MLOps Platform
Building, Scaling and Operationalising
- Published:
- Author: Kai Sahling
- Category: Deep Dive
Table of Contents

In the previous article, we saw how important it is to get involved with MLOps at an early stage. MLOps platforms help to reduce manual steps, increase team collaboration, comply with regulatory and compliance requirements, and reduce time-to-market.
Given the complexity of the topic and the numerous tools available, the question arises: Where to start? Not every tool is equally important, and some are only relevant for teams of a certain size. The following process model is therefore intended to provide guidance. It offers four stages of development: Prerequisites, Foundation, Scale, Mature. The fundamentals of software engineering and data engineering are given the highest priority, enabling even teams with little ML experience to get started easily. With each level, more and more complex products based on ML can be created and, above all, operated.
Challenges of Local ML Models
The simplest way to operate an ML model is to train a model locally and store it in object storage. A (recurring) job accesses the model and applies it to a data set. The results are stored in a database or as a file. This approach may be fast, but it carries numerous risks and is not suitable for scaling. In addition to the threat of data protection violations in many cases, performing training and data preparation locally significantly complicates teamwork. Team members cannot view the training process. They cannot access training details and continue development. This results in time-consuming new developments. In the event of incorrect predictions, these cannot be traced because, without versioning, it is not possible to trace which model version was used and when. Audits1 of models with regard to the data used, legal or ethical issues are therefore impossible. There is also a high risk of using faulty models, as tests cannot be applied automatically. In addition, training is limited by the computing power of the local system, which is insufficient for some use cases.
The Basics of ML Operationalization
Focus:
- Versioning
- CI/CD
- Python scripts instead of notebooks

In the first stage of development, the fundamentals of modern software engineering and data engineering are implemented. These include versioning, testing, and deployment pipelines. Code versioning enables the traceability of changes and simultaneous collaboration between multiple developers. Models are also versioned in the same way as code. Deployment pipelines create the training job and initiate it. To this end, model training is no longer performed in Jupyter Notebooks or as a Python script, but as a single job. The code for the training job is versioned and the job is provided via CI/CD pipelines. The CI/CD pipelines make it possible to perform automated tests. These tests help to catch errors before model training is started, enabling faster further development of the model or the training job. The trained model is stored and versioned in a model registry. The ML service for prediction is also deployed via a CI/CD pipeline together with the model. The deployment of a new model is still done manually, i.e., a developer checks the quality of the new model using performance metrics. The ML service is usually either an API that provides a prediction on request or a batch job that calculates predictions at intervals. Here, too, tests can be performed again with the model. Plausibility checks, among other things, are suitable for this purpose.
The focus on the use of established tools such as CI/CD pipelines and tests makes it possible to quickly achieve a higher degree of automation and greater reliability.
Basis of an MLOps Platform
Focus:
- Data catalog
- ML pipelines
- Experiment tracking

In the second stage of development, model training is to be made reusable and further automated through the use of pipelines. In addition, data management should be set up at an early stage in order to maintain an overview of various data sources.
Pipelines enable the orchestration of all steps relevant to model training, as well as the decoupling of these steps. Previously, complex ML jobs can be divided into smaller steps and combined in pipelines. The steps are thus easier to understand, maintain, and can be exchanged. This allows them to be reused across different pipelines or easily shared via templates. Each step can also be executed with dedicated computing capacity such as GPUs or RAM. This means that only the resources that are actually needed can be provided, reducing costs. Conversely, training can be scaled by making more resources available. The steps are also created via a CI/CD pipeline, where they can be tested automatically. The tests can also cover regulatory requirements. Tests that recognize personal data in the training data set would be possible.
In addition, the metadata of the model training, such as model configuration and performance, also known as experiment tracking, is now recorded. These are tracked during training and stored in a metadata store. This allows team members to see at any time which models have already been trained and how they were evaluated.
Data management is handled via a data catalog. No dedicated tool is required for this. Often, an overview in a spreadsheet or in Confluence is sufficient. It is crucial to create this early on, as this also enhances reusability. With regard to compliance requirements, it may also be necessary to document which data is used by ML products. By describing data sources, including their business context in particular, developers can quickly assess whether the data is suitable for a model. This prevents data from having to be re-evaluated repeatedly.
Focus on Scaling
Focus:
- Automated deployment
- Monitoring
- Alerting
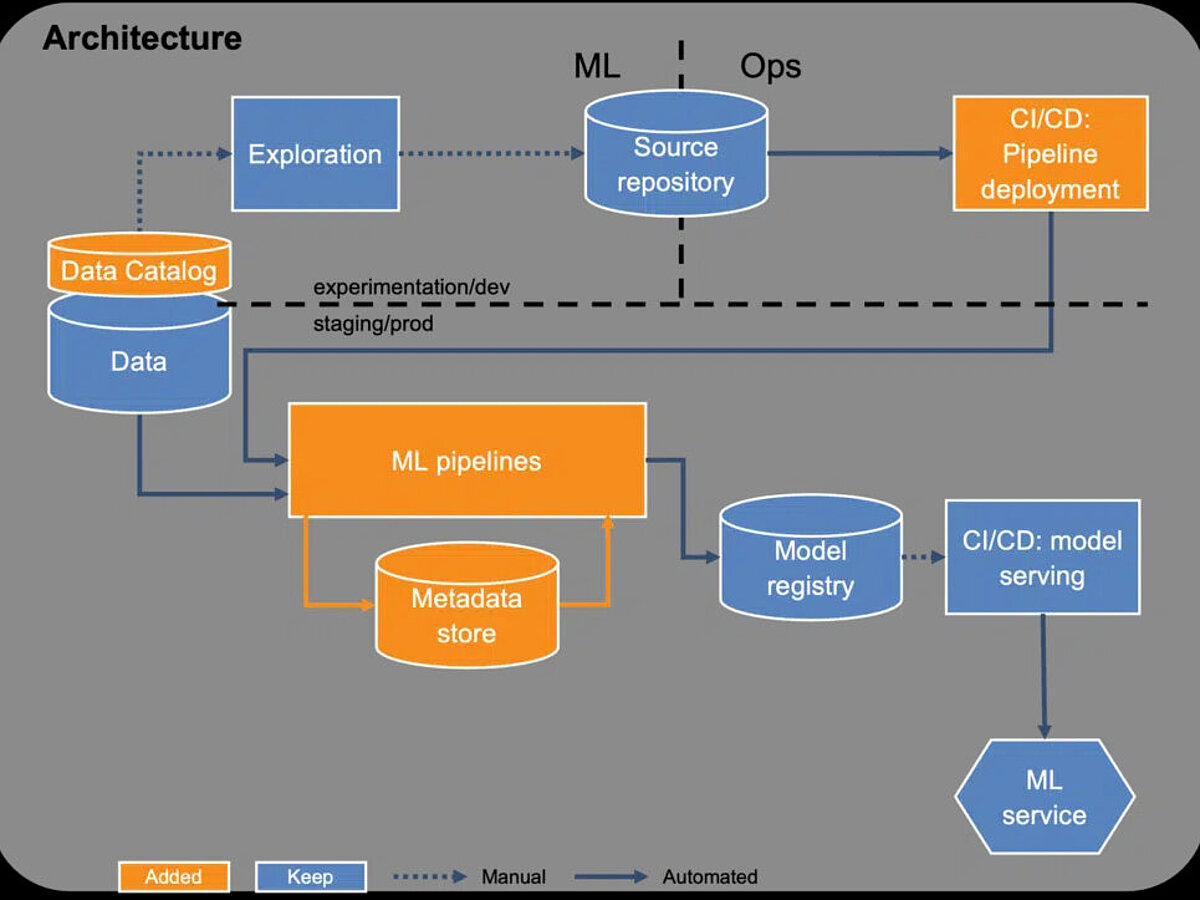
The third stage of development is intended to make it easier for teams to operate multiple products. To achieve this, manual intervention in the system must be reduced. Model deployment is now carried out automatically. Each trained model is compared with the model currently in production, known as the champion model. If a newly trained model is better than the champion model, the new model automatically becomes the new champion model and is made available. It is important to further expand automated testing. Fairness tests, such as evaluating model performance for specific user groups, should also be carried out. This prevents models that outperform the previous champion model overall but have a negative impact on customer groups that require special consideration from going into production. In view of the European Act on AI, such tests could become mandatory.
In addition, the expansion of monitoring is crucial. The performance of a model should be monitored at all times. To do this, all predictions are recorded together with the input data. The prediction quality can then be determined by comparing it with the actual values. The effort required to obtain the actual values depends heavily on the use case. Time series predictions are self-evident, while the classification of images requires manual work. Depending on the number of predictions, the actual values can only be determined for a sample. This allows the performance of the model to be monitored over time. In addition, it is advisable to perform simple plausibility checks. If a probability is predicted, it must be between 0 and 1. If anomalies are detected, a warning is issued to notify developers. The better the tests and alerts, the faster developers can fix errors.
The Modular Principle as Best Practice
Focus:
- Easier reusability
- Greater automation
- More tests

The latest release further enhances the automation and reusability of the platform. Packages are used instead of templates for pipelines. Each step is represented by a package that can be installed via pip, for example. This makes it easy to perform updates and keep pipelines up to date over a long period of time. A feature store can also help to further increase reusability. This allows features for model training to be shared across teams.
In addition to further tests for monitoring the model in production, the handling of alerts is being further automated. Instead of manually triggering a new model training after an alert, training is now started automatically.
Conclusion
For ML products to be successful, it is crucial to consider operationalization from the outset. This process model is intended to provide an easy introduction to an advanced ML infrastructure. In view of the upcoming European Act on AI, such an infrastructure is necessary. Only then can automated controls and tests be carried out, as is likely to be mandatory for high-risk systems2. Without these capabilities to monitor models and control their results, the use of machine learning in critical areas will no longer be permitted.
If you also want to make your machine learning use cases fit for regulatory requirements or bring your use cases into production faster, we are happy to support you. We carry out target/actual analyses with you, develop a plan based on your needs to close any gaps, and support you with implementation and maintenance.
1 Auditing models gives an organization the opportunity to systematically check the models used for risks. The CRISP-DM framework is a useful guide for this. Legal and ethical risks in particular must be carefully examined.
2 The European Act on AI divides AI use cases into four risk levels: unacceptable risk, high risk, limited risk, and minimal risk. High-risk systems are subject to strict requirements before they can be brought to market. Fully automated credit application screening, among other things, falls under high risk.
Share this post: