Model Context Protocol im Blitzlicht
Ein neuer Standard für Service-Integrationen in LLM-Anwendungen
- Veröffentlicht:
- Autor: Dr. Bert Besser, Dr. Johannes Nagele
- Kategorie: Deep Dive
Inhaltsverzeichnis
")
Das Model Context Protocol (MCP), eingeführt von Anthropic im November 2024, bringt frischen Wind in die Architektur von LLM-Anwendungen: Es vereinfacht und standardisiert die Integration von Drittanbieter-Servern und externen Datenquellen und macht es deutlich leichter, verschiedenste externe Dienste anzubinden. Als neuer, breit akzeptierter Standard schafft MCP die Grundlage dafür, dass die Vielfalt an verfügbaren Datenquellen und Services weiter wächst.
Dieser Artikel gibt einen verständlichen Überblick über MCP und erklärt die zentralen Konzepte und den Grundgedanken auf leicht zugängliche Weise. Dabei werfen wir auch einen Blick auf einen technischen Aspekt: die Sicherheitsrisiken und potenziellen Angriffsflächen, die im Zusammenhang mit MCP entstehen können.
Wir starten mit einem Blick darauf, wie MCP-Anwendungen grundsätzlich aufgebaut sind, tauchen dann tiefer in zwei zentrale Funktionen ein – Funktionsaufrufe und den Umgang mit Datenressourcen – und schließen mit einem Überblick der wichtigsten Sicherheitsherausforderungen, die Entwickler im Blick behalten sollten.
MCP-Architektur einfach erklärt
Model Context Protocol aus der Vogelperspektive
Mit dem Model Context Protocol (MCP) lassen sich LLM-Anwendungen auf standardisierte Weise mit Geschäftsdaten und -funktionen verbinden, mithilfe eines standardisierten Protokolls. MCP ist ein wichtiger Schritt hin zu einer einfacheren und konsistenteren Integration externer Systeme und Datenquellen.
Die nachfolgende Abbildung bietet einen Überblick aus der Vogelperspektive. In den folgenden Darstellungen zoomen wir Schritt für Schritt näher heran und zeigen, wie MCP im Detail funktioniert.
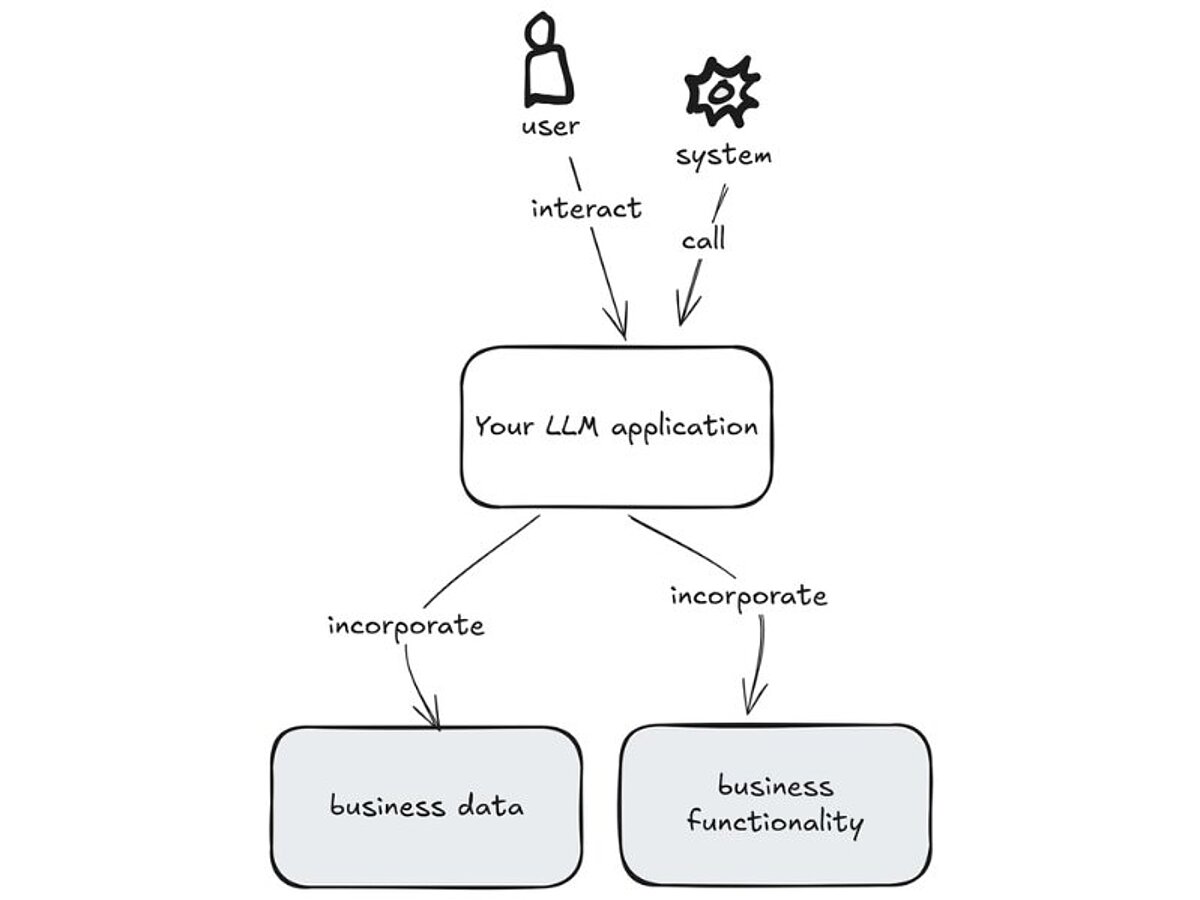
Autonome Nutzung von Metadaten
Ihre LLM-Anwendung beschränkt sich nicht nur auf den Aufruf von LLM-APIs. Sie kommuniziert auch mit zusätzlichen Drittanbieter- oder eigenen Servern, sammelt (Text-)Daten aus verschiedenen Quellen und orchestriert diese Aufrufe so, dass am Ende eine sinnvolle und konsistente Antwort entsteht. Das bedeutet:
- Der Anwendungsentwickler (zum Beispiel Sie) bestimmen, welche zusätzlichen Server zugelassen werden.
- Jeder Server stellt Metadaten über die bereitgestellten Daten und Funktionen zur Verfügung.
- Ihre Anwendung ruft die zusätzlichen Server nach Bedarf auf, um Funktionen auszulösen, deren Ergebnisse zu erhalten und Daten abzurufen. Welche Daten oder Funktionen aufgerufen werden sollen, richtet sich nach den bereitgestellten Metadaten (d. h. Sie müssen die Auswahl oder die Aufrufe nicht explizit implementieren).
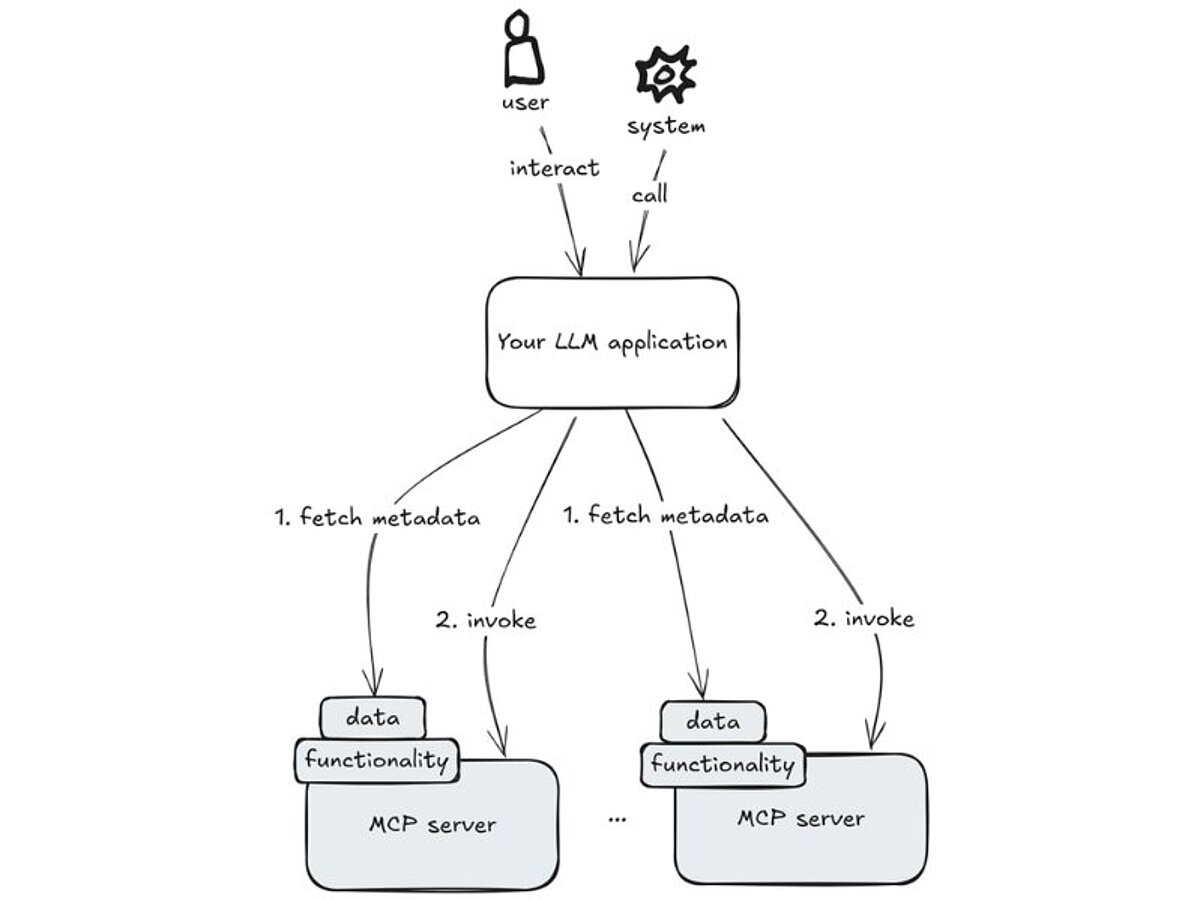
Sie übergeben also Ihrer Anwendung ein Stück weit die Kontrolle darüber, welche Funktionen und Daten genutzt werden sollen. Damit dieses autonome Verhalten in die gewünschte Richtung läuft, kommt es darauf an, Prompts und Metadaten entsprechend klug zu gestalten.
Aufrufreihenfolge der involvierten Systeme
Im Hintergrund promptet Ihre Anwendung das LLM nicht nur mit der eigentlichen Aufgabe, sondern fordert es auch dazu auf, bei Bedarf passende Daten oder Funktionen auszuwählen (falls nötig). Grundlage für diese Entscheidung sind Metadaten, die Ihre Anwendung zuvor von den angebundenen Servern abgerufen hat – also Informationen darüber, welche Daten und Funktionen zur Verfügung stehen. Entscheidet das LLM einen Aufruf durchzuführen, übernimmt Ihre Anwendung diesen Schritt stellvertretend, ruft die ausgewählte Funktion oder Ressource ab und gibt die erhaltenen Daten oder Ergebnisse an das Sprachmodell zurück. (Dabei bleibt der bisherige Gesprächsverlauf im Prompt-Kontext erhalten.) Die folgende Antwort des LLMs kann entweder das finale Ergebnis sein, das an den Nutzer weitergegeben wird, oder der Start einer weiteren Runde von Serveraufrufen.
Eine Beispielanwendung, um dieses Verhalten zu testen, ist Claude Desktop.
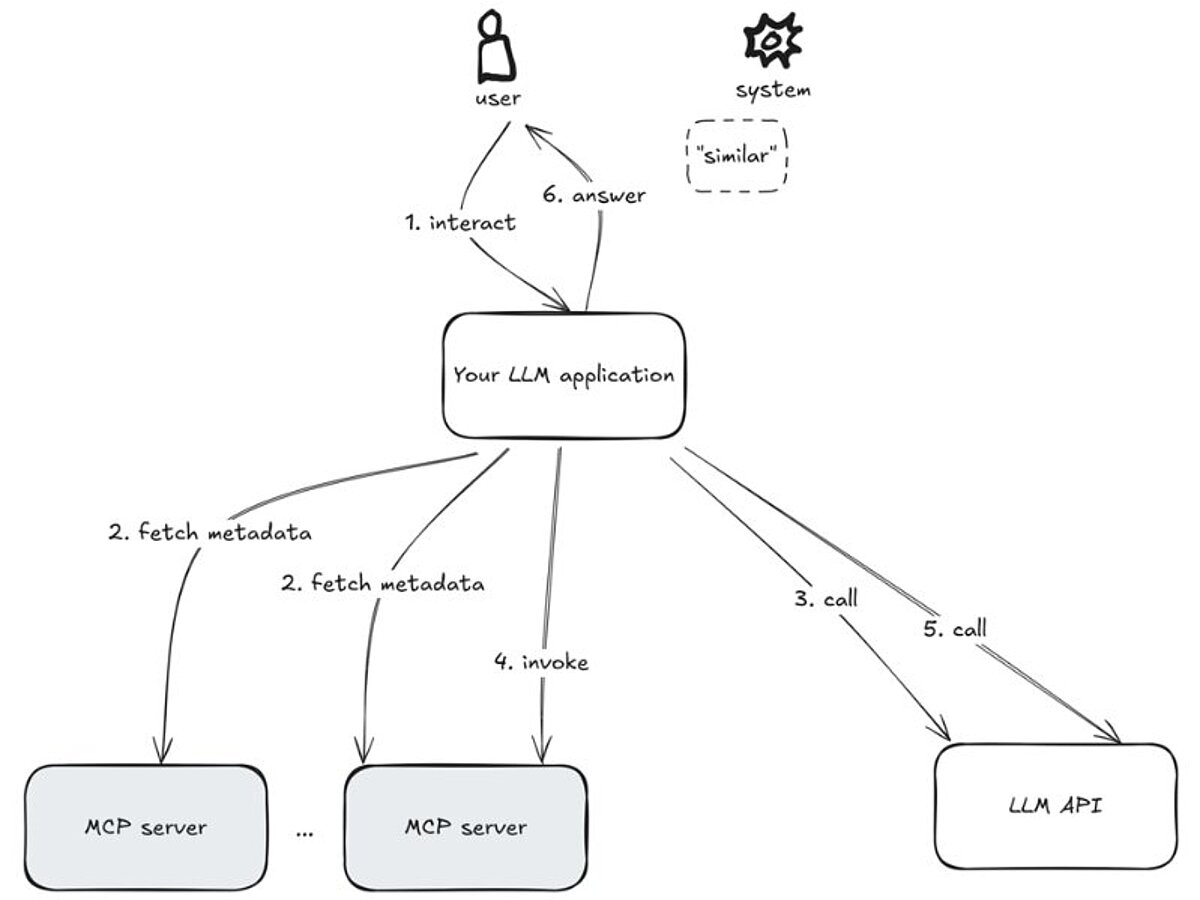
All dies ist in MCP-SDKs wie der Open-Source-Referenzimplementierung in Python bereits implementiert, sodass Sie sich auf die Bereitstellung geeigneter Prompts und Servern mit entsprechenden Daten und Funktionen konzentrieren können.
In diesem Artikel gehen wir nicht auf konkrete SDKs oder Codebeispiele ein. Im Fokus stehen vielmehr die grundlegenden Ideen hinter MCP – und wie das Protokoll darauf abzielt, die technischen und organisatorischen Grundlagen für den weltweiten Einsatz von LLM-Anwendungen in Zukunft maßgeblich zu erweitern. Wer tiefer in die technischen Details wie Protokollschichten oder Lebenszyklen einsteigen möchte, findet hier detaillierte Einblicke.
Anwendungsbereiche des Model Context Protocol
Da sich der MCP-Standard noch in einer frühen Phase befindet und die Entwicklungen in diesem Bereich rasant voranschreiten, liegen bisher nur begrenzte Erfahrungen im unternehmensweiten Einsatz vor. Zudem zeigen aktuelle Sicherheitserkenntnisse, dass die Einsatzmöglichkeiten derzeit noch eingeschränkt sind. Dennoch gewinnt MCP stark an Bedeutung, wie beispielsweise an der Ankündigung von Microsoft zur Entwicklung eines C# SDK oder OpenAI sowie Google (MCP Toolbox for Databases (ehemals Gen AI Toolbox for Databases) unterstützt nun Model Context Protocol (MCP) | Google Cloud Blog) und IBM (Entfesseln Sie die Produktivitätsrevolution mit KI-Agenten, die über Ihren gesamten Stack hinweg arbeiten) zu sehen ist.
Der nächste Abschnitt gibt einen Überblick über zentrale Anwendungsfälle und Einsatzbereiche von MCP.
Vereinfacht gesagt, fungiert MCP als Vermittlungsschicht zwischen Ihrer Anwendung und beliebigen REST-APIs – und erleichtert so die Anbindung von Business-Servern an LLM-Anwendungen. Dadurch kann Ihre Anwendung beispielsweise mit folgenden Systemen interagieren:
- JIRA,
- Hubspot,
- KI-Agenten,
- Modell-Register,
- Zeiterfassungssysteme,
- Chat-Plattformen,
- Container-Orchestratoren,
- Automatisierungsplattformen für die Integration,
- Benachrichtigungsdienste,
- Dokumentenspeicher,
- Datenbanken,
- Code-Repositories,
- Wikis,
- alles, was eine REST-Schnittstelle bietet (es gibt sogar experimentelle MCP-Server, die genau das tun sollen - MCP-Unterstützung zu jedem REST-Dienst hinzufügen).
Darüber hinaus stellt ein MCP-Server sogenannte Ressourcen zur Verfügung, die Geschäftsdaten sowohl in Text- als auch in Binärformaten darstellen, also Datenbankeinträge, Dokumente, Bilder oder PDF-Dateien. Ihre Anwendung ruft die Metadaten über verfügbare Ressourcen von einem MCP-Server ab, wenn dies für die Erfüllung der jeweiligen Aufgabe erforderlich ist.
Dynamische Funktionen und Ressourcen
Die Daten, die ein MCP-Server bereitstellt, können sich laufend ändern, denn sie spiegeln in der Regel den aktuellen Zustand eines Systems wider. Eine Chat-App könnte MCP zum Beispiel nutzen, um aktuelle Alarme aus einer Datenbank abzurufen oder gezielt nach Mitarbeitenden mit bestimmten Fähigkeiten zu suchen – inklusive der neuesten Teammitglieder.
Praktisches Anwendungsbeispiel
Ein typischer Anwendungsfall für eine LLM-Anwendung mit MCP-Servern ist die Erweiterung eines automatisierten Workflows (etwa in einem CRM) um einen Schritt, der Servicemitarbeitenden vorformulierte Antworten auf eingehende Kundenanfragen bereitstellt. In diesem Szenario könnte ein MCP-Server den aktuellen Kommunikationsverlauf mit dem Kunden aus einem NoSQL-Dokumentenspeicher abrufen. Zur Bewertung der Lösung bieten sich Kennzahlen wie die operative Effizienz oder die Relevanz der generierten Antworten an.
Sicherheitsrisiken
Natürlich gelten auch für die von MCP-Servern bereitgestellten Funktionen und Daten die üblichen und weit verbreiteten Sicherheitsanforderungen: Zugangskontrollen, Verschlüsselung, Audits, Rate-Limiting. Auch hier gilt: die Angriffsfläche sollte so klein wie möglich gehalten werden.
Darüber hinaus gibt es neuere Sicherheitsrisiken, die vor allem darauf abzielen, LLMs zu unerwünschtem Verhalten zu verleiten. Diese Gefahren sind zwar nicht spezifisch für MCP, doch mit der wachsenden Verbreitung des Protokolls nimmt auch die potenzielle Angriffsfläche zu. Ein solcher Angriff wird als Tool Poisoning bezeichnet, bei dem ein MCP-Server betrügerische Metadaten ausspielt. Die Metadaten über verfügbare Tools werden an das LLM gesendet, doch die Textbeschreibung enthält bösartige Anweisungen. Ein Beispiel dafür ist, dass eine LLM-Anwendung sensible Daten preisgibt: Die Autoren brachten den Cursor-IDE-Agenten dazu, Sicherheitsschlüssel an den Angreifer zu senden. Ein weiteres Beispiel ist ein MCP-WhatsApp-Server, der private Informationen an eine unbekannte Telefonnummer (des Angreifers) sendet.
Die Autorisierung in MCP-Servern stellt ebenfalls eine potenzielle Angriffsfläche dar, wie dieser Artikel zeigt, und muss für einen weit verbreiteten Einsatz in Unternehmen sicher gemacht werden.
Fazit
MCP findet derzeit schnell Verbreitung – ein deutliches Zeichen dafür ist die Integration von MCP-Unterstützung in das SDK von OpenAI. Es ist gut möglich, dass MCP die Architektur von LLM-Anwendungen nachhaltig verändern wird. Daher lohnt es sich, frühzeitig in die Analyse möglicher Einsatzszenarien für das eigene Unternehmen zu investieren.
Gleichzeitig birgt der Einsatz in unbekannten Umgebungen mit nicht vertrauenswürdigen oder ungeprüften MCP-Servern Sicherheitsrisiken. Ein möglicher Ansatz für eine sichere Einführung ist der Einsatz eigener MCP-Server, die den Systemzustand nicht verändern, sondern lediglich zusätzliche Metadaten auslesen oder mit Anmerkungen versehen – kombiniert mit LLM-Anwendungen, deren Wirkungskreis gezielt eingeschränkt ist.
Neben MCP entstehen aktuell auch weitere sogenannte „Agentenprotokolle“ wie ACP oder A2A, deren Entwicklung und Verbreitung im Vergleich zu MCP genau beobachtet und bewertet werden sollte. Neue Protokolle richten sich an unterschiedliche Anwendungsbedürfnisse: etwa die Anbindung von KI-Agenten an Ressourcen, die Koordination zwischen mehreren Agenten oder die direkte Interaktion zwischen Agenten und Menschen. In Zukunft wird die Auswahl passender Protokolle keine Entweder-oder-Entscheidung sein, sondern abhängig vom konkreten Ziel und Kontext getroffen werden, wie Abbildung 4 in dieser Analyse zeigt.
Diesen Beitrag teilen: