AI Solutions Leveraging Foundation Models
- Published:
- Author: Dr. Bert Besser
- Category: Deep Dive
Table of Contents

Foundation Models (FMs) are large pre-trained AI models that can adapt to various tasks, simplifying development of AI solutions. The pre-training is self-supervised on very large-scale datasets (such as text, images, audio, time series, etc., or combinations of those), giving the model broad knowledge and deep understanding of its training subject. The adaptation of such a “knowledgeable” model to a specific task is usually much simpler and more efficient than training from scratch, allowing for rapid development and deployment of AI solutions. While FMs have already shown overwhelming value in generative AI, their widespread application in other domains is accelerating as well.
This article focusses on opportunities and challenges that implementing AI with FMs will raise in the years ahead (beyond today’s focus on generative AI), among them for example cost considerations, potential risks, or the workflow to create AI solutions.
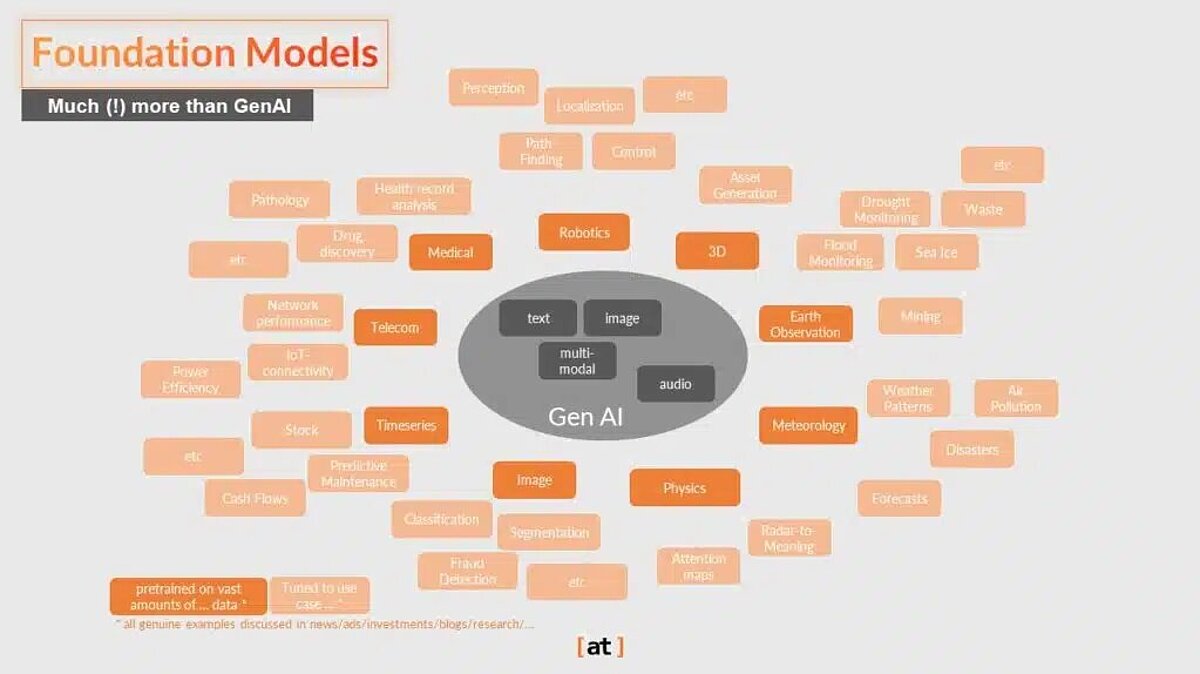
Distinction from Generative AI
Foundation Models (FMs) are often mistakenly conflated with generative AI (Gen-AI). Gen-AI models are trained to create new content (text generation, image synthesis, video creation, etc.). Note that some support combinations across data types, like e.g. text and images, in input and/or output—which is referred to as multi-modality. However, while Gen-AI specifically targets creating new data, FMs can be applied to a much broader spectrum of tasks, such as classification, time series forecasting, robot localization, and many more, including Gen-AI.
Some people even consider neural nets pre-trained on ImageNet as early examples of FMs for image classification, that can be adapted to specific image domains using transfer learning. Those networks are not FMs in the strict “modern” sense, though: Their training data was labelled, while FMs are usually trained in a self-supervised manner on vast amounts of data that cannot easily be labelled by humans given time and cost constraints.
FMs have the potential to be applied across numerous domains beyond today’s core focus areas of Gen AI. The next section presents concrete use cases that FMs solve today and in the future.
Use cases of Foundation Models
FMs have the potential to transform numerous industries and domains, from traditional fields like medicine and finance to areas like 3D computer vision and robotics. As FMs continue to evolve, we can expect to see applications in an increasingly diverse range of sectors.
In the following domains (and more domains), there is active work to create dedicated FMs. Maturity varies, from being in research (public or in the industry) to being embedded into a product offering, often as an integral part:
- Enterprise applications, like legal, HR, etc.: e.g. Cohere Rerank
- Can be applied off-the-shelf, or e.g. fine-tuned to better grasp specific terminology and produce more relevant and precise results
- Audio transcription and translation: e.g. OpenAI Whisper
- Can be applied off-the-shelf, or e.g. fine-tuned for additional languages
- Time-series forecasting for financial steering and planning (costs, sales, prices, etc.), and for predictive maintenance: e.g. Chronos or TinyTimeMixer
- Can be applied off-the-shelf, or e.g. fine-tuned for trading applications
- Arbitrary image segmentation: e.g. Segment Anything or SegGPT
- Can be applied off-the-shelf, or e.g. fine-tuned for specific data such as satellite imagery or texts
- Video generation: e.g. OpenSora or CogVideo
- Multi-modal tasks such as visual question answering: e.g. LLaVA
- Medical applications, such as diagnostic imaging: e.g. RETFound
- 3D asset generation: e.g. NVIDIA Edify 3D
- 3D computer vision and robotics: e.g. NVIDIA GR00T or Archetype Newton
- Earth observation, like flood-zone or drought mapping: e.g. ESA FM4CS or Clay
- Weather forecasting: e.g. Microsoft Aurora
- Geo-physics analysis, like earthquake localization: e.g. SeisCLIP
- Culture-specific, including language processing: e.g. SEA-LION
These domains represent a few examples of the many applications for FMs. It can be expected that many more will be developed in the future, transforming further domains and industries.
Developers and Investments
FMs are developed by various entities, each with their own focus and motivations. The following broad categories outline the different types of FM developers.
Proprietary
Companies create proprietary FMs as a product, or as core part of their market offer. Their focus is on monetizing the model through commercial applications. For example, in the realm of Gen-AI, OpenAI invests in developing better FMs for ChatGPT and sells services access to those. Beyond Gen-AI, for driving robot arms in a broad range of warehouse settings, Covariant develops the RFM-1 model.
Often, monetary resources were acquired from Series C funding, aiming to grow a company and capitalize on the expected success.
Research
Research institutions and universities develop FMs for advancing the field, publishing research papers, and bringing society forward. Examples are found in e.g. space and earth observation, climate, or medicine.
The monetary sources come from e.g. research associations: As an example, Helmholtz recently provided funds of 23 million euros.
Cloud Providers
Cloud providers like AWS offer pre-trained models as a unique selling point, like AWS Titan. The goal is to keep customers invested in their cloud offers (instead of buying FM services elsewhere), and of course to attract new customers.
In many cases, such models are part of a broader offer allowing enterprises to manage data and fine-tune models to their individual needs, also providing IAM, collaboration tools, data catalogues or model registries (“FM tuning suites”).
Typically, a cloud provider company invests their own resources in competition with other providers.
Open-Source
Freely available FMs, e.g. for NLP tasks like text classification, speech-to-speech translation, image segmentation, etc. are contributed to the open source community though research, both public and from corporations, or by groups or individuals. A popular catalog of such models, with a focus on NLP, imagery, and audio, is Hugging Face. Their transformers library specializes on downloading and fine-tuning pre-trained models.
Open-source contributions are either non-profit or e.g. done for advertising a firm’s services. The platform Hugging Face monetizes, among other sources, from integrating their popular product into cloud offers from e.g. AWS or Azure.
Other
Investments are also raised for entities that do not fit clearly in one of the above-mentioned categories. E.g. sakana.ai raised 30 million dollars for an entirely novel way in creating FMs, namely combining modules from existing FMs without further training. An iterative evolutionary approach selects neural network modules and mixes weights to create models that perform well in capabilities that the base models were not trained for.
Open vs closed
An area of uncertainty and discord is whether FMs should be “open”, a frequently used term to indicate that a model is openly accessible for download. Once downloaded, it can then be applied/analyzed/tailored/… freely for your particular case. The term “democratization” (see below) is closely related.
(Note that, in general, “open” refers to the access to model weights, but not to training data and training code. A truly open-source model will document and provide all three, as is often done in research.)
On the one hand, supporters of democratization aim at bounding the market power big tech companies can gain: Big tech’s financial resources allow them to leverage expensive compute resources to train powerful models and to offer leading products. Based on customers’ dependence on their services, they can thus sustain or grow their market share. Democratization pushes free access not only to the final models, but also to training data and training code, allowing small firms and individuals to reduce their dependence.
On the other hand, open powerful models (such as Llama3.1-70B or Mixtral) can be applied in malicious ways, such as exploiting one-day vulnerabilities. The argument is that making more and more powerful models openly available puts new weapons freely into the hands of actors whose goal could even be to threat entire nations, e.g. in the realm of cybersecurity. Keeping leading developments concealed in research labs (from the industry or defense) might help to secure a nation’s advantage.
This topic certainly is one of the ones that will shape if and how FMs will proliferate in industry, defense, consumer sector, etc. in the future.
Training and Adaptation Processes
FMs can be adapted to individual tasks through various methods. Some tasks allow direct application of the FM, while others require further training on domain-specific data. The choice of the adaptation approach depends on the desired balance between the needed quality, invested time and cost, and ease of adaption.
Zero-shot Inference
Zero-shot inference is the term for applying an FM as is, i.e. as it comes off-the-shelf, without any modifications. (”Zero-shot” refers to the fact that the model gets zero opportunity to learn about domain-specific data. In contrast, the next section outlines an approach where a model gets a “few shots” at learning.)
As one example for zero-shot inference, the CLIP model was trained on internet-scale volumes of images and their corresponding text captions. Using these descriptions, the model gained a broad understanding of what is displayed on images. As a result, CLIP allows zero-shot image classification (types of food, for example). Another example for zero-shot inference: ChatGPT can be prompted to generate all sorts of texts (e.g. writing catchy ads for the marketing campaign of a new product).
Zero-shot inference is very easy to use (especially for novel tasks for which not much reference data is available) and it incurs no additional cost. However, quality may vary–as an example, CLIP is unlikely to classify images well that are very domain-specific, such as defective products in a production line. In LLM zero-shot prompting for specific questions, such as e.g. the operating principles of highly specialized machinery, hallucination-like output could be a concern, since the general-purpose LLM knows only little about the specific subject but may not detect this fact and regardless produce a deficient response.
In our article, we examine how the CLIP model performs after fine-tuning to specific datasets compared to traditional models such as ResNet50.
Fine-Tuning the CLIP Foundation Model for Image Classification
Few-shot Learning
LLMs can easily be instructed to behave in a certain way by giving it guiding examples. To pick up the above scenario, writing catchy ads for a marketing campaign may require informal youth speech, using very few words, or using certain terminology: Giving a few according examples (i.e. a set of product descriptions together with their respective ad) as part of the prompt will often result in higher-quality results than a formal description of the task.
The upside of few-shot learning is that it does not require change of the FM, and it can handle quite complex tasks with very limited data (only a handful of examples, as the name “few-shot” suggests). However, if the specific task covers a very broad domain (e.g. answering car insurance customer requests), few-shot learning may still be too limited to produce quality results over the entire needed range of potential inquiries.
One approach to overcome the limitation of few-shot learning in LLMs is Retrieval Augmented Generation (RAG), where the prompt context is populated with examples relevant for the prompt at hand. The examples come from a connected document store and are chosen by similarity with the original prompt (the document store is usually implemented as a so-called vector database and similarity search usually applies a specially trained so-called embedding model).
Fine-tuning
The above given x-shot techniques might not be applicable or sufficient to adapt a pre-trained FM to a specific task. FMs are in many instances intentionally designed in a way to allow so-called fine-tuning. Fine-tuning is the procedure of continuing the training of the model, but now with very specific labelled data from a given domain (instead of the general domain-unspecific data used in self-supervised pre-training). Such fine-tuning datasets often require dozens to hundreds or thousands of high-quality samples, which must be curated by domain experts.
Here are a few examples of fine-tuning:
- Similar to ChatGPT’s instruction tuning, Llama3.1-Instruct is the fine-tuned version of Llama3.1
- For some intuition what an instruction data looks like, here is a dataset with specific instructions to extract information from some given text. (The tuning of Llama3.1 or ChatGPT involves additional types of datasets as well.)
- A specific example from that dataset:
- 1. From the text “Gildan Cotton Crew Neck T-Shirts are anything but basic. Crafted with soft, breathable cotton and moisture wicking technology to keep you cool and comfortable no matter what’s on the agenda. Perfect for layering or lounging – you can thank us later.
Price:$18.99. C4 Energy Drink now available in a delicious and sugar-free carbonated form. This drink features 200mg of caffeine, CarnoSyn beta-alanine and citrulline malate in every serving. Carbonated C4 Original On the Go packs the legendary energy, endurance and pumps that you know and love from C4. Available in a 18 pack with two flavors, Frozen bombsicle and Strawberry Watermelon.Price:$33.59” - 2. the task is to “Retrieve product information such as product name, target audience, key feature, material, and price from e-commerce websites. We need this data organized for categorization and comparison purposes.”,
- 3. which should be answered with the table (in Markdown format):
| Product Name | Target Audience | Key Feature | Material | Price |
| — | — | — | — | — |
| Gildan Cotton Crew Neck T-Shirts | N/A | Moisture wicking
technology | Cotton | $18.99 |
| C4 Energy Drink | N/A | 200mg of caffeine, beta-alanine |
Carbonated drinks | $33.59 |
- 1. From the text “Gildan Cotton Crew Neck T-Shirts are anything but basic. Crafted with soft, breathable cotton and moisture wicking technology to keep you cool and comfortable no matter what’s on the agenda. Perfect for layering or lounging – you can thank us later.
- CLIP can be fine-tuned to increase its classification performance for photos of wildlife animals or earth observation imagery (read this blog article to know more about the procedure and data)
- Figure 2 shows some example images of wildlife, where the dataset also contains the types of animals in each picture.
- The CLAY model for earth observation can be fine-tuned for creating flood maps (specifically, the dataset contains binary pixel segmentation masks)
- In figure 3 the training data consists of satellite imagery together with pixel maps indicating flood zones
Fine-tuning is the most powerful approach, with the potential to achieve high performance on domain adaptions. However, it requires high-quality labeled data and significant computational resources, and hence is also the most time-consuming and costly approach to adapt an FM.
Note however, that still much less data is needed than training a model from scratch, because the FM already has incorporated broad general knowledge about the domain in question (e.g. language or image features).
Note also that computational cost for fine-tuning is further reduced by not adjusting weights in the entire model, but only in very select parts. Specifically, LoRA (and variants like QLoRA) were conceived to reduce the trainable parameters in fine-tuning to a fraction of the original model size, thereby reducing compute resource requirements and runtime. Implementations of such procedures are available for example in Hugging Face’s peft library (PEFT stands for Parameter-Efficient Fine-Tuning).
In applications of fine-tuning LLMs, RAG is an alternative to be considered (just as for few-shot learning, see the previous section). Especially, a RAG setup will adapt quicker to frequently changing data, since data can be added to the connected document store, and there is no need to curating data and re-training the model.
Operational costs
Operating FMs (in their base form or fine-tuned) incurs cost like with any other AI model. The term Foundation Model and the (perceived) close relationship with Large Language Models might mislead to the conclusion that operating FMs is generally very expensive. This is not true. The usual patterns to control cost apply, and FMs frequently are much smaller than LLMs, as outlined below.
Usual cost control patterns
Un-tuned FMs can often be consumed pay-as-you-go through APIs provided by cloud services. This is in particular true for models from popular catalogues such as Hugging Face, which are integrated in the cloud offers like AWS Sagemaker or Azure: You can spin up a model available on Hugging Face within your cloud environment (and you do not have to care about infrastructure). Pay-as-you-go lets you cut down cost to what’s really needed and avoids serving a model when there is no demand.
For batch jobs, spinning up a model temporarily and stopping it afterwards might be an economically feasible choice even for very large models requiring pricy infrastructure.
Sharing infrastructure cost for FMs that serve multiple use cases in the same corporation has the potential to reduce spendings to an economical level.
Model size
LLMs are frequently available in various sizes, ranging from requiring high-end GPUs with lots of memory (maybe several of them) down to being runnable on commodity GPUs. (E.g. the instruction-tuned Llama3.1 is available with 405 billion parameters, 70 billion parameters, and 8 billion parameters.) A small size model might already serve your use case just fine. Even smaller ones are available, that will run just fine on your (GPU-equipped) laptop, such as Llama3.2 with 1 billion parameters or the instruction-tuned Phi3.5 mini with 3.8 billion parameters.
Quantizing a model, as is often done for LLMs, degrades quality only little, but helps reduce compute cost because less memory and smaller GPUs are sufficient for inference.
FMs for other domains are much (!) smaller than today’s LLMs, which have tens or even hundreds of billions of parameters. E.g. the Segment Anything Model for image segmentation has only 640 million parameters even in its largest form, and has variants as small as 10 million parameters (for example, MobileSAM). The Chronos model for time series forecasting was recently released in five sizes ranging from 700 million down to 8 million parameters. (Note that typically even small FMs are still larger than specialized models trained on domain-specific data.)
Technical advancements
By developing FMs that can switch between tasks on the fly while in operation, organizations might enjoy greater flexibility without incurring additional expenses for hosting multiple instances. Apple announced such functionality for running models on phones: It is an FM served in one instance, and adaptions from different fine-tunings can be replaced during operation.
Cloud Provider offerings
As FMs emerge, cloud providers are extending their offers that cater to this trend. Here’s a peek into what major cloud providers have in store for enterprises. Most offer suites for enterprises to curate data, tune FMs, serve FMs, as well as authentication and authorization mechanisms so that governed collaboration can occur across company departments (“FM suites”).
We give an (incomplete) overview of various providers and some of their unique selling points, to showcase the variety of offers available in the market.
AWS/Azure/GCP
We start with the most well-known providers. It is a strong simplification to discuss these three big as one, of course. Still, they have many broad strokes in common, that distinguish them from the providers mentioned below. In many cases companies are already bound to one of them, hence considering taking advantage of their new offerings without considering a switch to another provider.
What the big three have in common is that each of them already offered a broad spectrum of AI&ML services in the past (specialized computation resources like e.g. AWS Inferentia, suites with features like e.g. Auto ML or hyper parameter optimization, or ready-made products for tasks like speech and text analysis or fraud detection). To complement this service landscape, they are racing for allowing to utilize FMs for Gen-AI, i.e. they offer tool stacks to prepare data and fine-tune models, and, of course, to serve them for inference—all integrated in their UI, tooling, SDKs, identity management, and of course into their other existing services. This targets current customers, who should be able to on-board onto the new offers fast.
NVIDIA
Their DGX platform targets companies transforming their business to leverage AI—from compute resources to expert support tailored to your business field. The service is backed by research expertise, being leader in dedicated GPU hardware, and training offers in how and what type of AI alters diverse sectors and domains.
DGX is also leveraged for training NVIDIA’s GR00T FM for humanoid robots.
Cloudflare
Originally one of the leading CDN providers in the world, Cloudflare offered already in the past running serverless code on the edge. The current main offer (in the context of this article) is serving LLMs in Cloudflare’s globally distributed data centers, close to customers. No need to spin up and continuously pay GPU instances. For RAG applications, managed vector databases are available as well.
Hugging Face
Born from the goal to democratize access to AI models and data, today Hugging Face is the largest collection of openly available pre-trained FMs and datasets (in parts fully open source, e.g. with model weights, training data, and training code).
Above that they also offer paid services, especially an enterprise hub built to allow enterprise teams or departments to collaborate beginning from data creation to model selection and tuning to serving inference requests for your business applications. For serving models publicly, there’s the so-called spaces, where you pay by the hour depending on the power of the hardware needed to showcase your model.
IBM
Extending their Watson AI platform, which offers systems for information retrieval, automated reasoning, and more, watsonx was created to add generative abilities on top of the given ones. It allows to fine-tune and distribute FMs for Gen-AI and maintain models over their entire lifecycle from creation to production operations.
Also, their model library provides models targeted specifically at enterprise needs, like trained on rigorously governed data with high transparency, or specialized for certain business domains but smaller and more (cost) efficiently to operate (like the TinyTimeMixer).
Oracle
Oracle extends its offers for example to select, tune, and host FMs (LLMs in particular), thereby letting their customers seamlessly leverage the new technology from within the familiar and established enterprise software solutions.
Wrap-up
Each cloud provider’s offers differ in terms of focus areas, pricing models, and technical capabilities. Hence businesses will have to research what offer fits their individual needs best.
Implications and Consequences of using FMs
Low entry barriers
FMs carry the potential to change how AI products will be created. A lower entry barrier helps to quickly evaluate potential business profit using prototypes (with readily available APIs, or model hubs with integrated serving).
Simplified Model Adaption
For adapting ready-made models to the business domain, ever-simpler programming libraries for fine-tuning models emerge (e.g. Hugging Face transformers and peft), and cloud providers offering the required compute resources on-demand allow to speed up the model-creation process considerably. Less volumes of high-quality data are required because FMs already contain broad “world knowledge” (e.g. language understanding, interpreting visual features, “sensing” the surrounding physical world, etc.). Those developments should also allow to iterate AI solutions more quickly.
Increased Productivity
With simplified model creation, businesses can also focus more on getting new tools and services to production, thereby increasing the probability that AI investments yield return.
Future Outlook
As we conclude our 10.000ft fly-over of the current field of FMs, it’s clear that this technology is set to transform industries and revolutionize the way we approach AI solution development. However, there are open questions on the horizon that will shape the future of FM applications.
Among them: Will dominant players emerge in the FM developer landscape, limiting choice, or will new entrants diversify offers and potential applications? As FMs become increasingly influential, security concerns arise: they are a double-edged sword fueling innovative applications and malicious misuse. Will models be closed and only accessible through APIs—preventing misuse by means of guardrails—or will FMs be openly accessible? Transparency and licensing are also critical issues that will require careful consideration if a model can be applied: What data was used to train a model (“ethical data”), and are users safe from legal concerns (copyright concerns)?
How to start, i.e. what aspect to focus on first when considering FM applications in your business? Ideally, your case allows using an open FM without fine-tuning, and it is small enough for either cheap access to a managed service or self-hosting. If fine-tuning is advised, a model with available fine-tuning code is a good entry point. Fine-tuning is also frequently done using specialized libraries such as transformers, with bare PyTorch, or using a cloud provider “FM suite” such as Azure OpenAI Service. In proprietary cases, model access often is API-only, which mostly offers a pay-as-you-go model.
Thank you to my dear colleagues Dr. Stefan Lautenbacher and Constantin Sanders for valuable input!
Share this post: