
In recent years, artificial intelligence (AI) and especially natural language processing (NLP) has undergone a revolution driven by a specific neural network architecture: the Transformer. It is now ubiquitous and is constantly being developed and optimised. Due to its incredible popularity, there are now a variety of different transformers that address different model aspects.
In this blog series we want to give an overview of the different transformers.
Inhaltsverzeichnis
Attention is the top priority
First, let's look at the roots of breakthrough neural network architecture. In a 2017 paper, a group of researchers presented a challenger to the status quo in NLP, the Transformer. They criticised the state of the art at the time, where recurrent and convolutional neural networks dominated.
The researchers identified three critical points in RNNs and CNNs:
- the total amount of calculations they have to perform
- the low degree of parallelisation of the calculations
- the ability to model long-range connections between the elements of a sequence (e.g. words in a sentence).
The last point is particularly critical. If we take the example of RNNs, we know that the model processes a sentence or document word by word. By the time the RNN has processed the last element, the flow of information is only from the elements immediately preceding it. At the same time, the data from the beginning of the sentence does not reach the end.
The figure below shows how the flow of information moves between words as the transformers process a sentence. You can see how parallel flows of information reach one word at each processing step, obtaining information about all the words in the context. This approach solves all three problems of RNNs.

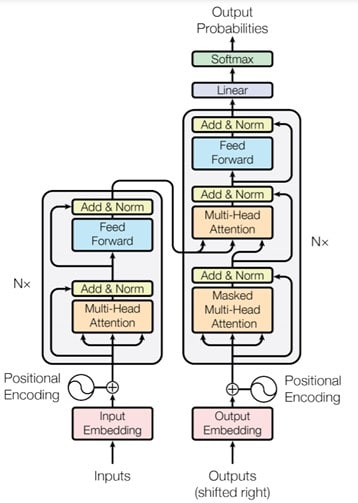
The Transformer layer, visualised in the diagram below, will become the core component of many future generations of Transformer architectures. The architecture has two core components:
- Encoder: on the left side
- Decoder: on the right side
BERT
BERT (Bidirectional Encoder Representations from Transformers) is one of the first transformers to make a breakthrough after being applied in the context of transfer learning. Transfer learning is an approach in which a neural network is first trained on a specific task and then applied to another task. This method enabled further improvements for the completion of the second task.
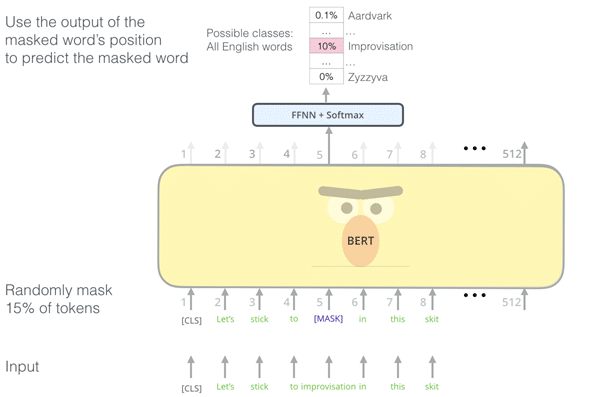
The most important technical innovation of BERT is masked language modelling (MLM).
The technique enables bidirectional training using the same information flow as in the original Transformer Encoder. As it showed the best performance in a number of benchmarks at the time, it generated a lot of attention among experts in natural language processing.
In the illustration below you can see an example of how one of the words, w4, is masked. Then the model has to guess: What is the actual token in the given context? Only 15 % of the words in a sequence are replaced for training BERT, randomly with one of the following options:
- 80 % are replaced by a special mask token ("[MASK]") which signals to the model that a word has been "hidden".
- 10 % with a random word
- 10 % with the original word
In addition, BERT is pre-trained with the prediction of the next sentence (NSP). It is comparable to MLM, but at the level of the whole sentence. BERT is given a pair of sentences and is asked to predict whether the second sentence belongs to the context of the first or not. In 50 per cent of the cases, the second sentence is replaced by a random sentence.
By combining MLM and NSP, BERT can learn a bidirectional representation of the entire sequence that delivers top results in benchmarks.
OpenAI GPT
GPT (generatively pre-trained transformer) and its successors, GPT-2 and GPT-3, are the most popular transformer architectures alongside BERT. Researchers from the OpenAI Institute presented them in a paper around the same time as BERT. This presented benchmark results that are comparable to those of BERT.
Unlike BERT, GPT uses the decoder part of the transformer. Therefore, it is pre-trained by causal language modelling (CLM). GPT learns to predict what the next word is for a given context. This type of language modelling produces degraded performance, but it could be used in classification tasks, for example. However, GPT excels in generating very natural-sounding texts that often give the impression of having been written by a human.
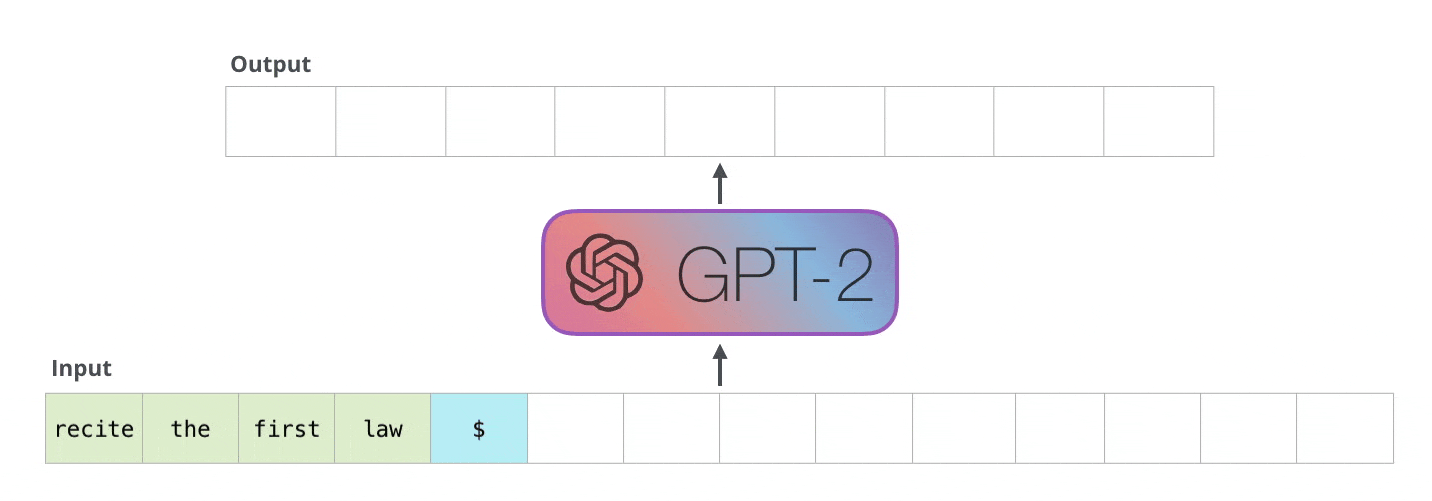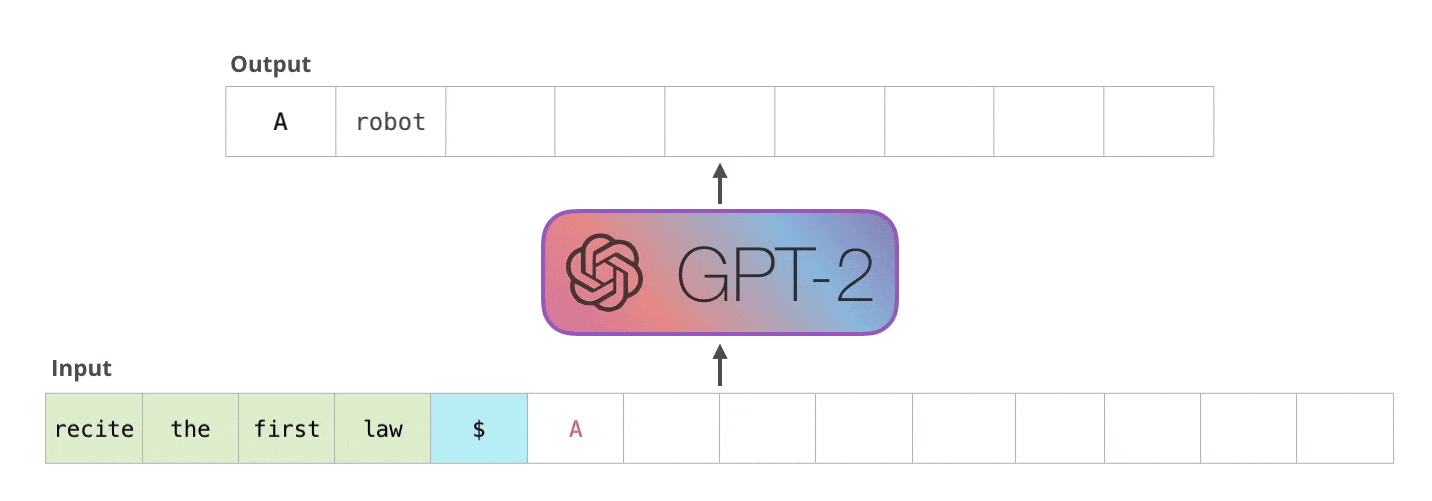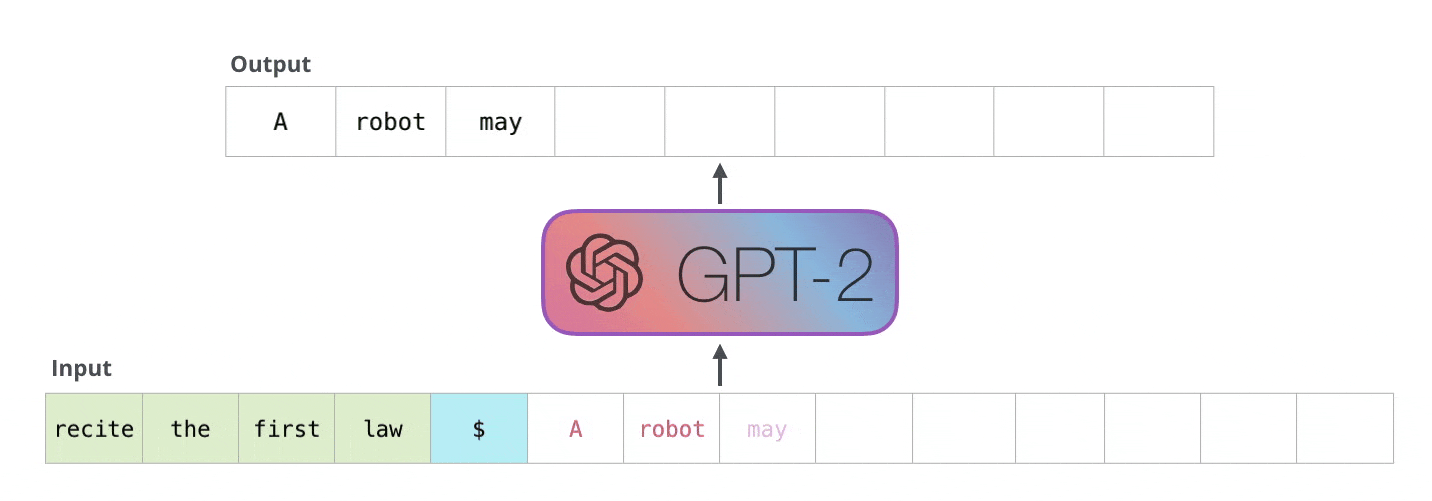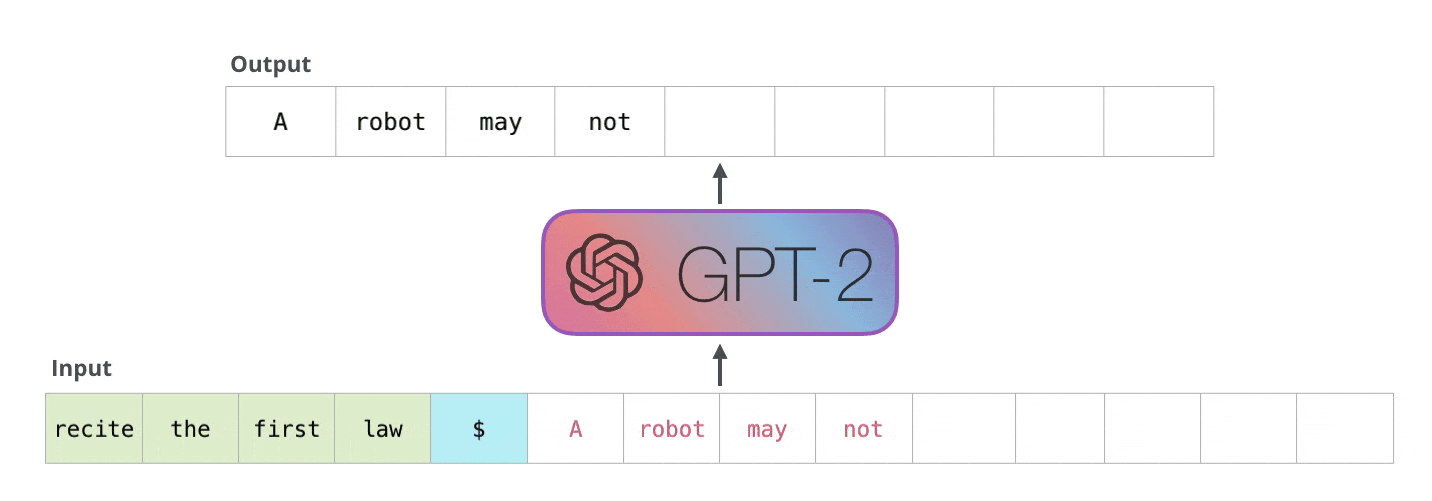
For ethical and security reasons, the OpenAI research team did not initially release resources to reproduce their work. The most recent version is GPT-3 with a total of 175 billion parameters - read our blog post on this.
Conclusion
We have given an overview of the first transformers, compared them with earlier approaches such as RNNs and distinguished them from each other. In the next part of our series, we will introduce the second wave of transformers, their new architectural additions and their advantages.








0 Kommentare