Reinforcement Learning: Algorithmen im Gehirn
- Veröffentlicht:
- Autor: Dr. Luca Bruder, Dr. Philipp Schwartenbeck
- Kategorie: Deep Dive
Inhaltsverzeichnis

In der Regel sind unsere Blogartikel auf Business Use Cases und die Analyse von Geschäftsdaten ausgerichtet. Doch in diesem Artikel möchten wir einen anderen Ansatz wählen. Wir diskutieren, wie uns Methoden, die wir zur Lösung von Geschäftsproblemen anwenden, Einblicke in das Gebiet der Neurowissenschaften und die Funktion biologischer Gehirne im letzten Jahrhundert geliefert haben. Die Forschungsfelder der künstlichen und biologischen Intelligenz haben sich parallel entwickelt und sich gegenseitig stark beeinflusst. Hier werden wir uns auf das Reinforcement Learning (RL) konzentrieren – ein großartiges Beispiel dafür, wie die Erforschung der Funktionsweise biologischer Systeme einerseits und Forschungen in Statistik und Informatik andererseits sich gegenseitig befruchten können, um neuartige Erkenntnisse zu entwickeln.
RL ist ursprünglich eine Theorie über das Lernen, die in der Psychologie schon seit langem bekannt ist. Die zugrundeliegende Idee: Handlungen, die durch Belohnungen verstärkt werden, werden wahrscheinlich wiederholt, während Handlungen, die zu keiner Belohnung oder sogar Bestrafung führen, immer seltener werden (Abbildung 1). Sutton und Barto formalisierten die mathematische Grundlage dieses „Reinforcement Learnings, („Verstärkungslernens“) und begründeten damit einen neuen Forschungszweig der Künstlichen Intelligenz (Sutton, R. S., & Barto, A. G. (1999). Reinforcement learning: An introduction. MIT press), der die Grundlage für all die ausgeklügelten Algorithmen bildet, die heute die Schach- und Go-Weltmeister schlagen. Neurowissenschaftler wiederum nutzen diese mathematischen Formulierungen, um verschiedene Hirnregionen zu untersuchen und jene Teile unseres Gehirns zu identifizieren, die für das Lernen auf Basis von Belohnungen verantwortlich sind. Jahrzehntelange Forschung deutet darauf hin, dass RL, wie es von Sutton, Barto und Kollegen formalisiert wurde, einer der zentralen Mechanismen sein könnte, mit denen Menschen und andere Tiere lernen.

Eine kompakte Einleitung in die Definition und Begrifflichkeiten hinter Reinforcement Learning erhalten Sie in unserem Grundlagenartikel zur Methodik:
Reinforcement Learning: kompakt erklärt
Reinforcement Learning in Algorithmen und biologischen Gehirnen
Das Grundkonzept des Reinforcement Learnings besteht darin, das Verhalten durch Lernen aus „Trail-and-Error“, also Versuch und Irrtum, zu verbessern. Hierbei lernen die Agenten einen so genannten „Wert“ V(t) eines Zustands (oder eines Zustands-Aktions-Paars) zu einem bestimmten Zeitpunkt t, der dem Agenten sagt, wie viel Belohnung er für verschiedene Optionen erwarten kann (z. B. wie sehr würde es mir gefallen, wenn ich Schokoladen- oder Vanilleeis bestellen würde). Der zentrale Trick besteht darin, diesen Wert iterativ zu lernen (Ich habe gerade Schokoladeneis bestellt – wie sehr hat es mir gefallen?). Um dies zu verstehen, können wir uns die mathematische Formulierung einer der zentralsten Gleichungen in RL ansehen, nämlich das iterative Lernen der „Wertfunktion“ V(t):
V(t+1) = V(t) + α ⋅ (Reward-V(t))
Diese Gleichung geht davon aus, dass der Wert des nächsten Zeitschritts V(t+1), der formal die Erwartung künftiger Belohnungen widerspiegelt (wie viel Vergnügen erwarte ich, wenn ich mich jetzt für Schokoladeneis entscheide?), durch die Aktualisierung der aktuellen Werterwartung V(t) um die Differenz zwischen der erhaltenen Belohnung und der aktuellen Erwartung, wie die Belohnung aussehen sollte (Reward-V(t)), gebildet wird. Diese Differenz wird oft als Reward Prediction Error (RPE) bezeichnet. Die Stärke der auf dem RPE basierenden Aktualisierung wird durch eine so genannte Lernrate (????, alpha) bestimmt. ???? bestimmt im Wesentlichen, wie stark die erhaltene Belohnung die Erwartung an zukünftige Belohnungen verändert. Eine ausführlichere Beschreibung findet ihr in unserem Blog-Artikel über grundlegende RL-Terminologie.
Um die Verbindung zwischen RL und dem Gehirn herzustellen, müssen wir einen kurzen Abstecher in die Anatomie machen. Das menschliche Gehirn ist in den Neokortex und die subkortikalen Areale unterteilt (Abbildung 2). Der Neokortex ist ein großer, gefalteter Bereich an der Außenseite des Gehirns und ist die Struktur, die man sich oft vorstellt, wenn man über das Gehirn als Ganzes spricht. Er besteht aus mehreren verschiedenen Bereichen, die nach ihrer Position im Verhältnis zum menschlichen Schädel benannt sind. Von besonderer Bedeutung für uns ist der Frontallappen, der den präfrontalen Kortex enthält, der den vorderen Teil des Gehirns bildet. Neben vielen anderen wichtigen Funktionen, wie Sprache und exekutive Kontrolle, spielt er vermutlich eine entscheidende Rolle bei der Darstellung wichtiger RL-Variablen, wie dem Wert, den wir Gegenständen und anderen Belohnungen beimessen. Subkortikale Areale hingegen befinden sich tief im Gehirn. Der wichtigste Bereich, den wir hier hervorheben möchten, ist eine Ansammlung von neuronalen Strukturen, die sogenannten Basalganglien. Diese Strukturen spielen eine wichtige Rolle bei der Bewegungskontrolle, der Entscheidungsfindung und dem Lernen von Belohnungen. Ein weiteres wichtiges Konzept ist der Begriff der Neurotransmitter.
Neurotransmitter steuern die Kommunikation zwischen verschiedenen Teilen des Gehirns (genauer gesagt: die Kommunikation zwischen seinen Untereinheiten, den Synapsen zwischen einzelnen Neuronen). Es gibt verschiedene Arten von Neurotransmittern, von denen angenommen wird, dass sie unterschiedliche neuronale Prozesse steuern. Der wichtigste Neurotransmitter, der das Zusammenspiel der Regionen in den Basalganglien und im präfrontalen Kortex steuert, ist Dopamin, das auch als wichtigster Neurotransmitter für das RL im Gehirn gilt.

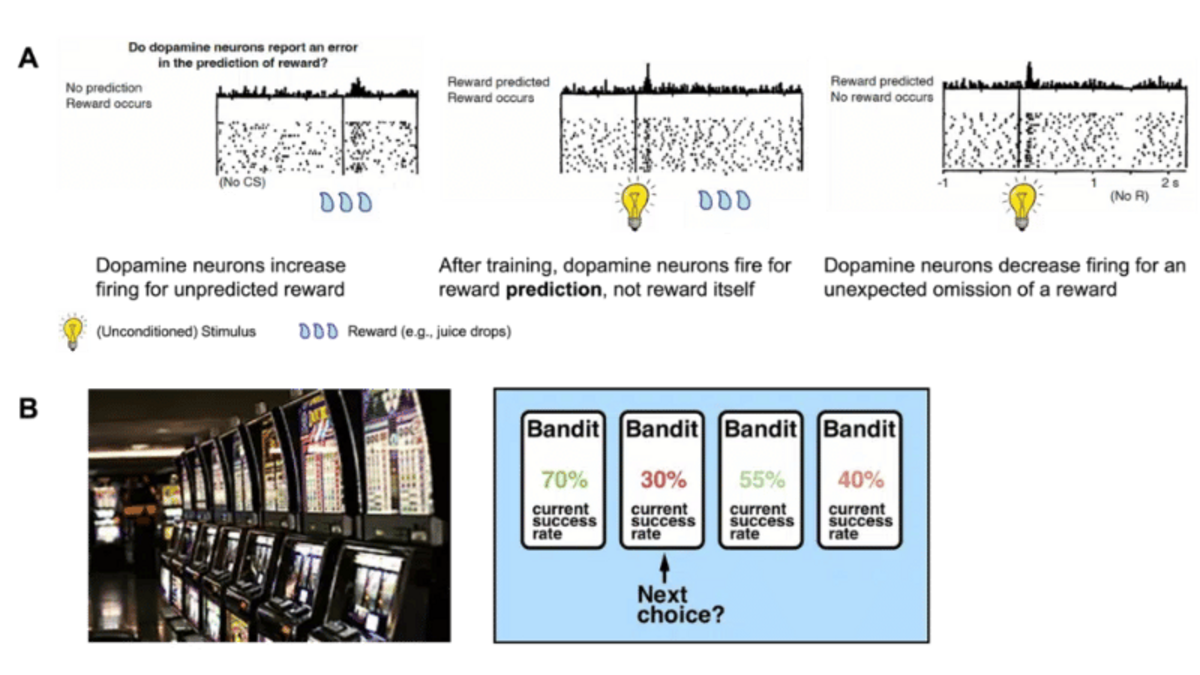
Im Gehirn hat Dopamin viele Aufgaben, aber hier wollen wir uns auf seine Rolle beim Belohnungslernen konzentrieren (Abbildung 3A). Wie funktioniert das? Entgegen der öffentlichen Wahrnehmung ist die Dopaminausschüttung kein Lust- oder Belohnungssignal an sich, sondern eine Möglichkeit, die Differenz zwischen erwarteter und tatsächlicher Belohnung zu kodieren, d. h. unseren oben definierten Belohnungsvorhersagefehler (Reward Prediction Error). Anders ausgedrückt: Das Gehirn schüttet als Reaktion auf eine unerwartete/überraschende Belohnung eine große Menge Dopamin aus, und die Dopaminausschüttung wird gedämpft, wenn die erwartete Belohnung nicht eintritt. Eine vollständig erwartete Belohnung hingegen verändert das dopaminerge Feuermuster nicht. Die Entdeckung des engen Zusammenhangs zwischen dopaminergen Feuermustern und RPEs ist eine der bedeutendsten neurowissenschaftlichen Erkenntnisse der letzten Jahrzehnte (Schultz, Dayan, & Montague, Science 1997).
Eine vertiefende technische Einführung zur Reinforcement Learning, die Ihnen ein grundlegendes Verständnis von Reinforcement Learning (RL) anhand eines praktischen Beispiels gibt, erhalten Sie in unserem Blogbeitrag:
Reinforcement Learning – Framework und Anwendungsbeispiel
Auswirkungen von RL-Algorithmen in den Neurowissenschaften und darüber hinaus
Seit seiner Entdeckung wurde viel Arbeit in die Entwicklung von Experimenten gesteckt, um die Dynamik des Reinforcement Learnings bei Menschen und anderen Tieren aufzudecken. RL-Experimente in der Neurowissenschaft unterscheiden sich in der Regel ein wenig von dem, was Datenwissenschaftler mit RL-Modellen in Business Use Cases tun. In Data Science erstellen wir eine Simulation („Digitaler Zwilling“), in der ein Agent lernt, wie er eine bestimmte Aufgabe optimieren kann, z. B. die Steuerung von Verkehrsampeln oder die Minimierung von Energiekosten. Die Agenten lernen, optimale Maßnahmen zu ergreifen, um die Belohnung zu maximieren. Auf diese Weise hoffen wir, einen Agenten zu kreieren, der die Aufgabe selbständig ausführen und lösen kann, indem er sein Verhalten so optimiert, dass er die bestmöglichen Belohnungen erhält. Im Gegensatz dazu bitten Forscher in den Neurowissenschaften (biologische) Teilnehmer, bestimmte Lernaufgaben zu lösen, und analysieren, wie sich verschiedene Manipulationen auf ihr (Verstärkungs-)Lernverhalten auswirken. Dazu werden Agenten für das Reinforcement Learning so trainiert, dass sie das Verhalten nachahmen, das bei den realen Teilnehmern des Experiments beobachtet wurde. Auf der Grundlage dieser trainierten Agenten können Forscher das Verhalten in mathematischen Begriffen beschreiben, indem sie die Handlungen der Teilnehmer mit den Handlungen der trainierten RL-Agenten vergleichen.
Ein sehr einfaches Beispiel für ein solches Experiment ist die Banditenaufgabe (Abbildung 3B). Bei dieser Aufgabe müssen die Teilnehmer ihre Handlungen optimieren, indem sie den bestmöglichen Räuber auswählen. Jede Aktion hat eine bestimmte Wahrscheinlichkeit, eine bestimmte Belohnung zu erhalten. Die Wahrscheinlichkeiten werden den Teilnehmern nicht mitgeteilt, sondern müssen aus Erfahrung gelernt werden, indem die verschiedenen Optionen ausprobiert und die Ergebnisse beobachtet werden. Häufig ändert sich die Wahrscheinlichkeit, eine bestimmte Belohnung für jede Aktion (= Wahl einer bestimmten Option) zu erhalten, im Laufe des Experiments. Dies führt zu einer dynamischen Umgebung, in der die Teilnehmer den aktuellen Zustand jeder Aktion im Auge behalten müssen. Durch Verwendung der obigen RL-Formulierung und Optimierung des Parameters α für jeden Teilnehmer optimieren, können wir abschätzen, wie effizient die einzelnen Teilnehmer ihre Belohnungserwartung aktualisieren und wie dies ihr Verhalten beeinflusst.
Studien mit diesem und ähnlichen Designs haben eine Reihe von klinisch wichtigen Ergebnissen gezeigt. Diese Ergebnisse können dazu beitragen, die Diagnose zu verbessern und eine Brücke zu neuen Behandlungsmethoden für psychische Störungen zu schlagen, da die Mechanismen hinter klinisch abnormalem Verhalten ermittelt werden können. So wurde beispielsweise vermutet, dass klinische Erkrankungen wie Depressionen mit Unterschieden beim Lernen aus positivem und negativem Feedback zusammenhängen könnten (Chong Chen, … & Ichiro Kusumi, Neuroscience and Biobehavioral Reviews 2015; Reinen, …, & Schneier, European Neuropsychopharmacology 2021). Stellen Sie sich vor, Sie haben nicht nur eine Lernrate (α im obigen Beispiel), sondern zwei, eine für das Lernen aus positivem Feedback und eine für negatives Feedback. Was passiert, wenn sie nicht gleich sind, sondern Ihre „positive“ Lernrate niedriger ist als die „negative“? Dies führt dazu, dass Sie Ihr Wissen über die Welt viel stärker auf der Grundlage negativer Rückmeldungen aktualisieren, was zu einer negativ geprägten Darstellung Ihrer Umgebung führt. Ein zweites Beispiel bezieht sich auf die Darstellung von Werten selbst. Beim Reinforcement Learning ist es nicht nur wichtig, aus Erfahrungen zu lernen, sondern auch die Werte der Optionen selbst genau darzustellen (V(t) im obigen Beispiel).
Dies war ein weiterer wichtiger Schwerpunkt der Forschung zu individuellen Unterschieden und klinischen Symptomen. Diese individuelle Sensibilität für Wertunterschiede bestimmt, wie sehr Sie sich tatsächlich dafür interessieren, ob eine Option besser ist als die andere. Nehmen wir an, Sie haben gelernt, dass Sie Bananen sehr gerne mögen und Äpfel eher weniger. Wenn Ihnen diese Präferenzunterschiede sehr wichtig sind, werden Sie immer Bananen wählen und Äpfel ignorieren. Wenn Sie weniger empfindlich auf Ihre Vorlieben reagieren, werden Sie beide Früchte mehr oder weniger gleich oft wählen. Was sich wie ein künstliches Beispiel anhört, ist ein zentraler Aspekt der Art und Weise, wie künstliche und biologische Agenten sich in der Welt zurechtfinden: Wenn sie nicht sensibel genug für das sind, was sie in der Welt für gut oder schlecht halten, werden sie sich zu willkürlich verhalten, aber wenn sie zu sensibel für ihre Präferenzen sind, werden sie immer bei einer Option bleiben und nicht in der Lage sein, andere Alternativen zu erkunden oder Veränderungen in der Welt zu erkennen, wie z. B. eine plötzliche Verbesserung der Qualität von Äpfeln (siehe die Beschreibung der wechselnden Banditen oben).
Dieses Problem ist der Kern des so genannten Explorations-Ausbeutungs-Kompromisses (exploration-exploitation trade-off), der im Mittelpunkt des Reinforcement Learnings steht: Wie sehr sollten sich Agenten auf ihr Wissen verlassen, um die beste Option auszuwählen (exploit), und wie sehr sollten sie neue Optionen ausprobieren, um mehr über die sich verändernde Welt zu erfahren (explore). Es wird Sie nicht überraschen zu hören, dass sowohl das individuelle Lernen als auch das Lösen des Kompromisses zwischen Erkundung und Ausbeutung mit der dopaminergen Funktion in Verbindung gebracht werden (Chakroun, …, & Peters, 2020 eLife; Cremer, …, Schwabe, Neuropsychopharamcology 2022), die auch ein wichtiger Schwerpunkt der klinischen Neurowissenschaft ist (Foley, Psychiatry and Preclinical Psychiatric Studies 2019; Iglesias, …, & Stephan, WIREs Cognitive Science 2016).
Erfahren Sie, wie großen Sprachmodellen wie ChatGPT durch den Einsatz von Reinforcement Learning from Human Feedback (RLHF) verbessert werden.
Reinforcement Learning from Human Feedback im Bereich von großen Sprachmodellen
Aktuelle Verbindungen zwischen KI und Neurowissenschaften
Der bidirektionale Informationsfluss zwischen künstlicher Intelligenz und neurowissenschaftlicher Forschung ist weiterhin fruchtbar (Hassabis, …, & Botvinick, Neuron 2017; Botvinick, …, & Kurth-Nelson, Neuron 2020). So hat sich beispielsweise gezeigt, dass die Idee, Erfahrungen in einem Wiederholungspuffer zu speichern und „neu zu erleben“, um die RL-Trainingsdaten eines Agenten zu erhöhen, die Effizienz von Verstärkungslernalgorithmen in der KI erheblich verbessern kann (Schaul, …, & Silver, arXiv 2015; Sutton, Machine Learning Proceedings 1990). Jüngste Arbeiten haben außerdem gezeigt, dass diese Algorithmen verblüffende Ähnlichkeit mit der neuronalen Wiederholung aufweisen, die im Hippocampus, einer zentralen Gehirnregion für Gedächtnisbildung und Navigation im biologischen Gehirn, zu finden ist (Roscow, …, Lepora, Trends in Neurosciences 2021; Ambrose, … Foster, Neuron 2016).
Viele Forschungsarbeiten befassen sich auch mit der genauen Art des Lernsignals, das in dopaminergen Neuronen gefunden wird. Die Schlüsselsignatur, eine allmähliche Verschiebung von Lernsignalen, die sich in der Zeit rückwärts bewegen, wurde in jüngsten Arbeiten sowohl unterstützt (Amo, …, Uchida, Nature Neuroscience 2022) als auch infrage gestellt (Jefong, …, Namboodiri, Science 2022; “A decades-old model of animal (and human) learning is under fire”, Economist 2023). Solche biologischen Erkenntnisse sind entscheidend für die Entwicklung ressourceneffizienter Algorithmen für das Verstärkungslernen in der Künstlichen Intelligenz.
Eine weitere spannende Arbeit deutet darauf hin, dass dopaminerge Lernsignale möglicherweise nicht die Aktualisierung einzelner Zahlen widerspiegeln, sondern das Lernen der gesamten Verteilung möglicher Belohnungen und ihrer jeweiligen Wahrscheinlichkeiten (Bakermans, Muller, Behrens, Current Biology 2020, Dabney, Kurth-Nelson, …, Botvinick, Nature 2020). Dies hat sowohl wichtige biologische als auch algorithmische Implikationen. Algorithmisch bedeutet dies, dass das Reinforcement Learning nicht nur den Erwartungswert einer Belohnung annähert, sondern ihre gesamte Verteilung, was eine wesentlich reichhaltigere Repräsentation der Umwelt bietet und damit das Lernen und die Handlungskontrolle erheblich beschleunigt. Biologisch gesehen muss ein Tier, das kurz vor dem Verhungern steht, wissen, wo es genügend Nahrung findet, um zu überleben, auch wenn diese Option weniger wahrscheinlich ist als eine sicherere Alternative, die nicht genügend Nahrung bietet. Diese und ähnliche Arbeiten geben wichtige Einblicke in das Wesen ressourceneffizienter und dennoch leistungsfähiger Algorithmen des Verstärkungslernens und damit auch in das Wesen der künstlichen und biologischen Intelligenz selbst.
Über den Einsatz von Reinforcement Learning in der Industrie und anderen relevanten Branchen lesen Sie in unserem Fachbeitrag:
Reinforcement Learning – Use Cases für Unternehmen
Fazit
Zusammenfassend lässt sich sagen, dass der Wissensfluss zwischen den Neurowissenschaften und den theoretischen RL-Ansätzen im letzten Jahrhundert wesentliche Einblicke sowohl in die Prinzipien der biologischen als auch der künstlichen Intelligenz geliefert hat. Reinforcement Learning ist ein Schlüsselaspekt moderner Anwendungen der künstlichen Intelligenz, die von der Lösung anspruchsvoller Steuerungsprobleme bis hin zur Erfolgsgeschichte großer Sprachmodelle reichen, aber stark in der biologischen Wissenschaft verwurzelt sind. Die Entwicklung immer leistungsfähigerer Algorithmen führt zu neuen Erkenntnissen darüber, wie unser Gehirn die Welt versteht, und die Erkenntnisse über die biologische Intelligenz führen zu effizienteren und einflussreicheren Algorithmen für das Reinforcement Learning im geschäftlichen Kontext.
Diesen Beitrag teilen: