KI-fähige Daten: Eine Einführung
- Veröffentlicht:
- Autor: [at] Redaktion
- Kategorie: Grundlagen
Inhaltsverzeichnis
![AI-ready data, hero image, Alexander Thamm [at]](/fileadmin/_processed_/c/2/csm_ai-ready-data_d7ef4f5088.jpg "AI-ready Data")
Die meisten KI-Projekte scheitern nicht am Modell. Sie scheitern an den Daten.
Trotz wachsender Investitionen in die KI-Infrastruktur ergab eine Umfrage des IBM Institute for Business Value aus dem Jahr 2024, dass nur 29 % der Technologieführer der Aussage voll und ganz zustimmen, dass ihre Unternehmensdaten die Qualitäts-, Zugangs- und Sicherheitsstandards erfüllen, die für eine effiziente Skalierung generativer KI erforderlich sind. Gleichzeitig stellt Gartner fest, dass es grundlegende Unterschiede zwischen den Anforderungen des traditionellen Datenmanagements und den tatsächlichen Anforderungen von KI-Systemen gibt – eine Lücke, die viele Unternehmen noch nicht ernsthaft geschlossen haben.
Das Konzept der KI-fähigen Daten trägt beiden Realitäten Rechnung: Es definiert, wie Daten aussehen müssen, um KI-Workloads zuverlässig zu unterstützen, und bietet einen konkreten Rahmen, um dieses Ziel zu erreichen.
Was sind KI-fähige Daten?
KI-fähige Daten sind nicht nur ein Dateiformat oder ein Ziel für die Cloud-Migration. Sie sind ein umfassender Qualitätsstandard. Während sich viele Unternehmen darauf konzentrieren, Daten in den richtigen Cloud-Speicherbereich zu verschieben oder sie in ein bestimmtes Schema zu konvertieren, definiert sich echte Bereitschaft dadurch, ob die Daten für die besonderen Anforderungen von Machine Learning und Autonomous Reasoning geeignet sind.
Dies basiert auf dem Grundprinzip „Garbage In, Garbage Out“. Sind die Eingabedaten ungenau, verzerrt oder unvollständig, ist die Ausgabe des Modells im besten Fall unzuverlässig und im schlimmsten Fall sogar schädlich, da sie fehlerhafte Entscheidungen oder Halluzinationen in generativen Systemen hervorruft. Bereitschaft, wie Gartner es formuliert, lässt sich nicht pauschal im Voraus erreichen: Sie ist immer relativ zu einem bestimmten Anwendungsfall, der eingesetzten KI-Technik und dem von der Ausgabe erwarteten Vertrauensniveau.
Im Gegensatz zu herkömmlichen Analysen, bei denen oft Ausreißer entfernt werden, um Berichte für den menschlichen Gebrauch zu „bereinigen“, müssen KI-fähige Daten repräsentativ sein. In der konventionellen Business Intelligence (BI) ist es üblich, Anomalien wie einen eintägigen Anstieg des Website-Traffics oder einen fehlerhaften Sensorwert herauszufiltern, um Führungskräften eine „glatte“ Trendlinie zu liefern, die leicht zu interpretieren ist. Das macht für den menschlichen Gebrauch Sinn.
KI-Modelle funktionieren jedoch genau umgekehrt. Sie müssen die Welt in all ihrer Unordnung sehen, um daraus zu lernen. Um wirklich bereit zu sein, müssen Daten reale Muster, Fehler und Anomalien enthalten, damit das Modell aus tatsächlichen Komplexitäten lernen kann. Bei der Betrugserkennung sind beispielsweise die „bereinigten“ Daten tatsächlich am wenigsten nützlich; das Modell muss die Ausreißer, die verdächtigen Grenzfälle und die Transaktionen sehen, die überhaupt nicht wie normales Verhalten aussehen, um zu verstehen, wie ein Verbrechen aussieht. Ähnlich verhält es sich bei Predictive Maintenance: Sensordaten, die unmittelbar vor einem mechanischen Ausfall stark schwanken, sind nach traditionellen Maßstäben technisch gesehen von „geringer Qualität“, aber für eine KI ist dieses „Rauschen“ das entscheidende Signal, das sie benötigt, um dem Unternehmen Millionen an Reparaturkosten zu ersparen.
Das Ausmaß des Problems wird deutlicher, wenn man unstrukturierte Daten betrachtet. In der Praxis müssen KI-fähige Daten sowohl strukturierte Daten (Transaktionsdatensätze in ERP- und CRM-Systemen) als auch unstrukturierte Daten (Dokumente, E-Mails, PDFs, Bilder) umfassen. Unstrukturierte Daten machen derzeit den Großteil der Unternehmensdaten aus, doch weniger als 1 % davon liegt in einem Format vor, das für die direkte Nutzung durch KI geeignet ist. Dieses strukturelle Ungleichgewicht ist laut der IBM IBV 2025 CEO Study einer der Hauptgründe dafür, dass nur 16 % der KI-Initiativen Unternehmensmaßstäbe erreicht haben.
KI-fähige Daten werden daher nicht durch ein einzelnes Merkmal definiert, sondern durch das gleichzeitige Vorliegen von vier grundlegenden Bedingungen: Sie müssen einheitlich und zugänglich, geregelt, sicher und durch die richtigen Tools und Kompetenzen unterstützt sein. Diese Bedingungen bestimmen gemeinsam, ob Daten als Input für KI-Systeme vertrauenswürdig sind und ob die Organisation wiederum den Outputs dieser Systeme vertrauen kann.

Wie mache ich meine Daten KI-fähig?
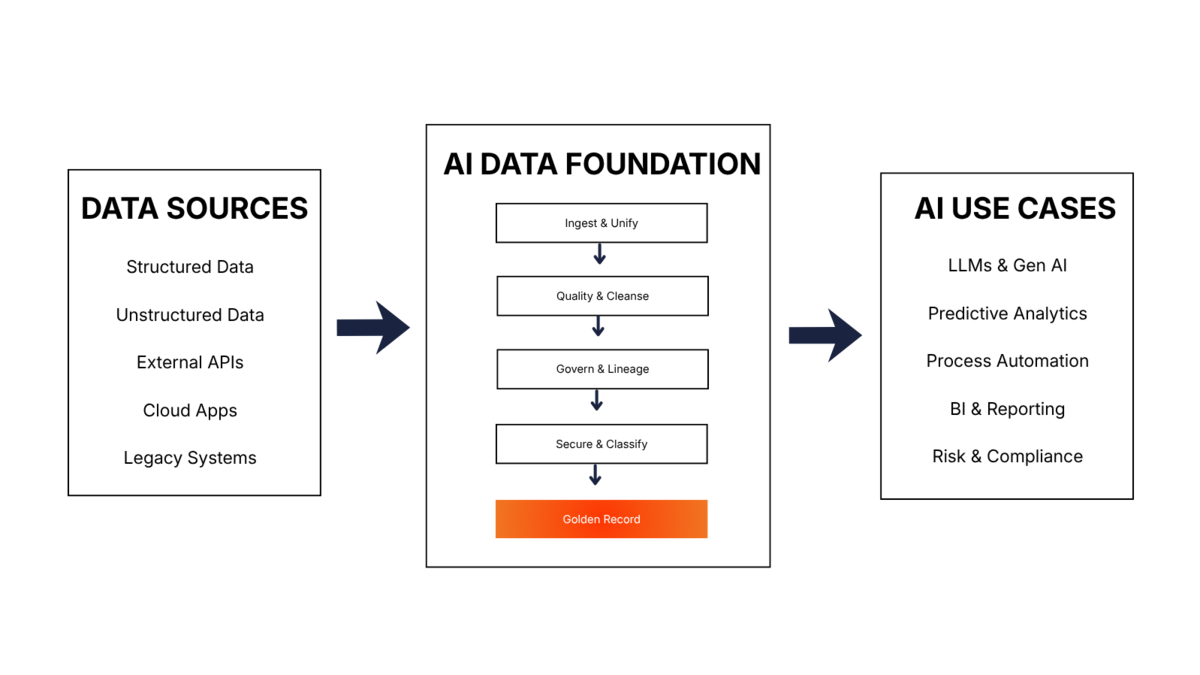
Die Aufbereitung von Daten für Systeme wie LLMs erfordert einen strengen Prozess, um sicherzustellen, dass die Informationen nicht nur verfügbar, sondern auch kontextreich sind. Dies wird durch eine „Data Readiness Pipeline“ erreicht:
Herausforderungen
Viele KI-Projekte scheitern nicht am Modell, sondern an den Daten. Häufig wird erst spät sichtbar, dass relevante Informationen über zahlreiche Systeme verteilt sind: Kundendaten in Salesforce, Transaktionen in SAP, Produktspezifikationen in Tabellen, Support-Tickets in externen Tools und dazu ein Data Lake, dessen Inhalt kaum noch jemand überblickt. Unterschiedliche Zuständigkeiten, Aktualisierungszyklen und Zugriffsmodelle erschweren einen einheitlichen Zugriff – obwohl genau dieser für KI entscheidend ist.
Hinzu kommt, dass Datenqualität im KI-Kontext anders verstanden werden muss als in der klassischen Datenverarbeitung. Fehler, Dubletten und fehlende Werte bleiben problematisch. Gleichzeitig kann ein zu starkes „Bereinigen“ von Daten schaden: Ausreißer, Randfälle und ungewöhnliche Muster sind oft genau die Signale, die Klassifikations- oder Anomalieerkennungsmodelle benötigen. Datenqualität ist deshalb kein allgemeiner Standard, sondern immer vom jeweiligen Anwendungsfall abhängig.
Ein weiteres zentrales Problem ist die Qualifikations- und Infrastrukturlücke. Viele Datenteams müssen parallel bestehende Systeme betreiben und zugleich neue KI-Anforderungen erfüllen. Oft fehlen Erfahrung und Prozesse für Embedding-Pipelines, RAG-Architekturen, Vektordatenbanken oder Annotationen. Besonders anspruchsvoll ist der Umgang mit unstrukturierten Daten wie Dokumenten, PDFs, E-Mails, Bildern oder Chat-Protokollen. Gerade sie enthalten häufig den wertvollsten operativen Kontext, benötigen aber eigene Vorverarbeitungs-, Vektorisierungs- und Metadaten-Workflows.
Mit wachsender KI-Nutzung steigt zudem der regulatorische und sicherheitsrelevante Druck. Wer mit sensiblen Daten arbeitet, vergrößert zugleich die Angriffsfläche – etwa durch Datenlecks, Prompt-Injection oder unsichere Abruf-Pipelines. Ohne belastbare Data Governance entstehen daher nicht nur technische Schulden, sondern auch Compliance- und Reputationsrisiken. Gartner betont außerdem, dass Verzerrung, Repräsentativität und Fairness keine reine Modellfrage sind, sondern bereits auf Ebene der Datenquellen governance-seitig abgesichert werden müssen.
Nutzen
Wenn Unternehmen ihre Datenbasis für KI sauber aufbauen, entsteht kein einmaliger Nutzen, sondern ein nachhaltiger Hebel. Ein konsolidierter, sauber klassifizierter und governter Datenbestand kann nicht nur einen einzelnen Anwendungsfall tragen, sondern mehrere zugleich: etwa Suche, Prognosen, Empfehlungen oder Optimierung. Der zentrale Vorteil liegt darin, dass Datenarbeit nicht für jedes neue KI-Projekt neu begonnen werden muss. Mit jeder weiteren Initiative sinkt der Aufwand, weil die Grundlage bereits vorhanden ist.
Direkt sichtbar wird das in der Modellleistung. Einheitliche, verlässliche, anwendungsgeeignete und gut annotierte Daten verbessern die Qualität von KI-Systemen spürbar: Sie reduzieren Halluzinationen bei LLMs, erhöhen die Genauigkeit von Klassifikations- und Prognosemodellen und verkürzen Trainings- und Entwicklungszyklen. Teams verbringen dann deutlich weniger Zeit mit Bereinigung, Abgleich und manueller Nacharbeit und können sich stärker auf Entwicklung, Evaluation und Iteration konzentrieren.
Ein zweiter zentraler Vorteil liegt in Governance und Compliance. Wenn Qualitätsregeln, Lineage, Versionierung und Zugriffsrichtlinien von Anfang an mitgedacht werden, lassen sich KI-Systeme besser prüfen, erklären und regulatorisch absichern. Das ist besonders wichtig in stark regulierten Bereichen wie Finanzdienstleistungen, Gesundheit oder Pharma. Zugleich schaffen versionierte und überwachbare Datenbestände die Voraussetzung dafür, Modellverhalten, Drift und Datenverschiebungen auch im laufenden Betrieb nachvollziehen zu können.
Strategisch wird daraus ein skalierbarer Unternehmenswert. Gut organisierte Daten werden zu einer gemeinsamen Infrastrukturschicht, auf die mehrere KI-Anwendungen parallel zugreifen können, ohne doppelte Arbeit zu erzeugen. So wird Datenqualität vom Projektaufwand zur dauerhaften Fähigkeit. KI-Bereitschaft ist dann kein einmal erreichter Zustand, sondern eine kontinuierlich gepflegte operative Kompetenz.
Best Practices für Unternehmen
Die folgende Tabelle fasst die wesentlichen Merkmale zusammen, die KI-fähige Daten auszeichnen, sowie deren jeweilige Bedeutung im Zusammenhang mit dem Einsatz von KI-Systemen.
Die ersten drei Spalten geben allgemein anerkannte Attribute der Datenbereitschaft von IBM und Gartner wieder. Die spezifischen Anmerkungen in der letzten Spalte spiegeln die anwendungsfallabhängige Perspektive wider, die die KI-Bereitschaft von der allgemeinen Datenqualität unterscheidet.
| Merkmal | Beschreibung | Bedeutung für KI-Anwendungen |
|---|---|---|
| Vereinheitlicht & zugänglich | Daten aus unterschiedlichen Quellen werden in einer einzigen, abfragbaren Sicht über Datenbanken, Data Lakes und Cloud-Apps hinweg konsolidiert. | KI-Modelle können nicht mit Daten arbeiten, die sie nicht erreichen können. Fragmentierter Zugriff begrenzt Kontext, Abdeckung und domänenübergreifendes Schlussfolgern. |
| Use-Case Fit | Daten werden anhand der spezifischen Anforderungen jedes KI-Anwendungsfalls bewertet und validiert, einschließlich Volumen, Diversität und Technik. | Es gibt keine generische KI-Readiness. Ein Datensatz, der für ein Modell geeignet ist, kann für ein anderes ungeeignet oder sogar aktiv schädlich sein. |
| Präzise & vollständig | Datensätze sind frei von Fehlern, Duplikaten und fehlenden Feldern. Datenqualitäts-Scores werden aktiv gemessen und durchgesetzt. | Ungenaue oder unvollständige Trainingsdaten führen direkt zu unzuverlässigen, verzerrten oder irreführenden Modellausgaben. |
| Repräsentativ & divers | Daten decken die gesamte Bandbreite an Mustern, Edge Cases und Ausreißern ab, die für die KI-Aufgabe relevant sind, einschließlich jener, die durch traditionelle Qualitätsstandards herausgefiltert würden. | Das Bereinigen von Ausreißern kann Varianz entfernen, die Klassifikations- und Anomalieerkennungsmodelle benötigen. Diversität der Quellen verhindert Trainingsbias. |
| Governed | Klare Verantwortlichkeiten, Qualitätsregeln, Lineage-Tracking, Versionierung und Freigabe-Workflows sind über den gesamten Datenlebenszyklus hinweg definiert und durchgesetzt. | Ermöglicht die Auditierbarkeit, regulatorische Compliance (DSGVO, EU AI Act, BCBS 239) und die langfristige Nachhaltigkeit der Datenqualität. |
| Sicher | Rollenbasierte Zugriffskontrollen, Datenmaskierung und Privacy Enforcement sind in die Datenebene eingebettet und werden nicht erst nachträglich aufgesetzt. | Schützt sensible Daten vor Offenlegung durch KI-Abfragen oder Modellausgaben; erforderlich für Compliance in regulierten Branchen. |
| Aktuell & versioniert | Daten werden regelmäßig aktualisiert und mit Zeitstempeln versehen. Veraltete Datensätze werden gekennzeichnet. Die Versionshistorie wird gepflegt, um Model Drift zu erkennen und zu steuern. | KI-Systeme, die mit veralteten Daten arbeiten, treffen Entscheidungen, die die operative Realität nicht mehr widerspiegeln. Versionierung ermöglicht Regressionstests und Drift Detection. |
| Gelabelt & annotiert | Daten sind getaggt, semantisch annotiert und für die Verarbeitung durch KI formatiert, einschließlich unstrukturierter Inhalte wie Dokumente und Bilder. | Die Qualität des Labelings, insbesondere bei Bild-, Video- und Dokumentdaten, ist eine kritische und oft unterschätzte Voraussetzung für Supervised Learning und LLM Grounding. |
| Unterstützt | Tooling, Pipelines und qualifiziertes Personal sind vorhanden, um Datenqualität zu überwachen, zu orchestrieren, zu validieren und kontinuierlich zu verbessern. | KI-Readiness verschlechtert sich ohne fortlaufende menschliche Aufsicht, technische Unterstützung, Observability-Metriken und automatisiertes Qualitätsmonitoring. |
Fazit
KI-fähige Daten sind kein einmaliges Ergebnis. Sie sind eine kontinuierliche operative Fähigkeit. Die Unternehmen, die mit KI am ehesten Erfolg haben werden, sind diejenigen, die Datenqualität, Governance, Sicherheit und Zugänglichkeit nicht als Checklistenpunkte vor Projektbeginn betrachten, sondern als technische Disziplinen, die von Grund auf in ihre Dateninfrastruktur eingebettet sind. Wie Gartner deutlich macht, bedeutet dies auch, sich von der Vorstellung eines einzigen universellen Datenstandards zu lösen: Die Bereitschaft muss im Hinblick auf jeden spezifischen KI-Anwendungsfall und die dafür erforderlichen Vertrauensstufen bewertet, validiert und gesteuert werden.
Der Weg nach vorn ist strukturiert, aber nicht einfach: die aktuelle Bereitschaft ehrlich bewerten, frühzeitig die Zustimmung der Führungskräfte sichern, die Lücke zwischen traditionellem Datenmanagement und KI-spezifischen Anforderungen schließen und die Governance sowie die Werkzeuge aufbauen, um die Qualität bei der Skalierung der Modelle aufrechtzuerhalten. Unternehmen, die dies erreichen, werden nicht nur bessere KI-Modelle betreiben. Sie werden die Dateninfrastruktur aufbauen, die jede zukünftige KI-Initiative schneller, kostengünstiger und zuverlässiger macht als die vorherige.
Diesen Beitrag teilen: