Large Language Diffusion Models
An introduction
- Published:
- Author: [at] Editorial Team
- Category: Basics
Table of Contents

Large language diffusion models (LLaDAs) introduce a novel paradigm wherein language models think more like humans. The models employ a distinct approach to text generation compared to large language models (LLMs). To put it into perspective, LLMs such as ChatGPT and Llama are autoregressive models (ARMs) that predict text sequentially from left to right. LLaDAs, on the other hand, use a diffusion-like process for text generation, in which words appear randomly and can also be edited or deleted.
In this article, we will explore the origins of LLaDAs, what distinguishes them from LLMs, their functioning, and their practical applications in real-world industry setups. To begin, we'll briefly review the fundamentals of diffusion models before turning to their adaptation for text generation.
What are Diffusion Models?
Diffusion models are generative models that originally became known through applications of image synthesis, such as in Stable Diffusion or DALL·E 3. They work by gradually adding noise to data and then learning the reverse process to reconstruct a structured target object from pure noise. This principle of successive noise removal forms the conceptual basis for diffusion-based language models, in which the same mechanism is applied not to pixels but to textual representations.

Diffusion-based language models refine entire text phrases iteratively at once, unlike LLMs that predict words sequentially, one by one. This shift to text brings a new process: starting with a rough, noisy version of a passage, the model refines it over multiple steps. Because the model considers the entire sentence at once, it can generate output more quickly and coherently than LLMs. Understanding this difference sets the stage for examining LLaDAs specifically.
What are Large Language Diffusion Models?
Large Language Diffusion Models (LLaDAs) are a class of generative language models that apply the diffusion-based approach to textual representations, thus representing an alternative architecture to autoregressive Large Language Models (LLMs). Unlike LLMs, which generate tokens sequentially from left to right and thus have limitations when it comes to reversal tasks or complex, multi-step thinking, LLaDAs use a bidirectional reconstruction process. This approach addresses key limitations of classic LLMs.
LLaDAs demonstrate high scalability and strong performance in areas such as language comprehension, mathematics, code generation, and Chinese-language tasks. Models such as LLaDA 8B achieve a level of performance in in-context learning comparable to LLaMA 3 8B and have strong abilities to follow instructions across multiple rounds of dialogue.
One of the first commercially relevant applications is Inception Labs' Mercury Coder, which applies the diffusion-based approach to code generation and occupies a leading position in the field of AI-powered development tools.
Large Language Diffusion Models vs Large Language Models
To better understand their respective roles, this section delves into the differences between LLaDAs and LLMs and the advantages LLaDAs offer over autoregressive LLMs, especially in use cases such as text generation, code completion, and dialogue systems:
| Aspect | Large Language Diffusion Models | Large Language Models |
|---|---|---|
| Text generation | Large language diffusion models are more suitable for long-form texts where consistency and coherence is critical. It's because the models are capable of drafting texts and refining it iteratively. | Large language models are strong at summaries and short texts, but struggle with long, logically structured reports. Since they generate word by word, they easily lose track of previous passages, leading to breaks and inconsistencies. |
| Code completion | LLaDAs can iteratively refine entire blocks of code by mimicking typical developer workflows during writing, testing, and correction. This reduces post-processing effort and increases productivity in companies. | LLMs generate common code patterns well and are therefore suitable for short snippets. However, if errors need to be corrected retrospectively, a step-by-step correction approach usually fails. |
| Dialogue systems | Large language diffusion models are capable of on-topic, and reliable dialogue, making them suitable for customer facing and compliance sensitive industries. Its iterative refinement allows the system to adjust responses as per context. | LLMs are great for short, low-stake conversations, but they can “hallucinate” during customer support or in professional contexts. Hallucination can lead to misunderstandings and fabricated answers. |
LLaDAs: Architecture, Model Training, and Technical Limitations
Large Language Diffusion Models (LLaDAs) combine diffusion models’ capabilities with those of LLMs. These models generate text by learning language distribution through a diffusion process. The model uses a forward data masking process and a reverse process for model distribution and text generation. Let’s examine this in detail, with examples. We will then briefly review LLaDAs training process and the technical limitations it poses.
Forward Process
The model begins with a sequence of tokens, such as words or characters, and gradually masks them independently until the sequence is fully masked. The masking probability increases linearly with time. For example, at t = 0, no tokens are masked, while at t = 1, all tokens are masked. Here’s how this works:
At t=0.5, some tokens are masked randomly:
Masked sentence:
At t=1.0, all tokens are masked:
Reverse Process
This process recovers the original sequence from the fully masked sequence. It predicts and unmasks tokens iteratively, moving from t = 1 back to t = 0. A mask predictor, usually a transformer model, predicts the masked tokens based on partially masked sequences.
Given the same sentence, at t = 1, when the sentence is fully masked:
At t=0.5, when the sentence is partially masked:
At t=0, when the sentence is not masked at all:
In this way, the model successfully reconstructs the original sentence.
Training Phases of LLaDAs
Pretraining
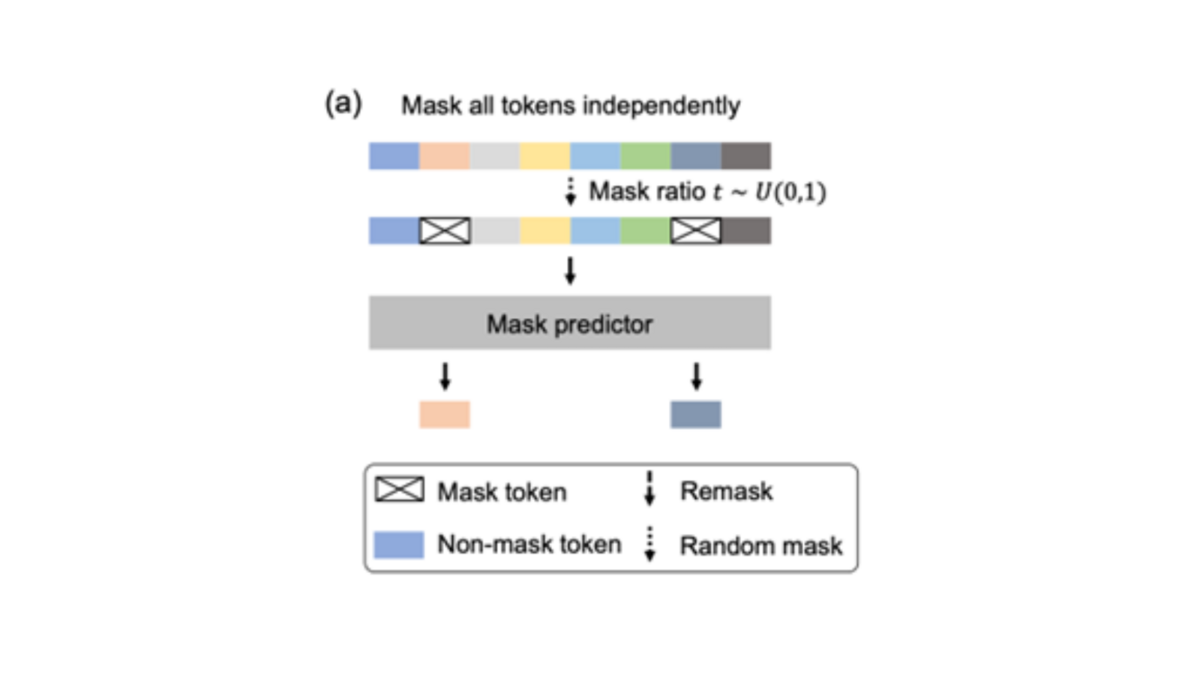
As depicted in image a), there is a sample sequence from the training set at the top. The mask ratio t, with a value between 0 and 1, is randomly sampled. For each token, it's randomly decided whether it should be masked or not. The result is a partially masked token sequence. This partially masked sequence is fed into the masked predictor. The mask predictor is a transformer model trained to restore the masked tokens. It learns to associate the context of unmasked tokens with the correct masked tokens.
Supervised Fine-tuning
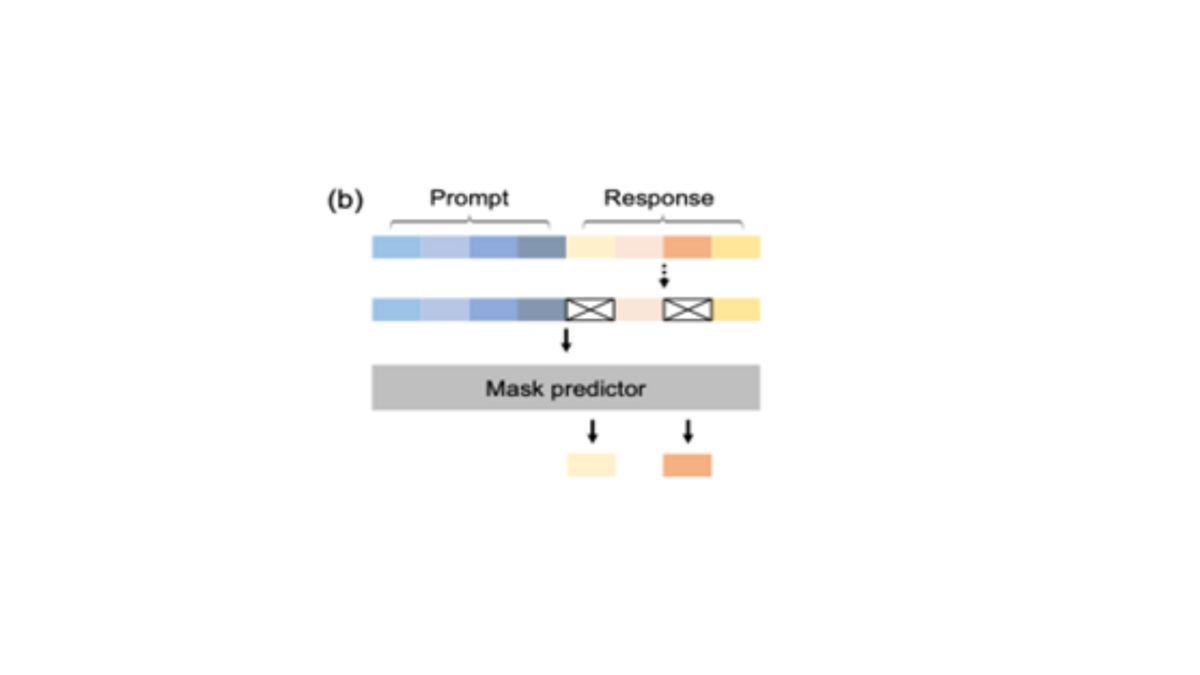
This phase enhances large language diffusion model's ability to follow instructions. As illustrated in b), there’s a prompt and a response at the top. The goal is to train the model to generate a response in response to the given prompt. Similar to pretraining, some of the tokens in the sample are randomly masked. Though this time, only the tokens from the response are masked while those in the prompt remain unmasked. Then, the prompt and the partially masked response are fed to the mask predictor with the aim of recovering the masked tokens from the response.
Sampling
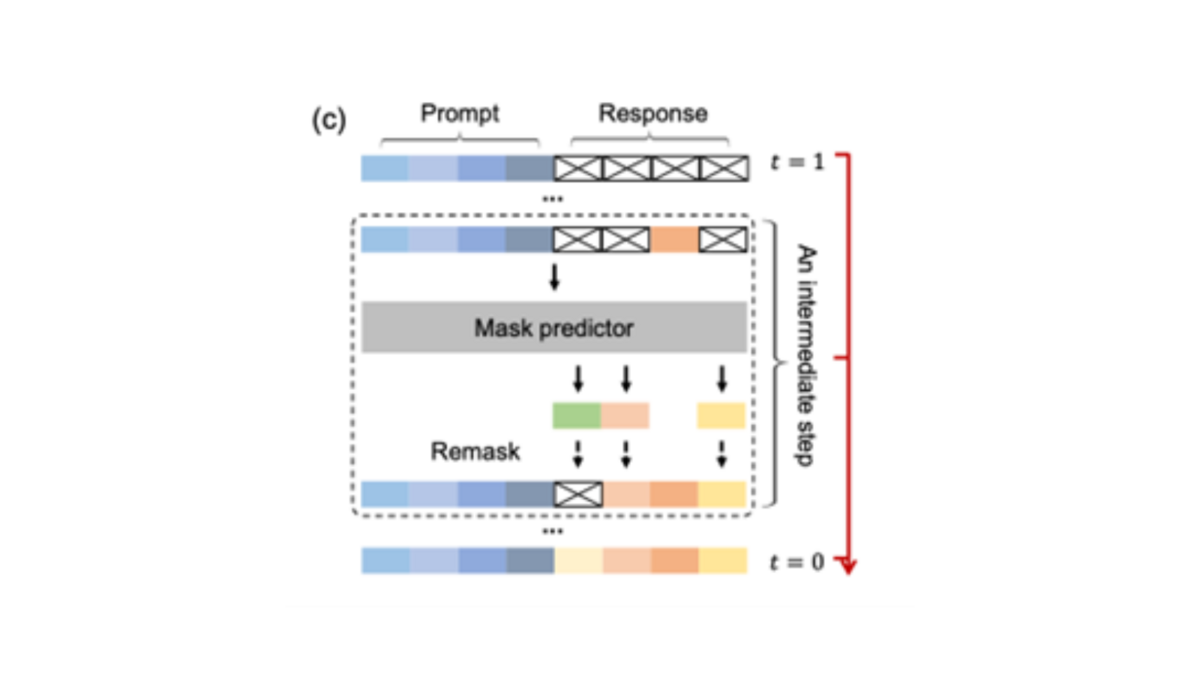
As depicted in c), the diffusion process in LLaDAs begins with a fully masked sequence (t = 1) and gradually unmasks tokens to recover the original sequence (t = 0). The model predicts all masked tokens simultaneously at each step of the diffusion process. The model’s ability to deploy different strategies to decide which tokens to remask at each step enables more flexible and context-aware text generation.
Technical Limitations and Peculiarities
Large Language Diffusion Models perform well in reversal tasks and beats its competitors, such as GPT-4. However, its performance lags in some general tasks compared to LLMs such as LLaMA3 8B and Qwen2.5 7B.
LLaDAs require 2-10x more compute than LLMs, which prevents their immediate widespread adoption.
LLaDAs training requires careful tuning of noise schedules, loss weighting, and regularization strategies, making the complexity needing workarounds.
Long-Term Efficiency Outlook
Given the current technical limitations of LLaDAs, such as heavy computational requirements and training complexity, it's not currently suitable for large-scale models in enterprises. Perhaps in the future, a hybrid approach that combines the strengths of autoregressive and diffusion models might be more suitable at the enterprise level.
Use Cases
Large language diffusion models open up a wide range of possible applications in the corporate environment. In software development, they can significantly speed up code generation and debugging, as systems such as Mercury Coder already demonstrate. Their ability to process tokens in parallel and iteratively also makes them suitable for use on mobile devices or edge systems where computing resources are limited. In knowledge-intensive areas, LLaDAs assist in the creation, refinement, and review of reports, guidelines, or compliance documents. They are also used in the creative industries, for example, for marketing texts, advertising scripts, or long narrative formats that require both creativity and factual accuracy.
The potential of the models lies in particular in their high reliability and coherence: Iterative refinement reduces hallucinations, smooths out logical breaks, and improves structural consistency across longer texts and dialogues. At the same time, inference time is reduced because tokens are generated in parallel rather than sequentially. Since LLaDAs view text holistically rather than word by word, they are also better able to grasp complex relationships and draw more plausible conclusions.
At the same time, the use of these models is associated with challenges. A pronounced talent gap makes recruitment and training difficult. Iterative refinement steps can lead to increased latency, which is particularly relevant in time-critical business applications. Technical integration is challenging, as existing LLM pipelines are mostly designed for autoregressive architectures. In addition, the ecosystem surrounding LLaDAs – from tools to pre-trained models – is still relatively immature.
The shift from autoregressive to diffusion-based models has far-reaching implications for enterprise infrastructures. The introduction of LLaDAs initially incurs high costs, as multi-stage inference processes entail increased GPU/TPU requirements. Established quality assurance processes also need to be revised because models are increasingly self-correcting, which can shift roles and responsibilities. Existing pipelines optimized for sequential decoding need to be fundamentally adapted to iterative refinement workflows. In addition, the change in working methods is leading to cultural changes: Employees must understand the transition from multiple design stages to near-final AI results and shift their role more toward strategic control and evaluation.
Overall, LLaDAs offer significant opportunities for efficiency and quality in operational processes – but at the same time require companies to make technical, organizational, and cultural adjustments in order to fully exploit their potential.
Conclusion
Large language diffusion models (LLaDAs) represent a fundamental shift in language generation architecture and offer compelling advantages in code generation, long-form document creation, and dialogue consistency. However, the high computational costs and integration complexity make them incompatible for enterprise adoption. Enterprises interested in adopting LLaDAs should begin pilot programs to build expertise. Eventually, LLaDAs will claim a larger role in enterprise AI when the cost-performance ratio improves.
Further reading
- Data Science Collective. “LLaDA Explained: How Diffusion Could Revolutionize Language Models.” Medium, 2025, https://medium.com/data-science-collective/llada-explained-how-diffusion-could-revolutionize-language-models-950bcce4ec09.
- Hugging Face. “Diffusion Language Models: The New Paradigm.” Hugging Face Blog, 10 June 2025, https://huggingface.co/blog/ProCreations/diffusion-language-model.
- Kellogg, Tim. “LLaDA: LLMs That Don’t Gaslight You.” Tim Kellogg Blog, 17 February 2025, https://timkellogg.me/blog/2025/02/17/diffusion.
- Nie, Shaojie, et al. Large Language Diffusion Models (LLaDA). arXiv, 14 February 2025, https://arxiv.org/abs/2502.09992.
- Sar, Omar. “Large Language Diffusion Models (LLaDA).” LinkedIn, 2025, https://www.linkedin.com/posts/omarsar_large-language-diffusion-models-llada-activity-7297449734502297600-rQtb/.
Share this post: