
Learn how Convolutional Neural Networks helps machines understand information they see. Basically, machines mimic processes of the human brain. We take you through the stages of development of these algorithms and also show how machines learn to see.
Computer vision, or machine vision, has long been one of the most challenging areas of artificial intelligence development. In recent years, however, great progress has been made in this area. Training machines to be able to interpret images and what they "see" via camera sensors is critical for many applications. For example, autonomous systems such as cars or other means of transport need to understand their Be able to perceive and interpret the environmentin order to be used safely and sensibly. Thanks to the development of Convolutional Neural Networks, a breakthrough has been achieved in recent years.
Inhaltsverzeichnis
What is a Convolutional Neural Network?
A Convolutional Neural Network (CNN) is a special form of neural network. These networks are represented by artificial neurons and are used, for example, in the field of artificial intelligence.
At Artificial neural networks are machine learning techniques inspired by the biological processes in the human brain. The neurons are interconnected and linked with different weights. The goal in the learning process of a neural network is to adjust these weights so that the model can make the most accurate predictions possible.
The Convolutional Neural Network takes its name from the mathematical principle of convolution. This mathematical procedure is particularly suitable for the recognition of image and audio data. The reduction of data resulting from convolution increases the speed of the calculations. This can shorten the learning process. However, the performance does not decrease as a result.
Convolutional neural networks are multilayer, forward-coupled networks. With layers appropriately connected in series, they are able to develop an intuition that leads, for example, from the recognition of details (lines) to the recognition of the abstract (edges, shapes, objects). With each higher layer, the level of abstraction increases.
The structure
When setting up a CNN, a wide variety of camp groups are used one after the other.
Convolutional Layer
This layer implements various filters and integrates them into the neural network. In the process, a convolution matrix (kernel) is placed over the pixel values. The weights of the kernels are each differently dimensioned. By calculating with the input values, different features (edges and features) can be extracted.
Pooling Layer
This layer is used to better generalise the data.
Through the pooling layer (Max Pooling), the strongest features are forwarded.
The dimensions of the input data, for example the number of pixels in images, determine how many pooling layers can be applied.
Flatten Layer
The multi-dimensional layer from the convolutions is converted into a one-dimensional vector.
Drop Out Layer
It can happen that neural networks limit themselves too much to one or more input parameters. For this reason, drop out can be used so that certain connections of the input data are no longer passed on. This ensures that the network does not rely too heavily on a specific value and finds a suitable connection regardless of a specific connection.
Dense Layer
The Dense Layer is also called the Fully Connected Layer. This is a standard layer in which all neurons are connected to all inputs and outputs. The final classification takes place in the last Dense Layer.
Algorithms, computer speed & data
The three terms mentioned in the headline are the three ingredients that teach machines to see. Significant for the enormous progress in the field of machine vision was the mission of Fei-fei Li - a computer science professor at Stanford University. She wanted to teach computers something that children as young as about 3 years old could do. Machines should understand the meaning of what they "see" in pictures and be able to name it. Computer vision posed an almost insurmountable problem in the field of research on Artificial intelligence Li began by stating that three ingredients are necessary to teach computers to see. Li first established that three ingredients are necessary to teach computers to see:
- The corresponding Algorithms (Neural Networks)
- A sufficient Computer speed
- A large amount of Data (especially Labled Data)
As it turned out, surprisingly the Data the biggest challenge. Neural networks have been around since the 1950s.
Methods such as backpropagation have existed since the 1980s and Convolutional Neural Networks since the nineties. The corresponding computing power was also no longer a real problem in the mid-2000s - although a particular development played a role here.
However, although there is already the hype around Big Data gave, For a long time, data was not available in the formthat machines can really learn from them.
Description: TED Talk by Fei-fei Li in which she talks about the challenges of developing computer vision.
Labelled data
Labelled data helps machines learn to see. So that algorithms, such as Convolutional Neural Networks, understand what is in the pictures, they need data on the. These are necessary for the learning process in which they can learn to understand structures and differences. For example, algorithms need a large number of images. For example, in order to distinguish dogs from cats in pictures, they need a large number of pictures of which they know that there are cats in them.
In addition, they need pictures of which they know that there are dogs on them, for example. These so-called "labelled Data sets" can now compare them with each other to identify the structural differences between cats and dogs. The goal is to train a network that it can independently recognise images and recognises the difference between a dog and a cat.
Amazon's Mechanical Turk
Amazon's Mechanical Turk is a method of labelling data. The question was how to obtain labelled data that could be used to train Covolutional Neural Networks. One method for labelling data sets is Amazon's service called "Mechanical Turk".
This name goes back to a machine called the "Shaft Turk" - a machine that was claimed to be able to beat any human at chess. The trick, however, was that a dwarf sat inside the machine and performed the movements mechanically.

This idea is ultimately also the basis for Amazon's "Mechanical Turk". Tasks such as the labelling of data sets are not actually carried out by machines, but ultimately by a large number of people. Often, for example, it is people in India who label data on a large scale - such as image data with the label "dog" or "cat". Also Fei-fei Lis Work based on the assistance of thousands of peoplewho added labels to millions of images.
Shallow Networks
Based on this labelled data, the next step could then take place. The goal was to find the best algorithms for this task. The first successful candidates were so-called Shallow Networks - a special form of Deep Networks.
Around the year 2000, another change occurred that had far-reaching consequences in the development of computer vision. Within the framework of a competition by Nvidia, it was determined that Deep Learning could be used by the Deployment of CPUs and GPUs (graphics chips) could be improved by a factor of 100 to 1000.
This particular development was instrumental in increasing computing power. AlexNet was the first successful model that attempted to do just that. The success was nothing less than a quantum leap: for the first time it was possible to use Deep Models. A few years later, the VGG to the best model.
Despite these initial successes, however, the motto was: "We need to go deeper" - a quote from the film "Inception" by Christopher Nolan, on which the name of Google's "InceptionNet" from 2014 was actually based.
In 2015, Microsoft also followed this motto with ResNet and since then, machines have indeed been better than humans at solving the, for example, distinguishing between dogs and cats in pictures, machine vision.
Behind the success: Convolutonal Neural Networks.
Understanding images
Convolutional Neural Networks enable machines to understand images. Simply put, Convolution Neural Networks are algorithms that enable machines to understand what they see. A Artificial Neural Network (KNN) mimics, to put it simply, what happens in the human brain between the individual neurons. KNNs are based on a form of neurons, i.e. nodes that are linked to each other. Analogous to neuronal connections, KNNs are structured in a certain number of "layers".
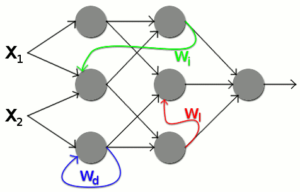
The difference between KNNs and Convolutional Neural Networks is that in Convolutional Neural Networks certain information is processed in a distilled, "folded" form. In this distilled form, an image, as it appears to humans, is given a new formthat is understandable for machines. In other words: it gets more depth, or more layers. At the end of this process there is a result: a Classifierwhich enables machines to recognise the representations on images.
Use for damage detection after natural disasters

The practical relevance of Convolutional Neural Networks can be demonstrated with a simple example. After natural disasters, such as hail damage, insurers are faced with a major challenge. Their Clients need help as soon as possiblebut the process necessary to detect damage is lengthy.
With the help of computer vision, this can be Solve problem elegantly. Instead of experts who would have to travel to the affected regions to assess the damage, pictures of the damage are evaluated.
With the help of Convolutional Neural Networks, it is possible to distinguish between houses with damaged or intact roofs. In this way, it is possible to determine within a short time whether and to what extent a certain region is affected by hail damage. An abundance of cases can thus be significantly Processed faster and necessary assistance can be provided more quickly. This is just one of many possible application areas where Convolutional Neural Networks can help provide solutions quickly and effectively. What led to the revolution of Image recognition is now a standard feature of data science projects.








{kind=link}
{kind=link}
0 Kommentare