Large Language Diffusion Models
Eine Einführung
- Veröffentlicht:
- Autor: [at] Redaktion
- Kategorie: Grundlagen
Inhaltsverzeichnis

Large Language Diffusion Models (LLaDAs) führen ein neuartiges Paradigma ein, bei dem Sprachmodelle eher wie Menschen denken. Die Modelle verwenden einen anderen Ansatz zur Textgenerierung als große Sprachmodelle (LLMs). Um es zu verdeutlichen: LLMs wie ChatGPT und Llama sind autoregressive Modelle (ARMs), die Text sequenziell von links nach rechts vorhersagen. LLaDAs hingegen verwenden einen diffusionsähnlichen Prozess zur Textgenerierung, bei dem Wörter zufällig erscheinen und auch bearbeitet oder gelöscht werden können.
In diesem Artikel werden wir die Ursprünge von LLaDAs, ihre Unterschiede zu LLMs, ihre Funktionsweise und ihre praktischen Anwendungen in realen Industrieumgebungen untersuchen. Zu Beginn werden wir kurz die Grundlagen von Diffusionsmodellen wiederholen, bevor wir uns ihrer Anpassung für die Textgenerierung zuwenden.
Was sind Diffusionsmodelle?
Diffusionsmodelle sind generative Modelle, die ursprünglich durch Anwendungen der Bildsynthese – etwa in Stable Diffusion oder DALL·E 3 – bekannt wurden. Sie arbeiten, indem sie Daten schrittweise verrauschen und anschließend den umgekehrten Prozess erlernen, um aus reinem Rauschen wieder ein strukturiertes Zielobjekt zu rekonstruieren. Dieses Prinzip der sukzessiven Rauschentfernung bildet die konzeptionelle Grundlage für diffusionsbasierte Sprachmodelle, bei denen der gleiche Mechanismus nicht auf Pixel, sondern auf textuelle Repräsentationen angewendet wird.

Diffusionsbasierte Sprachmodelle verfeinern ganze Textphrasen iterativ auf einmal, im Gegensatz zu LLMs, die Wörter sequenziell, eines nach dem anderen, vorhersagen. Diese Verlagerung auf Text bringt einen neuen Prozess mit sich: Ausgehend von einer groben, verrauschten Version einer Passage verfeinert das Modell diese in mehreren Schritten. Da das Modell den gesamten Satz auf einmal betrachtet, kann es schneller und kohärenter als LLMs Ergebnisse generieren. Das Verständnis dieses Unterschieds bildet die Grundlage für die Untersuchung von LLaDAs.
Was sind Large Language Diffusion Models?
Large Language Diffusion Models (LLaDAs) sind eine Klasse generativer Sprachmodelle, die den diffusionbasierten Ansatz auf textuelle Repräsentationen übertragen und damit eine alternative Architektur zu autoregressiven Large Language Models (LLMs) darstellen. Im Gegensatz zu LLMs, die Token sequenziell von links nach rechts erzeugen und dadurch bei Umkehrungsaufgaben oder komplexem, mehrschrittigem Denken Einschränkungen aufweisen, nutzen LLaDAs einen bidirektionalen Rekonstruktionsprozess. Dieser Ansatz adressiert zentrale Limitierungen klassischer LLMs.
LLaDAs zeigen hohe Skalierbarkeit sowie starke Leistungen in Bereichen wie Sprachverständnis, Mathematik, Codegenerierung und chinesischsprachigen Aufgaben. Modelle wie LLaDA 8B erreichen im In-Context Learning ein Leistungsniveau vergleichbar mit LLaMA 3 8B und verfügen über ausgeprägte Fähigkeiten zur Befolgung von Anweisungen über mehrere Dialogrunden hinweg.
Eine der ersten kommerziell relevanten Anwendungen ist der Mercury Coder von Inception Labs, der den diffusionbasierten Ansatz auf Codegenerierung überträgt und im Bereich KI-gestützter Entwicklungswerkzeuge eine führende Position einnimmt.
Unterschiede zwischen Large Language Diffusion Models und Large Language Models
Um ihre jeweiligen Rollen besser zu verstehen, befasst sich dieser Abschnitt mit den Unterschieden zwischen LLaDAs und LLMs und den Vorteilen, die LLaDAs gegenüber autoregressiven LLMs bieten, insbesondere in Anwendungsfällen wie Textgenerierung, Code-Vervollständigung und Dialogsystemen:
| Merkmal | Large Language Diffusion Models | Large Language Models |
|---|---|---|
| Textgenerierung | Large Language Diffusion Models eignen sich besser für lange Texte, bei denen Konsistenz und Kohärenz entscheidend sind. Das liegt daran, dass die Modelle in der Lage sind, Texte zu entwerfen und iterativ zu verfeinern. | Large Language Models sind stark bei Zusammenfassungen und kurzen Texten, haben aber Schwierigkeiten mit langen, logisch aufgebauten Berichten. Da sie Wort für Wort generieren, verlieren sie leicht den Überblick über frühere Passagen, was zu Brüchen und Inkonsistenzen führt. |
| Code-Vervollständigung | LLaDAs können komplette Codeblöcke iterativ verfeinern, indem sie typische Arbeitsweisen von Entwicklern beim Schreiben, Testen und Korrigieren nachahmen. Das senkt den Nachbearbeitungsaufwand und erhöht die Produktivität in Unternehmen. | LLMs generieren gängige Code-Muster gut und eignen sich daher für kurze Snippets. Müssen Fehler jedoch nachträglich behoben werden, scheitert ein schrittweiser Korrekturansatz meist. |
| Dialogsysteme | Large Language Diffusion Models sind in der Lage, themenbezogene und zuverlässige Dialoge zu führen, wodurch sie sich für kundenorientierte und Compliance-sensitive Branchen eignen. Durch die iterative Verfeinerung kann das System die Antworten an den Kontext anpassen. | LLMs eignen sich hervorragend für kurze, risikoarme Gespräche, können jedoch im Kundensupport oder in professionellen Kontexten „halluzinieren”. Halluzinationen können zu Missverständnissen und erfundenen Antworten führen. |
LLaDAs: Architektur, Modelltraining und technische Einschränkungen
Large Language Diffusion Models (LLaDAs) kombinieren die Fähigkeiten von Diffusionsmodellen mit denen von LLMs. Diese Modelle generieren Text, indem sie die Sprachverteilung durch einen Diffusionsprozess lernen. Das Modell verwendet einen Forward Data Masking Process und einen Reverse Process für die Modellverteilung und Textgenerierung. Betrachten wir dies anhand von Beispielen im Detail. Anschließend werden wir kurz den Trainingsprozess von LLaDAs und die damit verbundenen technischen Einschränkungen betrachten.
Forward Process
Das Modell beginnt mit einer Folge von Tokens, wie z. B. Wörtern oder Zeichen, und maskiert diese nach und nach unabhängig voneinander, bis die Folge vollständig maskiert ist. Die Maskierungswahrscheinlichkeit steigt linear mit der Zeit. Bei t = 0 werden beispielsweise keine Tokens maskiert, während bei t = 1 alle Tokens maskiert sind. So funktioniert das:
Bei t=0,5 werden einige Token zufällig maskiert:
Maskierter Satz:
Bei t=1,0 sind alle Token maskiert:
Reverse Process
Dieser Prozess stellt die ursprüngliche Sequenz aus der vollständig maskierten Sequenz wieder her. Er sagt Tokens iterativ voraus und maskiert sie, wobei er sich von t = 1 zurück zu t = 0 bewegt. Ein Maskenvorhersager, in der Regel ein Transformer-Modell, sagt die maskierten Token auf der Grundlage teilweise maskierter Sequenzen voraus.
Bei gleichem Satz, bei t = 1, wenn der Satz vollständig maskiert ist:
Bei t=0,5, wenn der Satz teilweise maskiert ist:
Bei t=0, wenn der Satz überhaupt nicht maskiert ist:
Auf diese Weise rekonstruiert das Modell erfolgreich den ursprünglichen Satz.
Trainingsphasen von LLaDAs
Vortraining
Wie in Abbildung 2 dargestellt, befindet sich oben eine Beispielsequenz aus dem Trainingssatz. Der Maskenanteil t mit einem Wert zwischen 0 und 1 wird zufällig ausgewählt. Für jedes Token wird zufällig entschieden, ob es maskiert werden soll oder nicht. Das Ergebnis ist eine teilweise maskierte Token-Sequenz. Diese teilweise maskierte Sequenz wird in den Maskierungsprädiktor eingespeist. Der Maskierungsprädiktor ist ein Transformer-Modell, das darauf trainiert ist, die maskierten Token wiederherzustellen. Es lernt, den Kontext unmaskierter Token mit den richtigen maskierten Token zu verknüpfen.
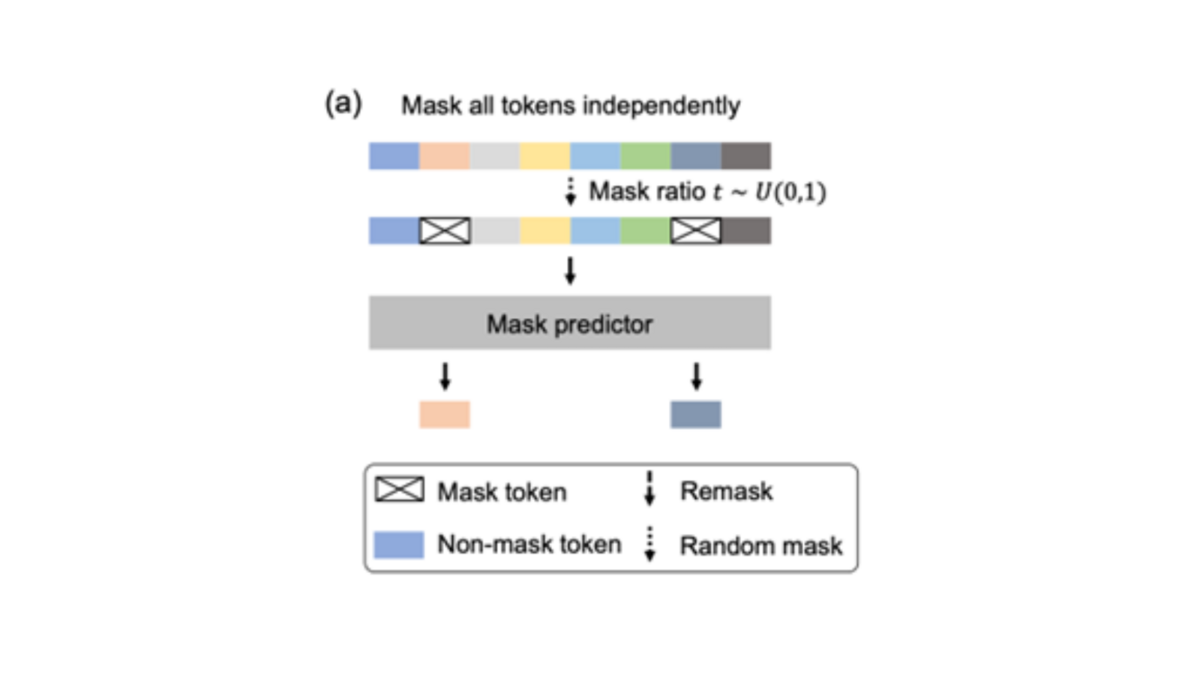
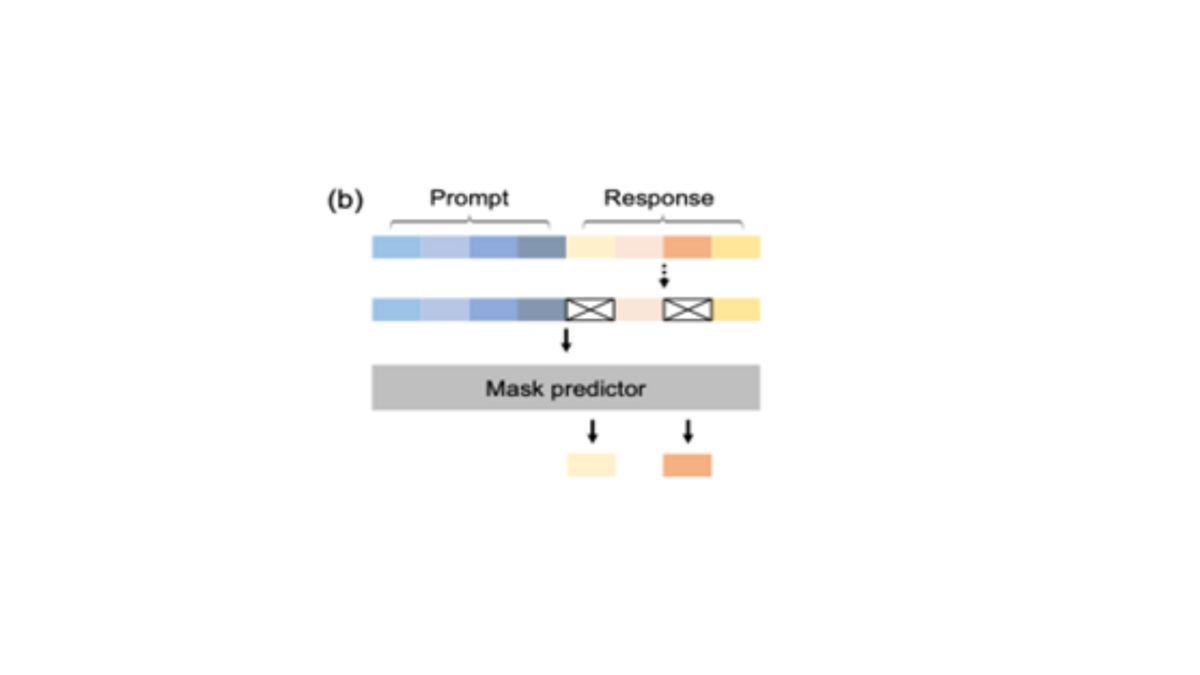
Überwachtes Fine-Tuning
Diese Phase verbessert die Fähigkeit von Large Language Diffusion Models, Anweisungen zu befolgen. Wie in Abbildung 3 dargestellt, befinden sich oben eine Eingabeaufforderung und eine Antwort. Das Ziel besteht darin, das Modell so zu trainieren, dass es eine Antwort auf die gegebene Eingabe generiert. Ähnlich wie beim Vortraining werden einige der Token in der Stichprobe zufällig maskiert. Diesmal werden jedoch nur die Token aus der Antwort maskiert, während diejenigen in der Eingabe unmaskiert bleiben. Anschließend werden die Eingabe und die teilweise maskierte Antwort in den Maskierungsprädiktor eingespeist, um die maskierten Token aus der Antwort wiederherzustellen.
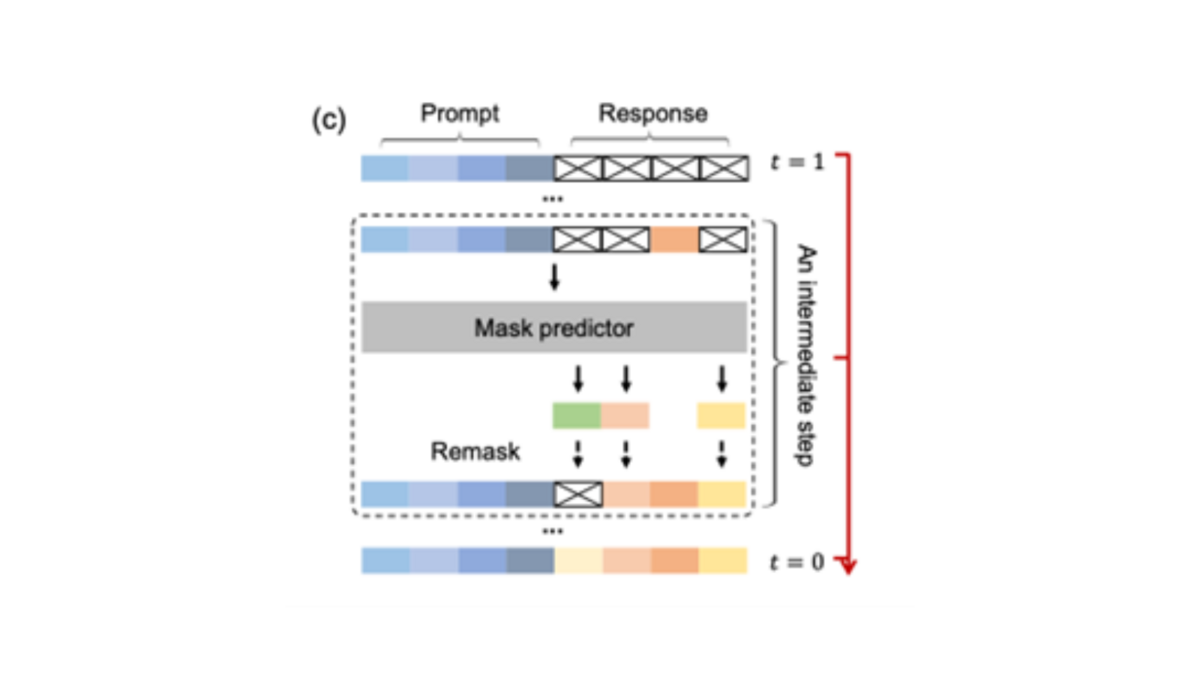
Sampling
Wie in Abbildung 4 dargestellt, beginnt der Diffusionsprozess in LLaDAs mit einer vollständig maskierten Sequenz (t = 1) und maskiert die Tokens nach und nach auf, um die ursprüngliche Sequenz (t = 0) wiederherzustellen. Das Modell sagt alle maskierten Tokens gleichzeitig in jedem Schritt des Diffusionsprozesses voraus. Die Fähigkeit des Modells, verschiedene Strategien einzusetzen, um zu entscheiden, welche Tokens in jedem Schritt erneut maskiert werden sollen, ermöglicht eine flexiblere und kontextbewusstere Textgenerierung.
Technische Einschränkungen und Besonderheiten
- Large language Diffusion Models schneiden bei Umkehrungsaufgaben gut ab und übertrifft seine Konkurrenten wie GPT-4. Bei einigen allgemeinen Aufgaben bleibt seine Leistung jedoch hinter LLM wie LLaMA3 8B und Qwen2.5 7B zurück.
- LLaDAs benötigt 2-10-mal mehr Rechenleistung als LLM, was eine sofortige breite Einführung verhindert.
- Das Training von LLaDAs erfordert eine sorgfältige Abstimmung von Noise Schedules, Verlustgewichtung und Regularisierungsstrategien, was die Komplexität erhöht und Workarounds erforderlich macht.
Langfristige Effizienzaussichten
Angesichts der aktuellen technischen Einschränkungen von LLaDAs, wie z. B. hoher Rechenaufwand und komplexes Training, sind sie derzeit nicht für groß angelegte Modelle in Unternehmen geeignet. Vielleicht ist in Zukunft ein hybrider Ansatz, der die Stärken von autoregressiven und Diffusionsmodellen kombiniert, auf Unternehmensebene besser geeignet.
Anwendungsbereiche
Im Unternehmensumfeld eröffnen Large Language Diffusion Models ein breites Spektrum an Anwendungsmöglichkeiten. In der Softwareentwicklung können sie Codegenerierung und Debugging deutlich beschleunigen, wie Systeme à la Mercury Coder bereits zeigen. Durch ihre Fähigkeit, Token parallel und iterativ zu verarbeiten, eignen sie sich zudem für den Einsatz auf mobilen Geräten oder Edge-Systemen, wo Rechenressourcen begrenzt sind. In wissensintensiven Bereichen unterstützen LLaDAs bei der Erstellung, Verfeinerung und Überprüfung von Berichten, Richtlinien oder Compliance-Dokumenten. Auch in der Kreativwirtschaft kommen sie zum Einsatz, etwa für Marketingtexte, Werbeskripte oder lange Erzählformate, die sowohl Kreativität als auch faktische Genauigkeit erfordern.
Die Potenziale der Modelle liegen insbesondere in ihrer hohen Zuverlässigkeit und Kohärenz: Die iterative Verfeinerung reduziert Halluzinationen, glättet logische Brüche und verbessert die strukturelle Konsistenz über längere Texte und Dialoge hinweg. Gleichzeitig sinkt die Inferenzzeit, da Token parallel statt sequenziell erzeugt werden. Da LLaDAs Text nicht Wort für Wort, sondern ganzheitlich betrachten, können sie zudem komplexe Beziehungen besser erfassen und plausibler schlussfolgern.
Gleichzeitig ist der Einsatz dieser Modelle mit Herausforderungen verbunden. Eine ausgeprägte Talentlücke erschwert Rekrutierung und Weiterbildung. Iterative Verfeinerungsschritte können zu erhöhter Latenz führen, was vorwiegend in zeitkritischen Unternehmensanwendungen relevant ist. Die technische Integration ist anspruchsvoll, da bestehende LLM-Pipelines meist für autoregressive Architekturen ausgelegt sind. Hinzu kommt, dass das Ökosystem rund um LLaDAs – von Tools bis zu vortrainierten Modellen – noch vergleichsweise unausgereift ist.
Der Wechsel von autoregressiven zu diffusionsbasierten Modellen hat weitreichende Implikationen für Unternehmensinfrastrukturen. Die Einführung von LLaDAs verursacht zunächst hohe Kosten, da mehrstufige Inferenzverfahren einen erhöhten GPU-/TPU-Bedarf mit sich bringen. Auch etablierte Qualitätssicherungsprozesse müssen überarbeitet werden, weil sich Modelle zunehmend selbst korrigieren, wodurch sich Rollen und Zuständigkeiten verschieben können. Bestehende Pipelines, die auf sequentielle Dekodierung optimiert sind, benötigen eine grundlegende Anpassung an iterative Verfeinerungsworkflows. Darüber hinaus führt die veränderte Arbeitsweise zu kulturellen Veränderungen: Mitarbeitende müssen den Übergang von mehrfachen Entwurfsstufen hin zu nahezu finalen KI-Ergebnissen nachvollziehen und ihre Rolle stärker in Richtung strategischer Kontrolle und Bewertung verlagern.
Insgesamt bieten LLaDAs erhebliche Chancen für Effizienz und Qualität in betrieblichen Prozessen – verlangen Unternehmen jedoch zugleich nach technischen, organisatorischen und kulturellen Anpassungen, um ihr Potenzial vollständig auszuschöpfen.
Fazit
Large Language Diffusion Models (LLaDAs) stellen eine grundlegende Veränderung in der Architektur der Sprachgenerierung dar und bieten überzeugende Vorteile bei der Codegenerierung, der Erstellung langer Dokumente und der Konsistenz von Dialogen. Aufgrund der hohen Rechenkosten und der Komplexität der Integration sind sie jedoch für den Einsatz in Unternehmen ungeeignet. Unternehmen, die an der Einführung von LLaDAs interessiert sind, sollten Pilotprogramme starten, um Fachwissen aufzubauen. Letztendlich werden LLaDAs eine größere Rolle in der Unternehmens-KI einnehmen, wenn sich das Preis-Leistungs-Verhältnis verbessert.
Literaturhinweis
- Data Science Collective. “LLaDA Explained: How Diffusion Could Revolutionize Language Models.” Medium, 2025, https://medium.com/data-science-collective/llada-explained-how-diffusion-could-revolutionize-language-models-950bcce4ec09.
- Hugging Face. “Diffusion Language Models: The New Paradigm.” Hugging Face Blog, 10. Juni 2025, https://huggingface.co/blog/ProCreations/diffusion-language-model.
- Kellogg, Tim. “LLaDA: LLMs That Don’t Gaslight You.” Tim Kellogg Blog, 17. Februar 2025, https://timkellogg.me/blog/2025/02/17/diffusion.
- Nie, Shaojie, et al. Large Language Diffusion Models (LLaDA). arXiv, 14. Februar. 2025, https://arxiv.org/abs/2502.09992.
- Sar, Omar. “Large Language Diffusion Models (LLaDA).” LinkedIn, 2025, https://www.linkedin.com/posts/omarsar_large-language-diffusion-models-llada-activity-7297449734502297600-rQtb/.
Diesen Beitrag teilen: