremely important. The aim of this article is to illustrate, using a concrete example (use cases), how artificial intelligence (AI) - in this case specifically: an NLP model - can be used to create product descriptions. The master's thesis "Generation of description texts comparing large pre-trained NLP models".which was submitted by the author to the TU Munich.
Inhaltsverzeichnis
First things first: What is NLP?

In general, NLP (Natural Language Processing) deals with machine language processing and includes, for example, text translation, text summarisation and text generation. The underlying idea: to build grammatical understanding through the use of (language) models and eventually solve linguistic tasks.
In this paper, this is achieved by entering key points, in which learned understanding generates detailed texts. On the one hand, this can speed up the process of creating product descriptions and on the other hand, it can be partially automated.
The application examples are numerous: The use of NLP models enables a more individual design of letters or e-mails or the promotion of products through more individual and customer-specific descriptions.
This can be helpful for many target groups: In any organisation, institution or authority where repetitive processes occur in connection with texts, the use of AI (artificial intelligence) can facilitate and speed up many things.
Automation through NLP
The aim of the underlying work was to develop models that formulate detailed texts from key points. To solve this task, extensive pre-trained language models are used through the method of the Transfer Learnings taught. In a next step, the results of the respective models used are compared by mathematical language metrics to evaluate the best model based on the given data.
Three pre-trained models were used for this purpose: GPT-2, T5 and BART of the Python Transformer Library, all developed by the Huggingface Company.
The data basis
Through web scraping, information was extracted from several thousand products of an online retailer. For each product, the title, category, subcategory, description keywords and description text were extracted. Title, category and subcategory are relevant for a unique assignment. The key points, separated by a semicolon, represent the subsequent model input and the description text is used as a label for the text to be generated., two transformers
Three models, two transformers
As already mentioned, the three models GPT-2, T5 and BART the python Transformer Library are used. These can be divided into the two areas of the "Causal language model" and the "Sequence-to-sequence model" categorise.
On the one hand, the "causal" language models the next word/token based on the previous words/tokens. The attention method used within the model is referred to here as causal and focuses attention only on the past (see (a) Causal attention). The GPT-2 model is one of these models.
For the GPT-2 model, it is important to know that the model learns the input structure during training. The input is structured by Special Tokens, which are used as characters for the outline. During the testing process, the trained knowledge enables new texts to be created (see formula 1).
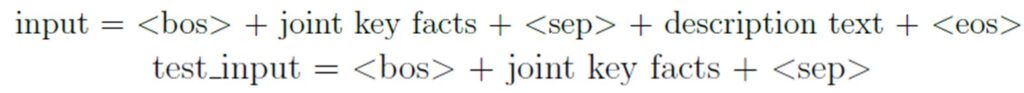
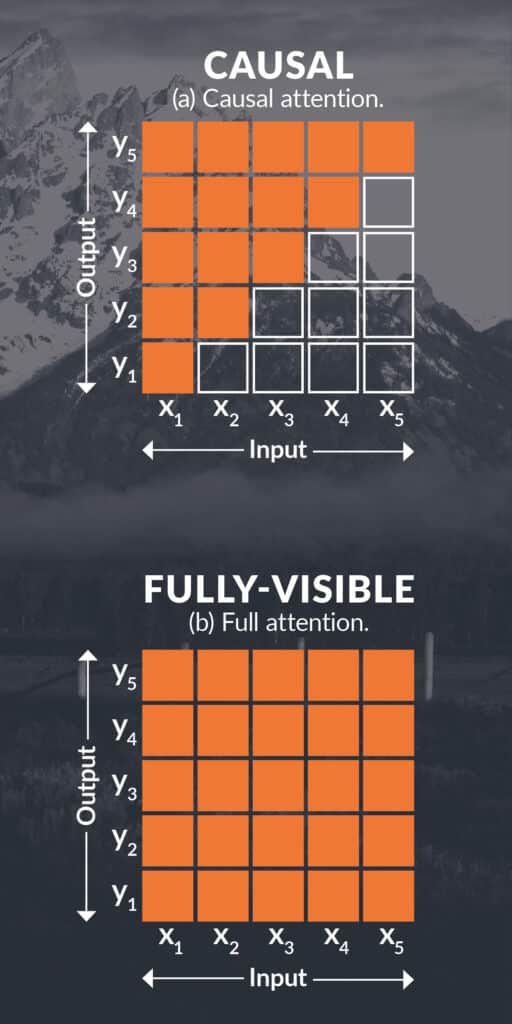
The two underlying attention methods of the "causal" language models and the "sequence-to-sequence" models are represented by a diagram of input token x_i and output token y_i.
Each box represents the connection between the respective token. The orange boxes mark which information is available at which time, while the transparent boxes represent no connection.
Causal attention thus only captures the past, whereas full attention captures both the past and the future at any point i time.
Cf. illustrations from [1].
On the other hand, the "Sequence-to-sequence models a series of words/tokens and output another series of words/tokens. A "masking" function is applied to the input sequence and "hides" words/tokens behind masks, so to speak. The models try to predict words/tokens that might be under these masks.
This technique enables the model to develop a sentence comprehension, or a kind of language comprehension. The underlying "attention" method is fully visible in this case (see (b) Full attention). These models include the T5 and the BART model. The main difference between these two models is the use of the multitask learning approach used in the T5 model. Here, an additional prefix is used to define the task of the model. For both models, the input and the label are structured similarly. One small difference: In the BART model, an additional special token is used to index the beginning of the input and the label (see formula 2 and formula 3).
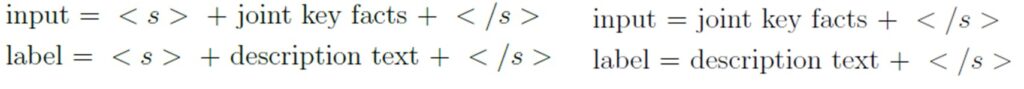
Many different sized models of all three pre-trained models are available in the Transformer Library. Due to limited computing power, smaller versions were used in this example.
Evaluationsmetrics - METEOR and BERTScore
Mathematical evaluation metrics can determine how similar a generated text is to its reference text. This is a very active field of research and there are many different metrics that focus on different features. In the underlying work, two different methods were considered, each with one metric.
One method is the n-gram Matching with the example METEOR (Metric for Evaluation for Translation with Explicit Ordering). The parallels between the generated text and the label text are searched and counted. With the absolute counts, the score metric can be calculated by a harmonic mean (see figure 2).
Figure 2 The METEOR metric is visualised schematically with example sentences. This representation of the METEOR metric is inspired by the representation of the BERTScore architecture in [2].

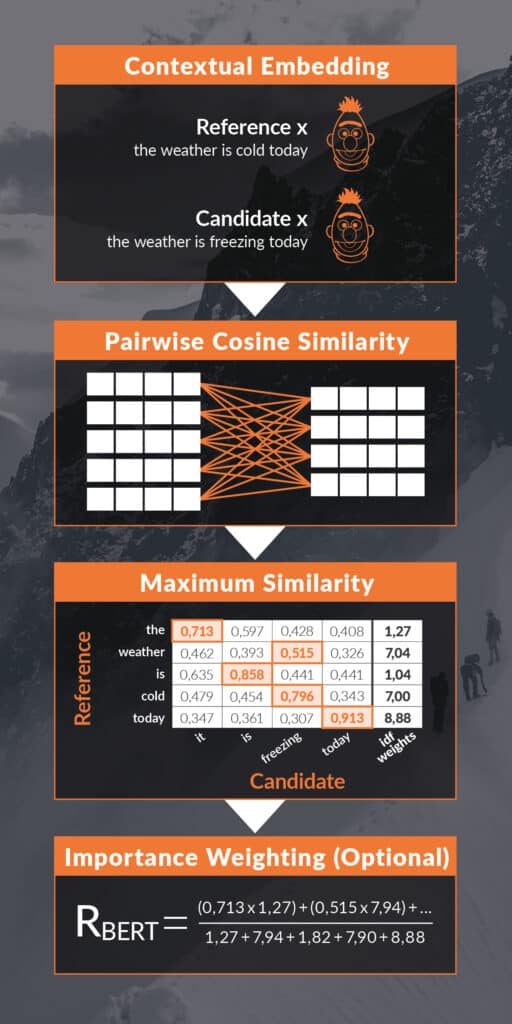
Another method are the Embedding Based Metrics. Here the texts are assessed from an independent (neutral) perspective. In the example of the BERTScore metric, the generated text and the label text are embedded in a high-dimensional space, the BERT model embedding. Based on the generated high-dimensional vectors, a similarity can be calculated between each word/token by cosine similarity and a final score can be generated by harmonic mean (see Figure 3).
The two metrics used each take other features into account and can thus give a detailed assessment that is a good linguistic assessment.
Figure 3 Each step of the calculation of the BERTScore is shown schematically with example sentences. A detailed explanation can be found in the text. Cf. illustration in [2].
Results - Performance model
The two metrics presented were applied to the texts generated by the three different models and their label text. This calculated a METEOR score and a BERTScore for each text. By looking at the mean of the METEOR scores of the training dataset in Table 1, it can be concluded that the majority of the generated texts of the GPT-2 model receive lower scores than those of the T5 or BART models. An analogous conclusion can be drawn based on the mean and standard deviation of the BERTScore values in Table 2.
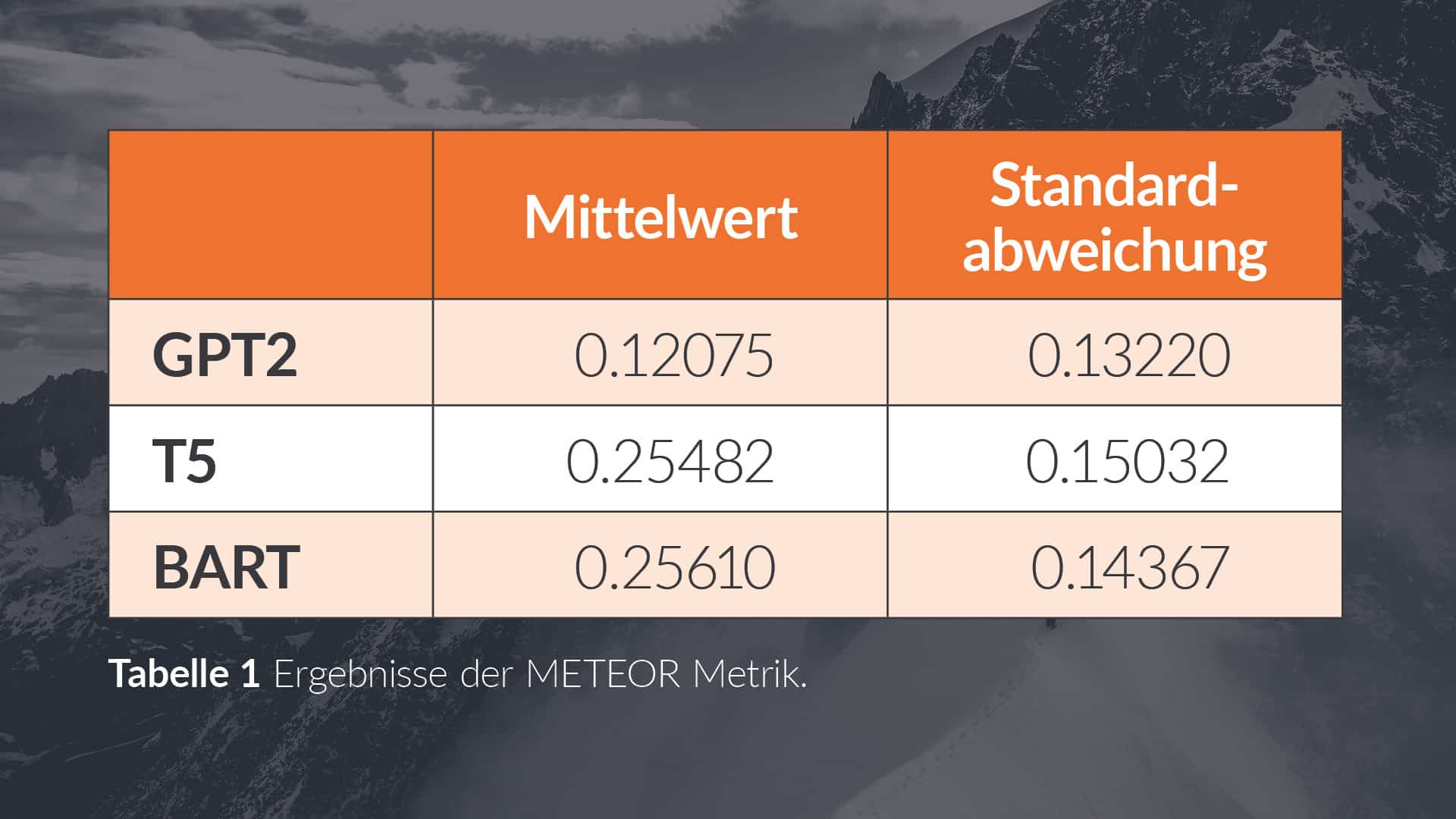
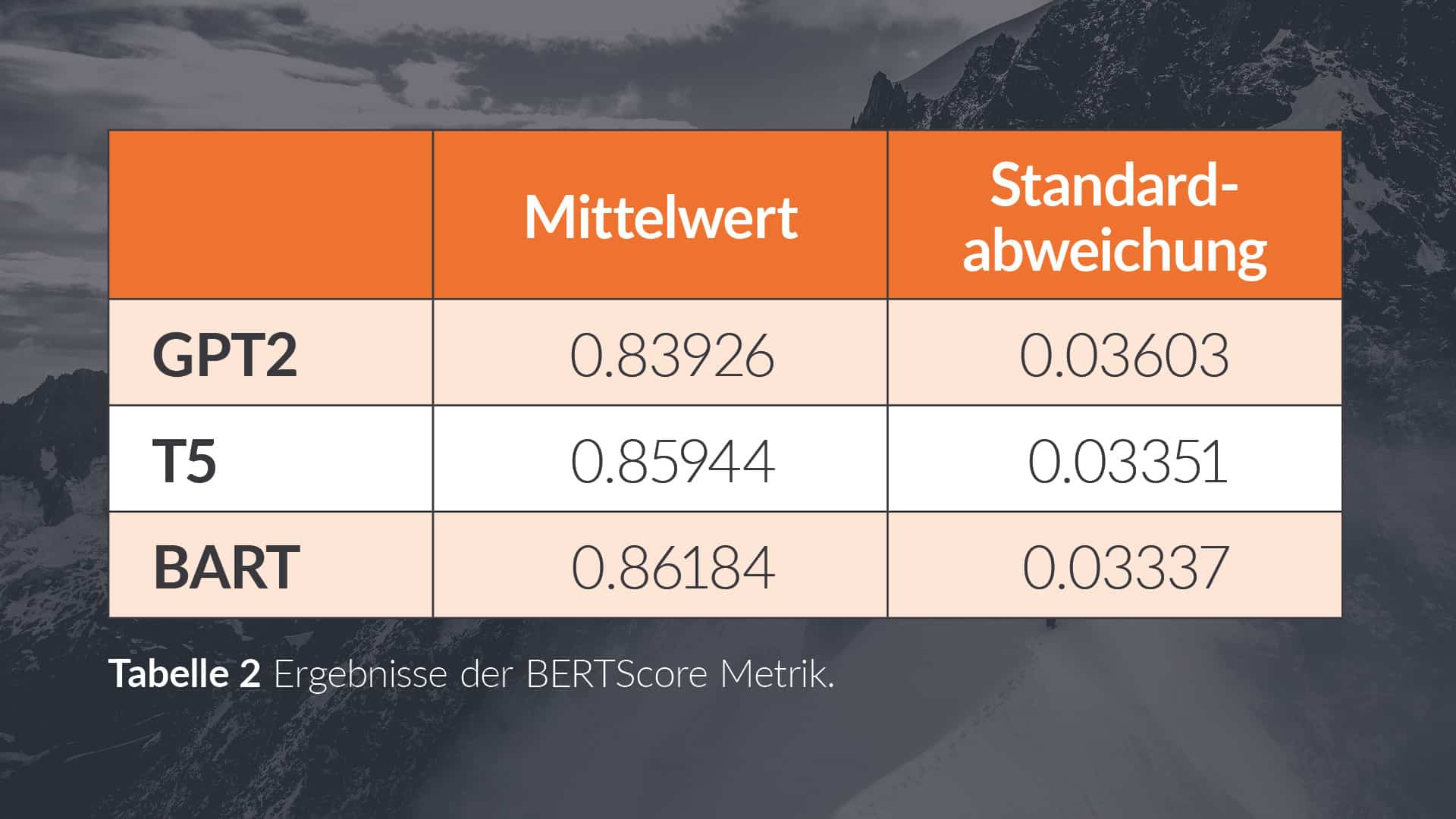
In summary, the results show that for the GPT2 model, the generated texts are less consistent with the scrapped descriptive texts. Thus, the two models, the T5 and the BART model, are to be preferred on the basis of the test set. However, the judgement of linguists would also be required for a general statement.
Conclusion and outlook
In this article (and in the underlying work) many assumptions have been made that are not universally valid. In order to make a generally valid statement about model performance that could be implemented in practice, further points would have to be considered: The relevance of larger model versions or the change in the cues used would have to be examined more closely here. In addition, a linguistic evaluation of the generated texts would be an important step in order to evaluate the results obtained in a generally valid way.
AI support for the creation of product descriptions has great potential for the future - especially in e-commerce. Many time-intensive processes can be significantly supported by efficient AI. However, the models analysed here are not (yet) suitable for implementation in practice.
Disclaimer: No language generation model was used to create this article. 😊
Sources:
[1] C. Ra_el, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140):1{67, 2020.
[2] T. Zhang, V. Kishore, F. Wu, K. Q. Weinberger, and Y. Artzi. Bertscore: Evaluating text generation with bert. In International Conference on Learning Representations, 2020.









0 Kommentare