An Introduction to AI-Ready Data
- Published:
- Author: [at] Editorial Team
- Category: Basics
Table of Contents
![AI-ready data, hero image, Alexander Thamm [at]](/fileadmin/_processed_/c/2/csm_ai-ready-data_d7ef4f5088.jpg "AI-ready Data")
Most AI projects don't fail because of the model. They fail because of the data.
Despite growing investment in AI infrastructure, a 2024 survey by the IBM Institute for Business Value found that only 29% of technology leaders strongly agree their enterprise data meets the quality, accessibility, and security standards needed to efficiently scale generative AI. At the same time, Gartner notes that there are fundamental differences between traditional data management requirements and what AI systems actually demand, a gap that many organizations have yet to seriously close.
The concept of AI-ready data addresses both of these realities: it defines what data must look like to reliably power AI workloads, and provides a concrete framework to get there.
What is AI-Ready Data?
AI-ready data is not merely a file format or a cloud migration target. It is a comprehensive quality standard. While many organizations focus on moving data into the right cloud bucket or converting it to a specific schema, true readiness is defined by whether the data is fit for the unique demands of machine learning and autonomous reasoning.
It operates on the core principle of "Garbage In, Garbage Out". If the input data is inaccurate, biased, or incomplete, the model's output will be unreliable at best and actively harmful at worst, producing flawed decisions or hallucinations in generative systems. Readiness, as Gartner frames it, cannot be achieved generically in advance: it is always relative to a specific use case, the AI technique being applied, and the trust level expected from the output.
Unlike traditional analytics, which often removes outliers to "clean" reports for human consumption, AI-ready data must be representative. In conventional Business Intelligence (BI), the standard move is to strip out anomalies, like a one-day spike in website traffic or a corrupted sensor reading, to provide executives with a "smooth" trend line that is easy to interpret. That makes sense for human consumption.
However, AI models work the opposite way. They need to see the world in all its messiness to learn from it. To be truly ready, data must include real-world patterns, errors, and anomalies so the model can learn from actual complexities. For instance, in Fraud Detection, the "clean" data is actually the least useful; the model needs to see the outliers, the suspicious edge cases, and the transactions that look nothing like normal behavior to understand what a crime looks like. Similarly, in Predictive Maintenance, sensor data that fluctuates wildly right before a mechanical failure is technically "low quality" by traditional standards, but for an AI, that "noise" is the critical signal it needs to save the company millions in repairs.
The scale of the problem becomes clearer when you look at unstructured data. In practice, AI-ready data must cover both structured data (transactional records in ERP and CRM systems) and unstructured data (documents, emails, PDFs, images). Unstructured data currently represents the vast majority of enterprise data, yet less than 1% of it exists in a format suitable for direct AI consumption. This structural imbalance is one of the core reasons why only 16% of AI initiatives have reached enterprise scale, according to the IBM IBV 2025 CEO Study.
AI-ready data is therefore not defined by a single attribute, but by the simultaneous presence of four foundational conditions: it must be unified and accessible, governed, secure, and supported by the right tooling and skills. These conditions collectively determine whether data can be trusted as input for AI systems, and whether the outputs of those systems can in turn be trusted by the organization.

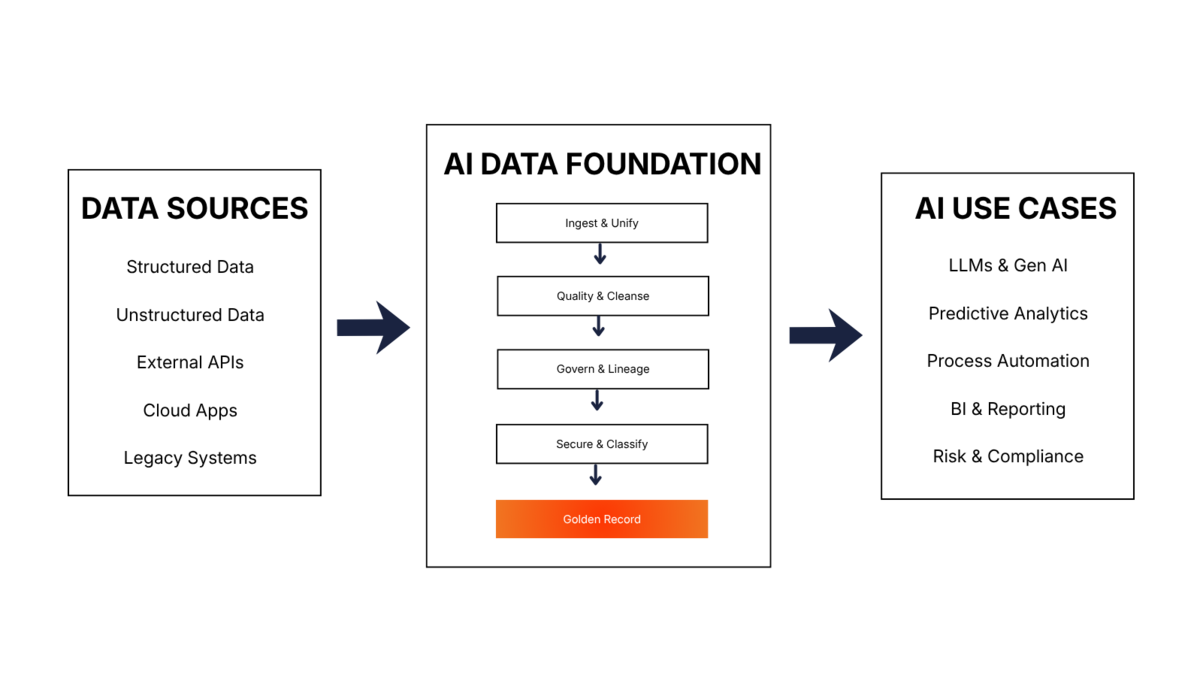
How do I make my Data AI-Ready?
Preparing data for systems like LLMs requires a rigorous process to ensure that the information is not only available but also rich in context. This is achieved through a “data readiness pipeline”:
Challenges
Many AI projects fail not because of the model, but because of the data. It often becomes apparent only late in the process that relevant information is scattered across numerous systems: customer data in Salesforce, transactions in SAP, product specifications in spreadsheets, support tickets in external tools, and on top of that, a data lake whose contents hardly anyone can keep track of anymore. Different responsibilities, update cycles, and access models make unified access difficult—even though this is precisely what is crucial for AI.
Furthermore, data quality must be understood differently in the AI context than in traditional data processing. Errors, duplicates, and missing values remain problematic. At the same time, excessive “cleaning” of data can be harmful: outliers, edge cases, and unusual patterns are often precisely the signals that classification or anomaly detection models require. Data quality is therefore not a universal standard, but always depends on the specific use case.
Another key problem is the skills and infrastructure gap. Many data teams must operate existing systems in parallel while simultaneously meeting new AI requirements. Often, there is a lack of experience and processes for embedding pipelines, RAG architectures, vector databases, or annotations. Handling unstructured data such as documents, PDFs, emails, images, or chat logs is particularly challenging. These are precisely the types of data that often contain the most valuable operational context, yet require their own preprocessing, vectorization, and metadata workflows.
As AI usage grows, regulatory and security-related pressure also increases. Those who work with sensitive data simultaneously increase their attack surface—for example, through data leaks, prompt injection, or insecure retrieval pipelines. Without robust data governance, this results not only in technical debt but also in compliance and reputational risks. Gartner also emphasizes that bias, representativeness, and fairness are not merely model-level issues but must be addressed through governance at the data source level.
Benefits
When companies build a clean data foundation for AI, they create not just a one-time benefit but a sustainable lever. A consolidated, cleanly classified, and governed dataset can support not just a single use case, but several at once: such as search, forecasting, recommendations, or optimization. The key advantage is that data preparation does not have to start from scratch for every new AI project. With each subsequent initiative, the effort decreases because the foundation is already in place.
This is directly reflected in model performance. Consistent, reliable, application-ready, and well-annotated data noticeably improves the quality of AI systems: it reduces hallucinations in LLMs, increases the accuracy of classification and forecasting models, and shortens training and development cycles. Teams then spend significantly less time on cleaning, matching, and manual rework and can focus more on development, evaluation, and iteration.
A second key advantage lies in governance and compliance. When quality rules, lineage, versioning, and access policies are considered from the outset, AI systems can be better audited, explained, and made compliant with regulations. This is particularly important in highly regulated sectors such as financial services, healthcare, or pharmaceuticals. At the same time, versioned and monitorable datasets create the conditions necessary to track model behavior, drift, and data shifts even during ongoing operations.
Strategically, this translates into scalable business value. Well-organized data becomes a shared infrastructure layer that multiple AI applications can access in parallel without creating duplicate work. In this way, data quality evolves from a project-based effort into a sustainable capability. AI readiness is then not a one-time achievement, but a continuously maintained operational competency.
Cheat Sheet for Companies
The table below summarizes the core characteristics that define AI-ready data and the significance of each in the context of AI systems deployment. The first three columns reflect widely accepted data readiness attributes from IBM and Gartner. The Gartner-specific notes in the final column reflect the use-case-dependent perspective that distinguishes AI readiness from general data quality.
| Characteristic | Description | Significance for AI |
|---|---|---|
| Unified & Accessible | Data from disparate sources is consolidated into a single, queryable view across databases, data lakes, and cloud apps. | AI models cannot act on data they cannot reach. Fragmented access limits context, coverage, and cross-domain reasoning. |
| Use-Case Fit | Data is evaluated and validated against the specific requirements of each AI use case, including volume, diversity, and technique. | There is no generic AI-readiness. A dataset appropriate for one model may be unsuitable or actively harmful for another. |
| Accurate & Complete | Records are free of errors, duplicates, and missing fields. Data quality scores are actively measured and enforced. | Inaccurate or incomplete training data directly produce unreliable, biased, or misleading model outputs. |
| Representative & Diverse | Data covers the full range of patterns, edge cases, and outliers relevant to the AI task, including those filtered out by traditional quality standards. | Cleaning out outliers can remove variance that classification and anomaly detection models require. Diversity of sources prevents training bias. |
| Governed | Clear ownership, quality rules, lineage tracking, versioning, and approval workflows are defined and enforced across the data lifecycle. | Enables auditability, regulatory compliance (GDPR, EU AI Act, BCBS 239), and the long-term sustainability of data quality. |
| Secure | Role-based access controls, data masking, and privacy enforcement are embedded at the data layer, not bolted on afterward. | Protects sensitive data from exposure through AI queries or model outputs; required for compliance in regulated industries. |
| Current & Versioned | Data is regularly updated and time-stamped. Stale records are flagged. Version history is maintained to detect and manage model drift. | AI systems operating on outdated data produce decisions that no longer reflect operational reality. Versioning enables regression testing and drift detection. |
| Labeled & Annotated | Data is tagged, semantically annotated, and formatted for AI consumption, including unstructured content like documents and images. | Labeling quality, especially for image, video, and document data, is a critical and often underestimated prerequisite for supervised learning and LLM grounding. |
| Supported | Tooling, pipelines, and skilled personnel are in place to monitor, orchestrate, validate, and continuously improve data quality. | AI-readiness degrades without ongoing human oversight, engineering support, observability metrics, and automated quality monitoring. |
Conclusion
AI-ready data is not a one-time deliverable. It is a continuous operational capability. The organizations most likely to succeed with AI are those that treat data quality, governance, security, and accessibility not as pre-project checkboxes, but as engineering disciplines embedded into their data infrastructure from the ground up. As Gartner makes clear, this also means moving away from the notion of a single universal data standard: readiness must be assessed, validated, and governed relative to each specific AI use case and the trust levels it demands.
The path forward is structured but not simple: assess current readiness honestly, secure executive alignment early, close the gap between traditional data management and AI-specific requirements, and build the governance and tooling to sustain quality as models scale. Organizations that achieve this will not just run better AI models. They will build the data infrastructure that makes every future AI initiative faster, cheaper, and more reliable than the last.
Share this post: