Explainable AI – Methoden zur Erklärbarbeit von KI-Modellen
- Veröffentlicht:
- Autor: Dr. Luca Bruder, Dr. Johannes Nagele
- Kategorie: Deep Dive
Inhaltsverzeichnis

Explainable AI (XAI) ist momentan eines der meistdiskutierten Themen im Bereich der KI. Entwicklungen wie der AI-Act der Europäischen Union, der Erklärbarkeit zu einer verpflichtenden Eigenschaft von KI-Modellen in kritischen Bereichen macht, haben XAI in den Fokus vieler Unternehmen gerückt, die KI-Modelle entwickeln oder anwenden. Da dies mittlerweile auf einen großen Teil der Wirtschaft zutrifft, ist die Nachfrage nach Methoden, die die Entscheidungen von Modellen nachvollziehbar beschreiben können, immens gestiegen.
Aber warum ist Erklärbarkeit so eine wichtige Eigenschaft? Welche Methoden aus dem Bereich XAI können uns dabei helfen, die Entscheidungen eines komplexen datengetriebenen KI-Algorithmus zu verstehen? Diesen Fragen wollen wir in diesem Artikel mit einem etwas technischeren Schwerpunkt auf den Grund gehen. Der Grundmechanismus vieler KI-Modelle ist, dass aus einer großen Datenmenge Muster gelernt und diese dann als Entscheidungsgrundlage für neue Beispiele genutzt werden. Welche Muster das KI-Modell gelernt hat, ist leider in vielen Fällen nicht offensichtlich bzw. nur schwer nachvollziehbar. Das Modell formt für den Ersteller und den Nutzer eine Black-Box, bei der wir die Logik, die von einer Eingabe (Input) zu einer bestimmten Ausgabe (Output) führt, nicht kennen. In diesem Artikel wollen wir uns auf KI-Modelle für tabellarische Daten konzentrieren, weil diese zentral für eine große Menge an Business-Usecases sind.
Von Natur aus gibt es verschiedene Modelle, die besser erklärbar sind als andere: Lineare Regressionen und Entscheidungsbäume, zum Beispiel, sind allein durch ihr Design relativ gut erklärbar. Wer also von Grund auf ein Modell entwickelt, bei dem die Erklärbarkeit eine zentrale Rolle spielt, sollte sich für diese oder ähnliche Modelle entscheiden. Dies ist aber in vielen Use Cases nicht ausreichend. Bei komplexeren Anwendungsfällen, bei denen z. B. Deep Learning oder Ensembles zum Einsatz kommen, wird versucht, mit der sogenannten Post-hoc (nachträglich, danach) Analyse von Modellen Erklärbarkeit herzustellen.
Post-Hoc Ansätze für XAI
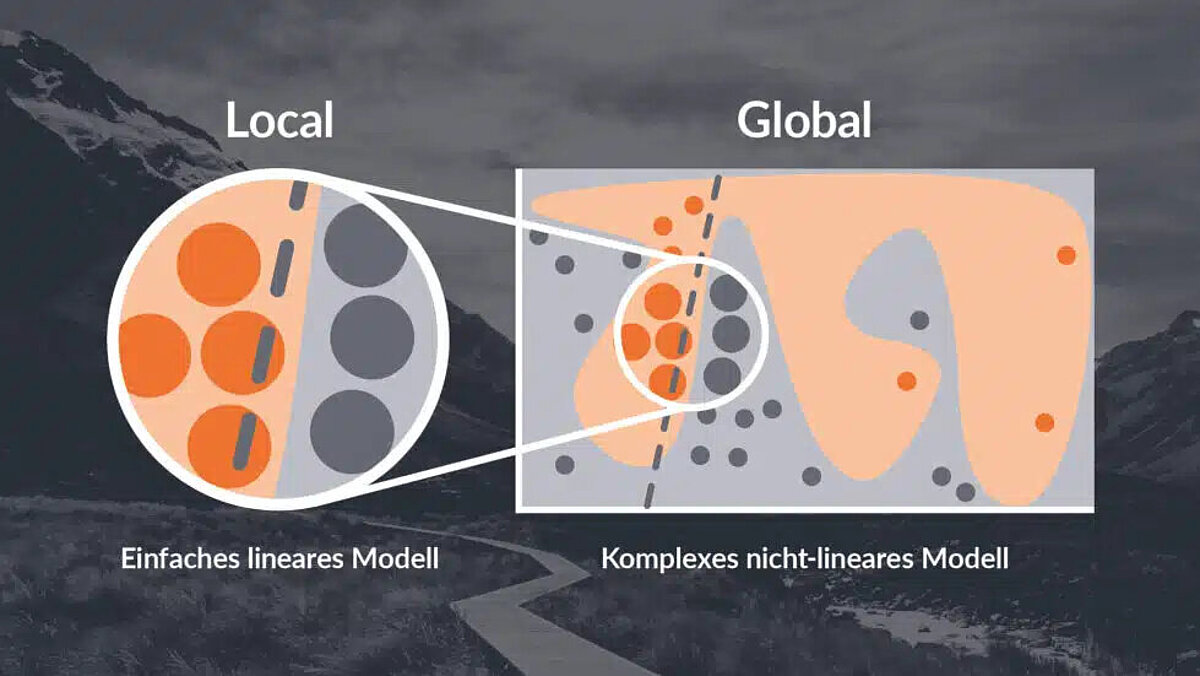
Mittlerweile gibt es einen gut gefüllten Werkzeugkasten von Methoden, die eine Analyse und Auswertung der Entscheidungslogik eines Black-Box-Modells – also ein Modell, bei dem die Entscheidungslogik nicht nachvollziehbar ist – möglich machen. Prinzipiell verfolgen aber viele Methoden ähnliche Ansätze. Daher beschreiben wir hier eine Reihe von Ansätzen, mit denen sich eine Black-Box je nach Ansatz und Komplexität dursichtig oder zumindest dunkel getönt statt tiefschwarz gestalten lässt. In der Regel unterscheidet man bei Post-Hoc-Methoden zwischen globalen und lokalen Ansätzen.
- Globale Methoden versuchen, ein ganzes Modell abzubilden und zu interpretieren. Ziel ist, die generelle Entscheidungslogik des Modells zu verstehen. Ein Beispiel ist, ein erklärbares Modell mit allen verfügbaren Inputs und Outputs eines Black-Box-Modells zu trainieren und das neue erklärbare Modell auf seine Entscheidungslogik zu untersuchen.
- Lokale Methoden untersuchen die Entscheidung eines Modells für einen bestimmten Input, um zu verstehen, wie dieser spezifische Input zum entsprechenden Output führt. Bein Beispiel sind Methoden, die einen spezifischen Input immer wieder leicht verändern und mit diesen neuen Varianten das Verhalten des Modells untersuchen.
Zusätzlich können die Methoden modellagnostisch oder modellspezifisch sein. Wir konzentrieren uns hier auf modellagnostische Methoden, die auf jede Art von KI-Modell angewendet werden können. Modellspezifische Methoden sind Methoden, die nur auf eine bestimmte Art von KI-Modell angewendet werden. Im Folgenden fassen wir einige der gängigsten modellagnostischen XAI-Methoden für tabellarische Daten zusammen.
Globale Methoden
Global Surrogate Models
Bei diesem Ansatz wird das Verhalten eines Black-Box-Modells mithilfe eines erklärbaren Modells analysiert. Hierfür wird lediglich ein Datensatz von Inputs und Outputs der Black-Box benötigt. Mit der Hilfe dieses Datensatzes lässt sich dann ein erklärbares Modell, wie z. B. eine lineare Regression trainieren. Es ist jedoch Vorsicht geboten, denn die Qualität dieser „Erklärung“ hängt stark von der Qualität des Datensatzes ab. Außerdem kann es sein, dass das simplere erklärbare Modell nicht in der Lage sind, die komplexe Entscheidungslogik des Black-Box-Modells abzubilden. Lässt sich andersherum ein vereinfachtes Ersatzmodell finden, das den Output des komplexen Modells vollständig nachbilden kann, so lässt sich natürlich die Komplexität des untersuchten Modells infrage stellen.

Permutation Feature Importance
Das Konzept hinter dieser Methode ist relativ simpel: Wenn ein Feature wichtig für die Entscheidung eines KI-Modells ist, sollte sich die Vorhersagequalität des Modells verschlechtern, wenn dieses Feature unkenntlich gemacht wird. Um dies zu testen, werden in einem Datensatz die Werte eines Features über alle Beispiele zufällig gemischt, sodass kein sinnvoller Zusammenhang zwischen dem neuen Wert des Features und dem Zielwert für ein Beispiel mehr besteht. Wenn dies den Fehler, den das KI-Modell in seinen Vorhersagen macht, deutlich erhöht, wird das Feature als wichtig bewertet. Ist dies nicht der Fall, oder nur in einem geringeren Maße, wird das Feature als weniger wichtig angesehen.
Causal Discovery
Eine interessante, jedoch etwas komplexere Methode ist Causal Discovery. Hier wird auf Basis der Korrelationsmatrix der Daten ein ungerichteter Graph erstellt. Dieser Graph verbindet alle Features und Ergebnisvariablen in einem Netzwerk – dem Graphen. Dieses Netzwerk wird dann mithilfe von Optimierungsverfahren auf die notwendige Größe und Komplexität reduziert. Das Ergebnis ist ein Graph, aus dem sich Kausalitäten ableiten lassen. Genauer gesagt kann man intuitiv den Effekt der einzelnen Features auf das Ergebnis des Modells aus dem Graph entnehmen. Allerdings kommen auch solche Verfahren nicht mit Garantien. Verlässliche und stabile Ergebnisse für solche Erklärungsmodelle sind insofern schwierig zu erhalten, weil die resultierenden Graphen oft sehr sensibel vom gewählten Input abhängen.
Lokale Methoden
Local Surrogate Models (LIME)
Bei LIME (Local interpretable model-agnostic explanations) geht es darum, ein lokales „Surrogate Model“ für ein Beispiel zu trainieren. Einfacher gesagt: Mit LIME wird ein definierter Input (ein Beispiel) genommen, dieser durch das Black-Box-Modell prozessiert und anschließend wird der Output analysiert. Nun werden die Features des Beispiels jeweils einzeln leicht verändert und das neue Beispiel wird wieder durch das Black-Box-Modell geschickt. Dieser Prozess wird vielfach wiederholt. Dadurch lässt sich, zumindest um den Punkt des initialen Beispiels herum, ein erklärbares Modell erstellen, das den Einfluss der Features auf den Output ersichtlich macht. Am Beispiel einer automatischen Claimverarbeitung eines KFZ-Versicherers würde dies bedeuten, die Features eines Claims immer wieder leicht zu verändern (Fahrzeugtyp, Alter, Geschlecht, Summe, etc.) und zu testen, wie sich die Entscheidung des KI-Modells daraufhin verändert.
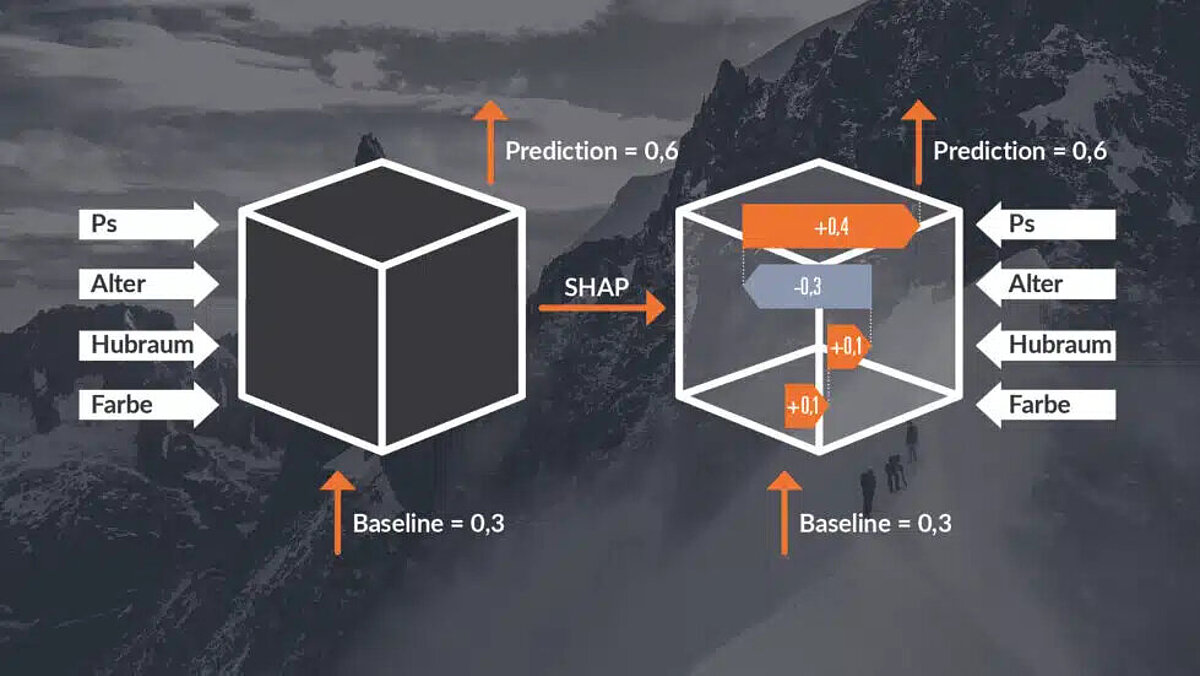
SHAP
Mithilfe von SHAP (SHapley Additive exPlanations) lässt sich analysieren, wieviel Einfluss welche Features auf die Vorhersage des Modells für ein bestimmtes Beispiel haben. Dabei geht SHAP so vor, dass mittels Permutation der Features des Inputs analysiert wird, wie wichtig gewisse Features für den Output sind. Permutation bedeutet in diesem Fall, dass die Werte für bestimmte Features mit den Werten von anderen Beispielen im Datensatz ersetzt werden. Diese Idee basiert auf den aus der Spieltheorie stammenden Shapley Values. Der Output eines Modells wird als der Gewinn eines kooperativen Spiels verstanden, während die Features die Spieler darstellen. Durch die Permutationen wird ermittelt, wieviel die einzelnen „Spieler“ (Features) zum „Gewinn“ (Output) beitragen. Ein großer Vorteil von SHAP ist, dass es sowohl lokale als auch globale Erklärungen produzieren kann. SHAP zählt zu den beliebtesten XAI-Methoden, obwohl durch die sehr hohe Anzahl an Permutationen erhebliche Rechenkapazitäten nötig sind.
CXPlain
CXPlain ist eine neuere Methode, die versucht, die Stärken von Methoden wie LIME oder SHAP zu erhalten, aber die Nachteile, wie hohe Rechenzeiten, zu vermeiden. Anstatt ein erklärbares Modell zu trainieren, das das Black-Box-KI-Modell emuliert oder eine hohe Anzahl von Permutationen zu testen, wird bei CXPlain ein eigenständiges Modell trainiert, das die Wichtigkeit der einzelnen Features schätzt. Das Modell wird auf Basis der Fehler des originalen Black-Box-KI-Modells trainiert und kann so eine Schätzung abgeben, welche Features den größten Beitrag zu der Vorhersage des Black-Box-KI-Modells liefern. Darüber hinaus liefert CXPlain eine Schätzung darüber ab, wie sicher das Modell in seinen Vorhersagen ist – und damit auch, mit welcher Unsicherheit die Ergebnisse behaftet sind. Dies ist bei anderen XAI-Methoden nicht der Fall.
Counterfactuals
Was müsste sich am Input ändern, damit sich der Output ändert? Diese Frage stellt man sich bei der Nutzung von Counterfactuals. Hierbei wird ermittelt, was die minimal nötigen Änderungen sind, damit sich der Output eines Modells verändert. Um dies zu ermöglichen, werden neue synthetische Beispiele erzeugt und die besten selektiert. Am Beispiel eines „Creditscoring“: Um wieviel muss das Alter oder Vermögen der anfragenden Person verändert werden, damit ein Kredit gewährt statt abgelehnt wird. Bewirkt z. B. eine Änderung des Geschlechts von „weiblich“ auf „männlich“ eine Gewährung des Kredits? So lassen sich beispielsweise ungewünschte Verzerrungen oder „Biases“ in den Vorhersagen des Modells erkennen. Ähnlich verhält es sich beim Beispiel der automatischen Claimverarbeitung einer Kfz-Versicherung. Wir stellen die Frage: „Welche Merkmale des Versicherungsnehmers müssten mindestens verändert werden, um die Entscheidung des Modells zu verändern?“
Warum nicht direkt White-Box-Modelle bauen?
Generell beziehen sich alle hier beschriebenen Methoden auf Post-Hoc-Interpretation von Modellen. Allerdings darf auch nicht vergessen werden, dass viele Probleme auch schon mit bestehenden nachvollziehbaren Modellen gelöst werden können. Verfahren wie Regressionen oder Decision Trees können viele Business-Usecases lösen und sind dabei erklärbar. Allerdings machen es besonders komplizierte oder größere Probleme nötig, komplexere Modelle zu verwenden. Um diese erklärbar zu machen, nutzen wir in der Praxis unter anderem die hier beschriebenen Methoden. Erklärbare Modelle zu produzieren, ist aktuell eines der Kernanwendungsgebiete von KI. Dies wird besonders durch aktuelle Gesetzgebungen wie der European AI-Act unterstrichen, der Erklärbarkeit zu einer verpflichtenden Eigenschaft von KI-Modellen in kritischen Bereichen macht. Natürlich ergibt es auch intuitiv Sinn, erklärbare Modelle zu bevorzugen. Wer möchte schon in einem autonom fahrenden Auto sitzen, das von einer KI gesteuert wird, die so komplex ist, dass nicht einmal die Hersteller wissen, wie und warum die KI ihre Entscheidungen trifft.
Diesen Beitrag teilen: