
Introduction
With ChatGPT, Large Language Models (LLMs) have jumped at the center stage of public attention. These models are pre-trained on massive amounts of text data from the internet. However, at the very same time, also new foundational computer vision models evolve rapidly: those are pre-trained on massive amounts of images from the internet. Many such models are indeed multi-modal: They were trained to relate images with text.
In this post, we shed some light on how such foundational models compare with traditional models when classifying images: We fine-tune both the state-of-the-art foundational CLIP model and the popular supervised benchmark model ResNet50. In particular, we fine-tune on domain-specific data sets, thus addressing potential business applications. We find that both perform well, already under pragmatic choice of hyper parameters, with a slight advantage of one over the other depending on the domain.
The CLIP model, short for Contrastive Image-Language Pre-Training, is one of the most prominent multimodal models. It was trained on images and their respective text captions. It was released by OpenAI in 2021. Contrastive learning is a machine learning technique that trains a model to differentiate between similar and dissimilar examples by optimizing a contrastive loss function. While this training strategy has been around for a while, the massive amount of pre-training data has made all the difference for the performance of such models: CLIP was trained on 400 million image-text pairs scraped from the internet. On AWS, the training would have cost around 1 million US-Dollars.
How does contrastive learning work for CLIP? In essence, the model consists of a text encoder and an image encoder. Each vectorizes the input image resp. the corresponding text caption individually, in a common vector space. The training aims to adjust weights of the two encoders so that similar pairs (e.g. text descriptions containing the word „dog“ and images of dogs) are close to each other in vector space w.r.t. the cosine similarity, and dissimilar pairs (i.e. text descriptions containing the word „dog“ and images of submarines) are far from each other.
Once trained, the CLIP model can be used for various down-stream tasks, basically like a look-up table. Given a text description, the model can find the image that best fits the description (image search) or can contribute in generating a correspnding image (CLIP is part of the image generation tool DALL-E.
In the other direction, CLIP is a powerful image classifier. Given an image and a prompt with different possible text descriptions to choose from, the model can assign similarity scores to each of them. The image is then easily classified using the text description with the highest similarity score. In other words, the model simply „looks up“ the distances of the vectorized image to different vectorized text captions to find the best match.
CLIP is especially popular because of its ability of „zero-shot“ image classification. This means that the model can directly classify images of all possible kinds, for instance images of apples, cats, cars, persons, landscapes, cities, and so on, without any specific supervised training to recognize these classes. Essentially all kinds of images that can frequently be found on the internet are known to the model.
At [at], our prime concern is to find the best solution for our customer’s use case at hand. For image classification use cases, there are many well-established models to choose from. Many are based on convolutional neural network architectures that are known for high performance once fine-tuned on a specific dataset in a supervised fashion. One popular example is the ResNet50 model.
CLIP can be fine-tuned to custom datasets as well. It already carries a broad understanding of image contents, as it was trained on vast contents from the internet. Does this general power allow out-performing traditional well-established classifiers, when dealing with very specific images such as patterns, biological specimen, satellite imagery, etc.? Or is ResNet50, which was pre-trained on a curated set of broadly chosen classes like dogs, cars, sunsets, etc. (ImageNet with 1000 classes), the more promising choice?
In this blog post we compare the performance of a ResNet50 model with CLIP’s performance, after fine-tuning both on a selection of custom datasets. We are also interested in analyzing the zero-shot capability of the CLIP model and how fine-tuning improves this zero-shot performance.
Fine-tuning image classifiers: ResNet50 vs CLIP
Inhaltsverzeichnis
The setup
For both fine-tunings, we stick to quite basic setups, that is, we do not exhaustively tune hyper parameters such as epochs or learning rate. Hence, we receive a very basic picture of whether the performance is comparable.
CLIP
CLIP comes on different neural network architectures, the most common of which is ViT-B/32, a vision transformer (ViT) of base size (B) with an image patch side length of 32. We utilize WiSE-FT’s implementation, and tune for short 10 epochs with a small learning rate of 3e-5. The batch size is 512 on a setup of 4 GPUs with ~30GB total memory. (Where performance was terrible, we changed parameters to show that CLIP fine-tuning indeed can create a basic understanding. That was necessary for two datasets, see below.)
The CLIP model which we fine-tune is not trained on a given, restricted set of image classes. Instead, it is trained on pairs of images and their respective description scraped from the net. Such descriptions often take the form of „a photo of …“, „an image of …“. When fine-tuning CLIP, one provides a training image plus a set of possible descriptions made from the classes: a photo of CLASS_A, a photo of CLASS_B, a photo of CLASS_C, etc.
# taken from WiSE-FT's source code
# this one is specific to the IWildCam dataset
iwildcam_template = [
lambda c: f"a photo of {c}.",
lambda c: f"{c} in the wild.",
]ResNet50
The pre-trained ResNet50 from PyTorch predicts 1000 classes from ImageNet. To fine-tune on a custom set of classes, the classification head must be replaced with one of a matching number of classes.
# ...
weights = ResNet50_Weights.IMAGENET1K_V2
resnet = resnet50(weights=weights)
# ...
# fc is the fully-connected softmax output layer
resnet.fc = nn.Linear(in_features=2048, out_features=len(dataset.classnames))
nn.init.xavier_uniform_(resnet.fc.weight)
# ...We tune for 20 epochs, where the learning rate for the classification head is 10 times the learning rate of the rest of the net: 0.01 resp. 0.001. Batch size was 256 (on a setup with less GPU memory than for CLIP). We pragmatically used the image preprocessing function from the ResNet50’s pre-training, which resizes and crops a center part of an image. This is perfectly fine for datasets of e.g. patterns, but not ideal for e.g. planes, since nose and tail are cropped away. Our experiments yield good performance already under such sub-optimal conditions, i.e. one can expect further improvement when choosing dataset-tailored implementations.
Results
Datasets
We pragmatically choose datasets that are available as PyTorch loaders, and that we can expect to not have been part of the pre-trainings of both base models. The chosen datasets were used to evaluate the pre-trained CLIP and hence should not have been part of its training (see Table 9 in the appendix of the CLIP paper).
The datasets are:
| Dataset | No. of classes | Total no. of images (train+test) |
|---|---|---|
| CIFAR10 | 10 | 60.000 |
| CIFAR100 | 100 | 60.000 |
| DescribableTextures | 47 | 5.640 |
| FMOW* | 62 | 523.847 |
| FgvcAircraft | 102 | 10.200 |
| Flowers102 | 102 | 8.189 |
| Food101 | 101 | 101.000 |
| IWildCam | 182 | 217.640 |
| Stl10 | 10 | 13.000 |
*FMOW: Functional Map of the World
Here are brief impressions of some of these datasets (titles link to sources):




Performance numbers
In the following table, validation accuracy after select numbers of epochs is given for the various combinatios of dataset_model.
Typically, CLIP takes the lead even after half the number of epochs. On IWildCam, ResNet50 performs significantly better than CLIP. For FgvcAircraft and Flowers102 no reliable performance numbers were produced, see below for details.
| CIFAR10_ResNet50 | CIFAR10_CLIP | CIFAR100_ResNet50 | CIFAR100_CLIP | DescribableTextures_ResNet50 | DescribableTextures_CLIP | FgvcAircraft_ResNet50 | FgvcAircraft_CLIP | Flowers102_ResNet50 | Flowers102_CLIP | FMOW_ResNet50 | FMOW_CLIP | Food101_ResNet50 | Food101_CLIP | IWildCam_ResNet50 | IWildCam_CLIP | Stl10_ResNet50 | Stl10_CLIP | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| epoch | ||||||||||||||||||
| 1 | 0.8657 | 0.9689 | 0.6680 | 0.8344 | 0.3718 | 0.4340 | 0.1203 | 0.2112 | 0.3700 | 0.1244 | 0.4644 | 0.4684 | 0.6714 | 0.8672 | 0.8306 | 0.7729 | 0.7256 | 0.9791 |
| 5 | 0.9338 | 0.9639 | 0.7220 | 0.8389 | 0.6117 | 0.5101 | 0.5179 | 0.3150 | 0.7653 | 0.3566 | 0.4926 | 0.5389 | 0.7869 | 0.8564 | 0.9741 | 0.8441 | 0.9260 | 0.9840 |
| 10 | 0.9501 | 0.9792 | 0.8204 | 0.8910 | 0.6181 | 0.6170 | 0.6199 | 0.3162 | 0.8374 | 0.1164 | 0.5234 | 0.5661 | 0.8149 | 0.8863 | 0.9894 | 0.8976 | 0.9534 | 0.9860 |
| 15 | 0.9572 | nan | 0.8250 | nan | 0.6431 | nan | 0.6466 | 0.2973 | 0.8608 | nan | 0.5609 | nan | 0.8427 | nan | 0.9952 | nan | 0.9584 | nan |
| 20 | 0.9570 | nan | 0.8265 | nan | 0.6431 | nan | 0.6496 | 0.4152 | 0.8663 | nan | 0.5382 | nan | 0.8474 | nan | 0.9959 | nan | 0.9585 | nan |
Further siginificant improvements in performance need more tuning of hyper parameters: Except for the FgvcAircraft and Flowers102 dataset, training progress has almost flattened out, see the following plots. The 0-th iteration in the plot for CLIP is the performance of the zero-shot model, i.e. the un-fine-tuned model as it comes from OpenAI.
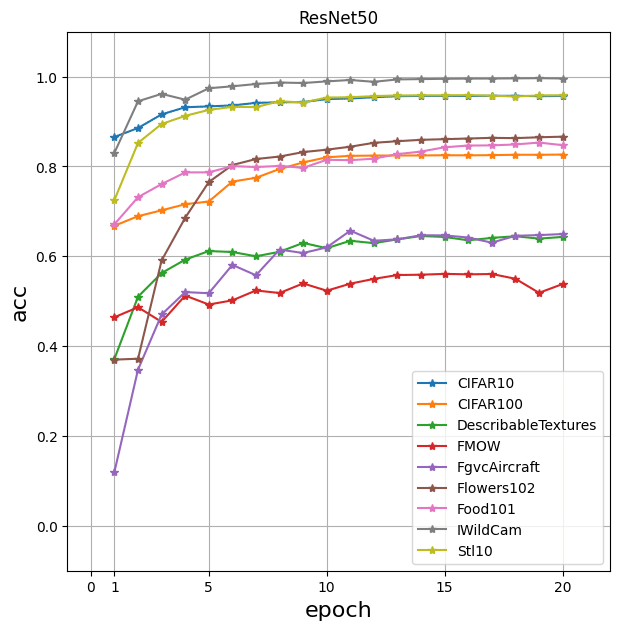
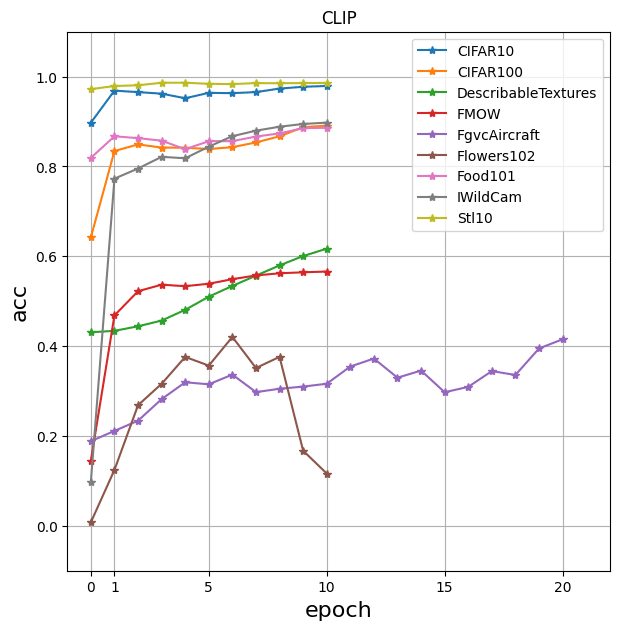
For FgvcAircraft and Flowers102, tuning CLIP with the same hyper parameters as for the rest (see section above for values) yields accuracy only ~30% resp. below 5%. Therefore we tried more hyper parameters to produce the general insight that CLIP is able to learn the concepts and achieve a non-trivial accuracy, but we did not (auto-)tune them further. For FgvcAircraft, we trained with a smaller batch size of 128 for more epochs, while the learning rate is unchanged at 3e-5. For Flowers102, the batch size is also 128 and the learning rate is larger, namely 3e-3.
The classification tasks that CLIP handles worst, namely for FgvcAircraft and Flowers102, share the property of being very fine-grained and low-variance (e.g. telling apart various very similar models of planes). That property was also observed by the authors of the original paper.
Conclusion
CLIP’s very general and broad understanding of image contents helps it classify domain-specific datasets well with few epochs of fine-tuning, even slightly better than a longer fine-tuned ResNet50.
When going for the best tradeoff between resource usage and prediction performance, ResNet50 should be strongly considered (it is roughly 1/4 the size of a ViT-B/32).
For a good understanding of ResNet50’s and CLIP’s performance in your custom use-case, the fine-tuning of both will have to be extended with tailored choices of hyper parameters.
Open questions
We restricted the scope of this post, and hence did not yet follow leads that might show notable performance changes.
For example, the image captions we fed to CLIP’s fine-tuning are basically all the same: They mostly follow the template „a photo of <CLASS>“. This does not reflect what the zero-shot CLIP model was trained on, since it’s training data captions were broadly varying–as scraped from the web. Improved preprocessing could generate many variants of the above template (say with the help of an LLM), thereby aligning closer with training conditions. Would that improve CLIP’s performance?
How does performance between CLIP and ResNet50 compare on images taken in very static conditions, as can be found for quality assurance in production lines?
Investigating questions like these for a domain-specific classification use case and its image dataset helps to inform the model selection and thus make experimentation efforts more efficient.
Last but not least: Let me thank Wolfgang Reuter and Dr. Stefan Lautenbacher for coming up with the idea to investigate this and challenging and reviewing the work, as well as Emre Arkan and Anna Krymova for their contributions in early stages of this project.









0 Kommentare