MLOps Plattform – Aufbau, Skalierung und Operationalisierung
- Veröffentlicht:
- Autor: Kai Sahling
- Kategorie: Deep Dive
Inhaltsverzeichnis

Im vorherigen Beitrag haben wir gesehen, wie wichtig es ist, sich bereits frühzeitig mit MLOps zu beschäftigen. MLOps-Plattformen helfen, manuelle Schritte zu reduzieren, die Zusammenarbeit der Teams zu steigern, Vorgaben aus Regulatorik und Compliance einzuhalten und die Time-to-Market zu reduzieren.
Aufgrund der Komplexität des Themas und der zahlreichen Tools stellt sich die Frage: Womit anfangen? Nicht jedes Tool ist gleich wichtig und manches ist erst aber einer gewissen Teamgröße relevant. Das folgende Vorgehensmodell soll deshalb eine Orientierung geben. Es bietet vier Ausbaustufen an: Prerequisites, Foundation, Scale, Mature. Grundlagen des Software-Engineerings und Data Engineerings erhalten die höchste Priorität und ermöglichen somit auch Teams mit wenig ML-Erfahrung einen einfachen Start. Mit jeder Stufe können dabei mehr und komplexere Produkte auf Basis von ML geschaffen und vor allem betrieben werden.
Herausforderungen lokaler ML-Modelle
Das einfachste Vorgehen, ein ML-Modell zu betreiben, ist ein Modell lokal zu trainieren und in einem Object Storage abzulegen. Ein (wiederkehrender) Job greift das Modell auf und wendet es auf einen Datensatz an. Die Ergebnisse werden in einer Datenbank oder als Datei abgespeichert. Dieses Vorgehen mag schnell sein, birgt jedoch zahlreiche Risiken und eignet sich nicht zur Skalierung. Das lokale Ausführen von Training und Datenaufbereitung ist, neben des in vielen Fällen drohenden datenschutzrechtlichen Verstoßes, erschwert deutlich die Zusammenarbeit in Teams. Die Ausführung des Trainings ist für Teammitglieder nicht einsehbar. Diese können nicht auf Details des Trainings zugreifen und die Entwicklung fortsetzen. Zeitintensive Neuentwicklungen sind die Folge. Im Falle von fehlerhaften Vorhersagen können diese nicht nachvollzogen werden, da ohne eine Versionierung nicht nachvollziehbar ist, welche Modellversion wann eingesetzt wurde. Audits1 von Modellen hinsichtlich der verwendeten Daten, rechtlichen oder ethischen Fragestellungen sind damit unmöglich. Auch besteht ein hohes Risiko fehlerhafte Modelle zu verwenden, da Tests nicht automatisch angewandt werden können. Zudem ist das Training durch die Rechenleistung des lokalen Systems beschränkt, so dass diese für manche Anwendungsfälle nicht ausreichend ist.
Die Grundlagen der ML-Operationalisierung
Fokus:
- Versionierung
- CI/CD
- Python-Skripte statt Notebooks
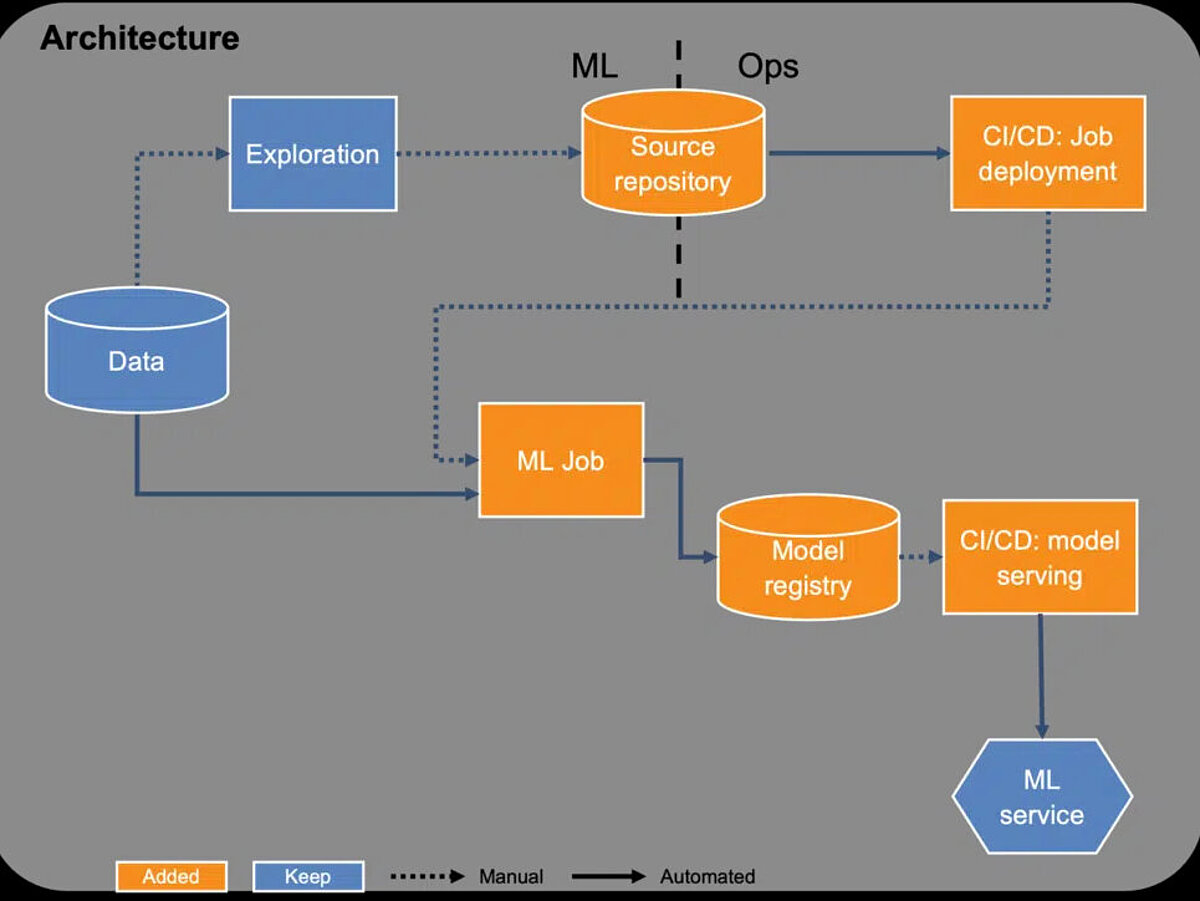
In der ersten Ausbaustufe werden Grundlagen des modernen Software Engineerings und Data Engineerings umgesetzt. Das sind Versionierung, Tests und Deployment-Pipelines. Versionierung von Code ermöglicht die Rückverfolgbarkeit von Änderungen und die gleichzeitige Zusammenarbeit mehrerer Entwickler. Modelle werden analog zum Code ebenfalls versioniert. Deployment-Pipelines erstellen den Trainingsjob und stoßen diesen an. Dazu wird das Modelltraining nicht mehr in Jupyter Notebooks oder als Python-Skript ausgeführt, sondern als einzelner Job. Der Code für den Trainingsjob wird versioniert und der Job über CI/CD Pipelines bereitgestellt. Die CI/CD Pipelines schaffen die Möglichkeit, automatisiert Tests durchzuführen. Diese Tests helfen, Fehler abzufangen bevor das Modelltraining gestartet wird, um damit schneller das Modell oder die den Trainingsjob weiterzuentwickeln. Das trainierte Modell wird in einer Model Registry abgespeichert und versioniert. Der ML-Service für die Vorhersage wird ebenfalls über eine CI/CD Pipeline zusammen mit dem Modell bereitgestellt. Die Bereitstellung eines neuen Modells erfolgt dabei noch manuell, d.h. ein Entwickler kontrolliert die Qualität des neuen Modells anhand von Performancemetriken. Bei dem ML-Service handelt es sich meist entweder um eine API, die auf Abfrage eine Vorhersage liefert, oder um einen Batch-Job, der in einem Intervall Vorhersagen berechnet. Auch hier können nochmals Tests mit dem Modell durchgeführt werden. Dafür bieten sich u.a. Plausibilitätschecks an.
Der Fokus auf den Einsatz von etablierten Tools wie CI/CD Pipelines und Tests ermöglicht es, schnell einen höheren Automatisierungsgrad und eine größere Verlässlichkeit zu erzielen.
Entdecken Sie, was es mit MLOps auf sich hat, wie diese Methode den operativen Betrieb von Machine Learning-Anwendungen beeinflusst, welche Unterschiede es zu DevOps gibt und wie ML-Produkte dazu beitragen können, Herausforderungen in Ihrem Unternehmen zu bewältigen.
Warum MLOps? Die 5 Herausforderungen der ML-Produktentwicklung
Basis einer MLOps-Plattform
Fokus:
- Data Catalog
- ML Pipelines
- Experiment Tracking
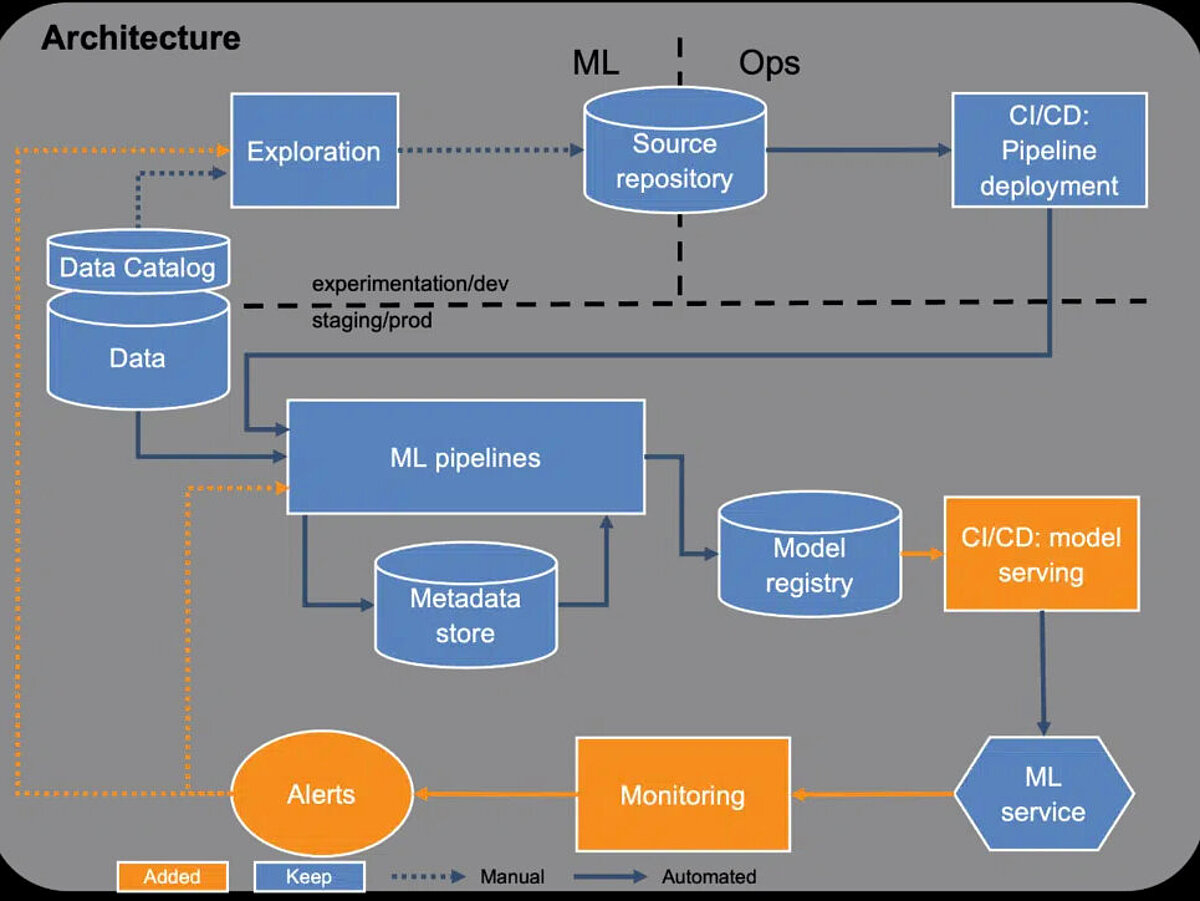
In der zweiten Ausbaustufe soll das Modelltraining durch den Einsatz von Pipelines wiederverwendbar gestaltet und weiter automatisiert werden. Außerdem sollte frühzeitig ein Datenmanagement aufgesetzt werden, um den Überblick über verschiedene Datenquellen zu behalten.
Pipelines ermöglichen einerseits die Orchestrierung von allen für das Modelltraining relevanten Schritten als auch die Entkopplung dieser Schritte. Zuvor komplexe ML-Jobs können in kleinere Schritte unterteilt und in Pipelines zusammengefasst werden. Die Schritte sind damit einfacher zu verstehen, zu warten und können ausgetauscht werden. Dadurch können diese über verschiedene Pipelines wiederverwendet oder über Templates einfach geteilt werden. Auch kann jeder Schritt mit dedizierter Rechenkapazität wie GPUs oder Arbeitsspeicher ausgeführt werden. So können nur die tatsächlich benötigten Ressourcen bereitgestellt werden, um Kosten zu reduzieren. Umgekehrt lässt sich so das Training skalieren, indem mehr Ressourcen zur Verfügung gestellt werden. Die Schritte werden ebenfalls über eine CI/CD Pipeline erstellt, worin diese automatisiert getestet werden können. Durch die Tests können auch regulatorische Anforderungen abgedeckt werden. Möglich wären Tests, die personenbezogene Daten im Trainingsdatensatz erkennen.
Außerdem werden nun die Metadaten des Modelltrainings wie Modellkonfiguration und -performance erfasst, auch bekannt als Experiment Tracking. Diese werden während des Trainings getrackt und in einem Metadata Store abgespeichert. Damit können Teammitglieder jederzeit nachvollziehen, welche Modelle bereits trainiert und wie diese bewertet wurden.
Das Datenmanagement erfolgt über einen Data Catalog. Dafür muss kein dezidiertes Tool verwendet werden. Oft genügt eine Übersicht in einem Spreadsheet oder in Confluence. Entscheidend ist, dies frühzeitig anzulegen, da dies auch die Wiederverwendbarkeit stärkt. Auch im Hinblick auf Compliancevorgaben kann es notwendig sein zu dokumentieren, welche Daten von ML Produkten verwendet werden. Durch eine Beschreibung von Datenquellen, die insbesondere auch deren Business-Kontext umfasst, können Entwickler schnell bewerten, ob die Daten für ein Modell geeignet sind. Dies verhindert, dass Daten immer wieder neu ausgewertet werden müssen.
Skalierung im Fokus
Fokus:
- Automated Deployment
- Monitoring
- Alerting
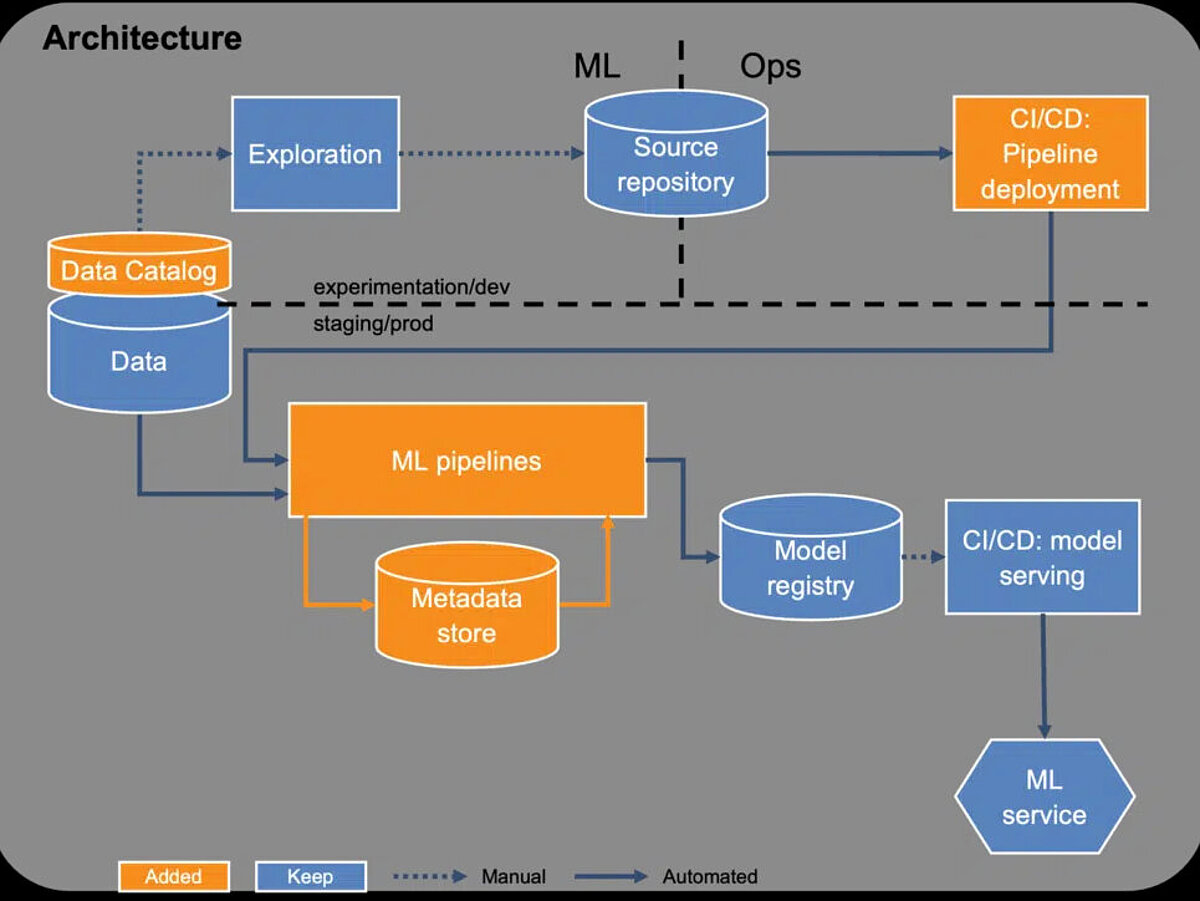
Die dritte Ausbaustufe soll Teams erleichtern, mehrere Produkte zu betreiben. Dazu müssen vor allem manuelle Eingriffe in das System reduziert werden. Hierfür erfolgt das Modelldeployment nun automatisch. Jedes trainierte Modell wird mit dem aktuell in Produktion befindlichen Modell verglichen, das sogenannte Championmodell. Ist ein neu trainiertes Modell besser als das Championmodell, so wird das neue Modell automatisch zum neuen Championmodell und zur Verfügung gestellt. Dabei ist es wichtig, die automatisierten Tests weiter auszubauen. Auch Tests auf Fairness wie die Evaluation der Modellperformance für bestimmte Nutzergruppen, sollten durchgeführt werden. Damit kann verhindert werden, dass Modelle, die insgesamt das bisherige Championmodell schlagen aber sich negativ auf besonders zu berücksichtigende Kundengruppen auswirken, in Produktion kommen. Mit Blick auf den European Act on AI könnten solche Tests verpflichtend werden.
Darüber hinaus ist der Ausbau des Monitorings entscheidend. Die Performance eines Modells soll zu jeder Zeit überwacht werden. Dazu werden alle Vorhersagen zusammen mit den Inputdaten erfasst. Damit kann dann über den Abgleich mit den tatsächlichen Werten die Vorhersagequalität ermittelt werden. Der Aufwand, die tatsächlichen Werte zu erhalten ist stark abhängig vom Use Case. Vorhersagen von Zeitreihen ergeben sich von allein, während die Klassifikation von Bildern manuelle Arbeit erfordert. Abhängig von der Anzahl der Vorhersagen können nur für eine Stichprobe die tatsächlichen Werte ermittelt werden. Damit lässt sich die Performance des Modells im Zeitverlauf kontrollieren. Daneben empfiehlt es sich, einfache Plausibilitätschecks durchzuführen. Wird eine Wahrscheinlichkeit vorhergesagt, muss diese zwischen 0 und 1 liegen. Bei Auffälligkeiten wird eine Warnung ausgespielt, um Entwicklern zu benachrichtigen. Je besser die Tests und Alerts, desto schneller können Entwicklern Fehler beheben.
Das Baukasten-Prinzip als Best Practice
Fokus:
- Einfachere Wiederverwendbarkeit
- Stärkere Automatisierung
- Mehr Tests
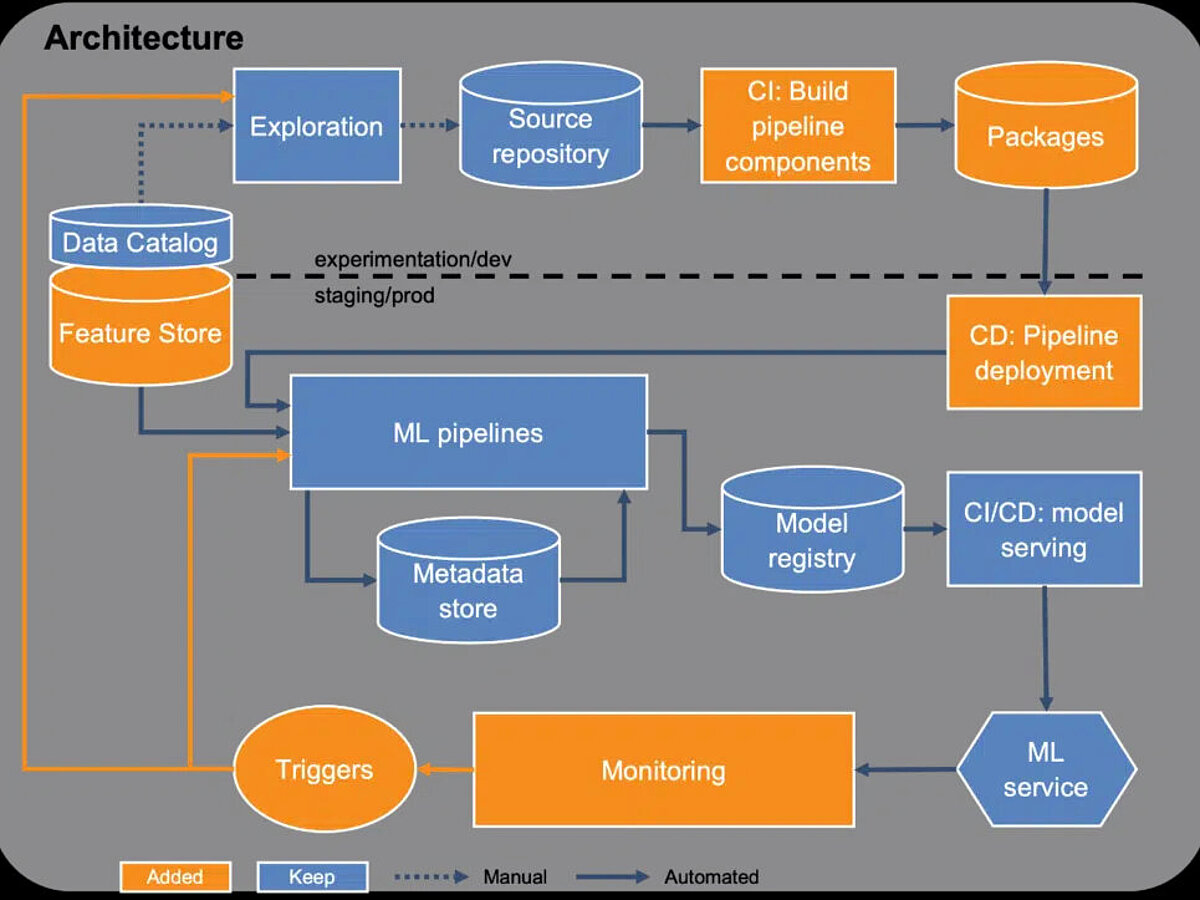
Die letzte Ausbaustufe stärkt weiter die Automatisierung und Wiederverwendbarkeit der Plattform. Für die Pipelines werden Packages verwendet, statt Templates. Jeder Schritt wird über ein Package dargestellt, das z. B. über pip installiert werden kann. Dadurch können Updates leicht durchgeführt und Pipelines auch über einen langen Zeitraum aktuell gehalten werden. Auch ein Feature Store kann dabei helfen, die Wiederverwendbarkeit weiter zu steigern. So werden Features für das Modelltraining über Teams hinweg geteilt.
Neben weiteren Tests für die Kontrolle des Modells in Produktion, wird der Umgang mit Alerts stärker automatisiert. Statt ein neues Modelltraining nach einem Alert manuell anzustoßen, wird das Training jetzt automatisch gestartet.
Fazit
Für den Erfolg von ML-Produkten ist es entscheidend, die Operationalisierung von Anfang an mitzudenken. Dieses Vorgehensmodell soll einen einfachen Einstieg hin zu einer fortgeschrittenen ML-Infrastruktur bieten. Angesichts des bevorstehenden European Act on AI ist eine solche Infrastruktur notwendig. Nur damit können automatisiert Kontrollen und Tests durchgeführt werden, wie es voraussichtlich für Hochrisikosysteme2 verpflichtend sein wird. Ohne diese Fähigkeiten, Modelle zu überwachen und deren Ergebnisse zu kontrollieren, wird der Einsatz von Machine Learning in kritischen Bereichen nicht mehr zulässig sein.
Wenn auch Sie Ihre Machine Learning Use Cases fit für regulatorische Anforderungen machen oder Sie Ihre Use Cases schneller in Produktion bringen wollen, unterstützen wir Sie gerne. Wir führen mit Ihnen Soll-Ist-Analysen durch, entwickeln basierend auf Ihren Bedürfnissen einen Plan, um mögliche Lücken zu schließen und unterstützen Sie bei der Implementierung und Wartung.
1 Die Auditierung von Modellen bietet einer Organisation die Möglichkeit, systematisch die verwendeten Modelle auf Risiken zu überprüfen. Dabei eignet sich das CRISP-DM Framework als Orientierung. Insbesondere rechtliche und ethische Risiken sind sorgfältig zu prüfen.
2 Der European Act on AI unterteilt Anwendungsfälle für KI in vier Risikostufen: inakzeptables Risiko, hohes Risiko, begrenztes Risiko und minimales Risiko. Systeme mit hohem Risiko unterliegen strengen Vorgaben, bevor sie auf den Markt gebracht werden dürfen. Die vollautomatisierte Prüfung von Kreditanträgen fällt u.a. unter hohes Risiko.
Diesen Beitrag teilen: