
Unsupervised Machine Learning ist ein leistungsstarkes Werkzeug, um wertvolle Erkenntnisse aus Daten zu gewinnen. Im Gegensatz zum Supervised Machine Learning erfordert es keine gelabelten Daten, sondern zielt darauf ab, Muster, Strukturen oder Gruppierungen in den Daten automatisch zu entdecken. Durch Techniken wie Clustering, Dimensionalitätsreduktion oder Assoziationsanalyse können Unternehmen verborgene Informationen aufdecken, neue Erkenntnisse gewinnen und bessere Entscheidungen treffen.
Unsupervised Learning kann dabei helfen, Kundenverhalten zu verstehen, Betrugsfälle zu erkennen, Produktsegmente zu identifizieren und vieles mehr. Ein Verständnis von Unsupervised Machine Learning ist daher für Unternehmen wichtig, um das volle Potenzial ihrer Daten auszuschöpfen und Wettbewerbsvorteile zu erlangen.
Inhaltsverzeichnis
Was ist Unsupervised Machine Learning?
Unsupervised Machine Learning ist eine Art des maschinellen Lernens, bei der ein Algorithmus Muster und Strukturen in Daten entdeckt, ohne dass ihm eine Zielvariable oder eine menschliche Überwachung zur Verfügung gestellt wird. Im Gegensatz zum Supervised Learning, bei dem der Algorithmus trainiert wird, um eine Vorhersage oder Klassifikation auf der Grundlage von gelabelten Daten zu treffen, werden im unüberwachten Lernen keine gelabelten Daten benötigt. Stattdessen sucht der Algorithmus nach Strukturen in den Daten, indem er die Ähnlichkeiten zwischen verschiedenen Merkmalen oder Instanzen identifiziert und diese in Gruppen oder Cluster zusammenfasst.
Typische Anwendungen von Unsupervised Learning sind die Segmentierung von Kunden in der Marketingforschung, die Erkennung von Anomalien in der Cybersicherheit oder die Mustererkennung in der Bild- und Textverarbeitung.
Wie funktioniert Unsupervised Learning?
Beim Unsupervised Machine Learning muss der Algorithmus eigenständig Zusammenhänge und Muster in den Daten finden und diese nutzen, um die Daten zu strukturieren, zu gruppieren oder neue Erkenntnisse zu gewinnen. Dafür gibt es im Allgemeinen drei Arten von Unsupervised-Learning-Methoden: Clustering, Assoziation und Dimensionalitätreduktion.
Was ist Clustering?
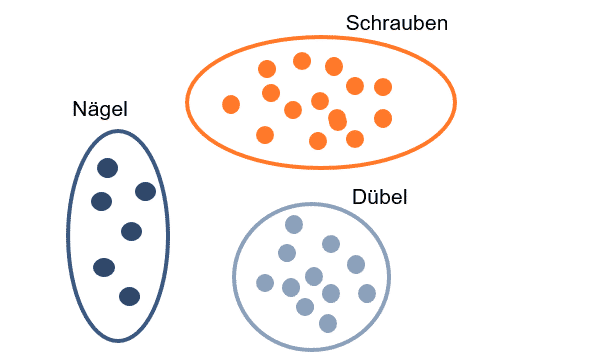
Beim Clustering gruppiert der Algorithmus Datenpunkte basierend auf Ähnlichkeiten in ihren Merkmalen in Cluster. Das Ziel des Clustering ist es, Muster in den Daten zu finden und diese zu gruppieren, um die intrinsische Struktur des Datensatzes zu erkennen. Als Beispiel kann das Kaufverhalten von Kunden in einem Supermarkt analysiert werden, um ähnliche Käufergruppen zu identifizieren, die ähnliche Produkte kaufen.

Clustering kann in verschiedenen Anwendungen eingesetzt werden, wie z.B. in der Marktsegmentierung, der Identifizierung von Mustern in der biologischen Forschung oder der Erkennung von Anomalien in der Cybersicherheit.
Clustering-Algorithmen
k-Means-Algorithmus
Der k-Means-Algorithmus ist einer der am häufigsten verwendeten Clustering-Algorithmen. Dabei werden die Daten in k Gruppen oder Cluster aufgeteilt, wobei k die Anzahl der vorgegebenen Cluster ist. Der Algorithmus beginnt mit zufällig ausgewählten k Zentren und weist jedem Datenpunkt das nächstgelegene Zentrum zu. Anschließend werden die Zentren neu berechnet und die Datenpunkte werden erneut zugewiesen. Dieser Prozess wird wiederholt, bis die Zuweisungen stabil sind.
Hierarchical Clustering
Beim Hierarchical Clustering werden die Datenpunkte schrittweise in Gruppen zusammengefasst, um eine Hierarchie von Clustern zu erstellen. Es gibt zwei Arten des Hierarchical Clustering: agglomerative und divisive. Im agglomerativen Clustering beginnt jeder Datenpunkt als eigenes Cluster. Diese Cluster werden schrittweise zusammengefasst, um größere Cluster zu bilden. Im divisive Clustering beginnt der Algorithmus hingegen mit einem großen Cluster und teilt es in kleinere Cluster auf.
DBSCAN
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) ist ein Dichte-basiertes Clustering-Verfahren, bei dem der Algorithmus versucht, Cluster von dicht besiedelten Regionen zu finden. Datenpunkte in dicht besiedelten Bereichen werden als Teil desselben Clusters betrachtet, während Datenpunkte in dünn besiedelten Bereichen als Ausreißer oder Rauschen betrachtet werden.
Mean Shift
Mean Shift zielt darauf ab, potenzielle Clusterzentren in einem Datensatz zu identifizieren, indem er die Dichte der Daten schätzt und die Bandbreiten iterativ in Richtung der höchsten Dichte verschiebt, bis ein stabiler Konvergenzpunkt erreicht ist. Die Datenpunkte innerhalb jeder Bandbreite werden dann einem Cluster zugeordnet. Mean Shift ist besonders nützlich bei der Identifizierung von Clustern in Datensätzen mit unterschiedlichen Formen und Größen und in denen die Dichte der Datenpunkte nicht homogen verteilt ist.
Was ist eine Assoziationsanalyse?
Assoziation beim Unsupervised Learning bezieht sich auf das Entdecken von gemeinsamen Mustern und Beziehungen zwischen verschiedenen Attributen in einem Datensatz. Der Fokus liegt dabei darauf, welche Attribute oder Merkmale des Datensatzes oft zusammen auftreten und welche nicht. Das Ziel besteht darin, Regeln oder Assoziationen zu identifizieren, die angeben, welche Kombinationen von Merkmalen oder Attributen am häufigsten vorkommen.
Ein gängiges Beispiel für Assoziationsanalyse ist die Analyse von Kaufverhalten in einem Supermarkt. Zielstellung ist herauszufinden, welche Produkte oft zusammen gekauft werden, um beispielsweise Empfehlungen für zukünftige Kundenkäufe zu geben. Durch die Identifizierung von Mustern und Assoziationen kann das Unternehmen auch die Platzierung von Produkten im Laden optimieren oder die Werbung für bestimmte Produkte gezielter gestalten.
Assoziations-Algorithmen
Apriori-Algorithmus
Der Apriori-Algorithmus wird vorwiegend in der Marktforschung und im E-Commerce eingesetzt. Er identifiziert häufig auftretende Kombinationen von Attributen und kann auf verschiedene Arten modifiziert werden, um unterschiedliche Anforderungen an die Assoziationsanalyse zu erfüllen.
Der Algorithmus funktioniert in zwei Schritten. Im ersten Schritt werden alle einzelnen Elemente im Datensatz analysiert und die Häufigkeit jedes Elements ermittelt. Im zweiten Schritt werden Kombinationen von Elementen (Itemsets) analysiert, um die Häufigkeit von Kombinationen festzustellen. Der Algorithmus verwendet eine Unterstützungsschwelle, um häufige Itemsets zu identifizieren, die über der Schwelle liegen.
Eclat
Eclat (Equivalence Class Clustering and bottom-up Lattice Traversal) ähnelt dem Apriori-Algorithmus und verwendet eine Unterstützungsschwelle, um häufige Itemsets zu identifizieren. Im Gegensatz zum Apriori-Algorithmus verwendet Eclat jedoch keine Kandidaten-Generierung. Stattdessen nutzt es eine Equivalence-Class-Technik, um die Häufigkeit von Itemsets zu ermitteln. Eclat wird häufig in der Marktforschung und im Einzelhandel eingesetzt, um Zusammenhänge zwischen verschiedenen Produkten oder Dienstleistungen zu identifizieren.
FP-Growth-Algorithmus
Der FP-Growth-Algorithmus ist ein weiterer häufig verwendeter Algorithmus für die Assoziationsanalyse. Im Gegensatz zum Apriori-Algorithmus verwendet er jedoch keine Apriori-Prinzipien oder eine Kandidaten-Generierung. Stattdessen erstellt der Algorithmus einen Baum (FP-Baum) aus den Itemsets im Datensatz. Der Baum wird verwendet, um alle häufigen Itemsets im Datensatz zu identifizieren. Der FP-Growth-Algorithmus ist schnell und effizient, da er den Datensatz nur einmal durchläuft und den FP-Baum verwendet, um häufige Itemsets zu identifizieren.
Was ist eine Dimensionalitätsreduktion?
Bei der Dimensionalitätsreduktion wird die Anzahl der Merkmale in den Daten reduziert, während die wichtigsten Informationen erhalten bleiben. Dies ist ein wichtiger Schritt bei der Datenanalyse, insbesondere bei der Verarbeitung von großen Datensätzen mit einer hohen Anzahl von Merkmalen, die als „hohe Dimensionalität“ bezeichnet werden.
Das Ziel der Dimensionality Reduction besteht darin, den Datensatz in eine niedrigere Dimension zu transformieren, während wichtige Informationen beibehalten werden. Dies kann dazu beitragen, den Datensatz zu vereinfachen, die Rechenzeit zu reduzieren, den Speicherbedarf zu verringern und die Leistung von Machine-Learning-Algorithmen zu verbessern.
Als Beispiel hilft die Dimensionalitätsreduktion in einem Supermarkt-Kundendatensatz, die Vielzahl von Merkmalen, wie Alter, Geschlecht, Einkommen und Ausgaben, zu reduzieren. Damit können die wichtigsten Merkmale identifiziert und die Variation in den Daten am besten erklärt werden. Mit den extrahierten Hauptkomponenten können die Kunden in einem zweidimensionalen Raum visualisiert werden. Ähnliche Kunden liegen dabei nah beieinander, was auf Muster und Gruppierungen hinweisen kann. Dies ermöglicht es, Kundensegmente zu identifizieren und gezielte Marketingstrategien oder Angebote zu entwickeln.
Dimensionalitätsreduktions-Algorithmen
Es gibt verschiedene Methoden zur Dimensionalitätsreduktion, die in zwei Kategorien eingeteilt werden können: die Feature-Selektion und die Feature-Extraktion. Die Feature-Selektion besteht darin, die wichtigsten Merkmale oder Attribute aus dem Datensatz auszuwählen und die restlichen Merkmale zu verwerfen. Die Feature-Extraktion hingegen zielt darauf ab, neue Merkmale zu generieren, indem eine lineare oder nicht-lineare Transformation des ursprünglichen Merkmalsraums vorgenommen wird.
Principal Component Analysis (PCA)
Principal Component Analysis gehört zur Feature-Extraktion und wird häufig zur Analyse und Visualisierung von Daten verwendet. Das Ziel von PCA besteht darin, die Dimensionalität eines Datensatzes zu verringern, indem eine neue Reihe von Variablen (die sogenannten Hauptkomponenten) erstellt wird, die die Variation in den Daten so gut wie möglich erklären. Dabei werden lineare Transformationen auf die Daten angewendet, um eine neue Koordinatensystembasis zu finden, in dem die größte Varianz in der ersten Hauptkomponente liegt, gefolgt von der zweitgrößten Varianz in der zweiten Hauptkomponente und so weiter. PCA kann helfen, redundante Informationen in den Daten zu entfernen, rauschige Variablen zu reduzieren und die Datenstruktur zu vereinfachen.
Linear Discriminant Analysis (LDA)
Linear Discriminant Analysis ist ein Beispiel für Feature-Selektion und wird für Klassifikationen eingesetzt. Das Ziel von LDA besteht darin, eine lineare Kombination von Merkmalen zu finden, die die Klassen separiert und gleichzeitig die Variation innerhalb der Klassen minimiert. Im Gegensatz zur PCA zielt LDA darauf ab, die Daten in einen niedrigdimensionalen Raum zu projizieren, in dem die Klassen gut unterscheidbar sind. LDA berücksichtigt dabei die Klassenzugehörigkeit der Datenpunkte und optimiert die Projektion, um die Klassen so gut wie möglich zu trennen. LDA kann daher zur Merkmalsselektion oder zur Erstellung neuer Merkmale verwendet werden, die die Klassifikationsleistung verbessern sollen.
t-Distributed Stochastic Neighbor Embedding (t-SNE)
t-SNE kann sowohl als Feature-Extraktion als auch als Feature-Selektion verwendet werden. Es ist ein nichtlineares Verfahren zur Visualisierung hochdimensionaler Daten in einem niedrigdimensionalen Raum. t-SNE ist besonders gut geeignet, um komplexe Beziehungen und Muster in den Daten zu erfassen. Dafür verwendet es eine Wahrscheinlichkeitsverteilung, um die Ähnlichkeit zwischen den Datenpunkten in den ursprünglichen Dimensionen und im niedrigdimensionalen Raum zu berechnen. Dabei werden die Ähnlichkeiten so modelliert, dass Punkte, die in den ursprünglichen Dimensionen nahe beieinander liegen, in der niedrigdimensionalen Darstellung ebenfalls nahe beieinander liegen. t-SNE kann helfen, Cluster oder Gruppierungen in den Daten zu identifizieren und komplexe Datenstrukturen zu visualisieren.

Recommender, Clustering, Regression, Text Analytics, Anomaly Detection etc.:
Machine Learning kann heute für vielfältige Problemstellungen eingesetzt werden und ist dabei schneller und genauer denn je. Aber was hat es mit den Algorithmen dahinter auf sich?
Weitere Beispiele für Algorithmen
Unsupervised-Learning-Algorithmen können auch für andere Aufgaben wie die Anomalieerkennung oder die Generierung von Daten eingesetzt werden. Der Algorithmus lernt in diesem Fall, was normalerweise ist und kann somit ungewöhnliche oder abnormale Ereignisse erkennen oder neue Daten generieren, die den vorhandenen ähnlich sind.
Im Allgemeinen ist das Ergebnis des unüberwachten Lernens weniger präzise als das des überwachten Lernens, da der Algorithmus die Daten ohne Vorwissen über ihre Struktur untersucht. Dennoch kann es nützlich sein, um neue Einblicke in Datensätze zu gewinnen oder um komplexe Zusammenhänge in großen Datenmengen zu erkennen.
Anomalieerkennung
Anomaly-Detection-Algorithmen versuchen, ungewöhnliche oder abnormale Datenpunkte in einem Datensatz zu identifizieren. Besonders geeignet sind sie für Fraud Detection, bei dem
betrügerische Aktivitäten oder Transaktionen in einem System erkannt und verhindert werden sollen. Zu den gängigsten Algorithmen zählen:
- Isolation Forest
- Local Outlier Factor (LOF)
- One-Class SVM
Generative Modelle
Generative Modelle werden verwendet, um neue Daten zu generieren, die dem zugrunde liegenden Datensatz ähnlich sind. Beispiele dafür sind:
- Generative Adversarial Networks (GANs)
- Variational Autoencoders (VAEs)
Neural-Network-based Unsupervised Learning:
Neural-Network-based Unsupervised Learning nutzt neuronale Netze, um automatisch Merkmale in einem Datensatz zu erkennen und zu extrahieren. Häufig genutzt werden:
- Self-Organizing Maps (SOMs)
- Restricted Boltzmann Machines (RBMs)
Natural Language Processing
Natural-Language-Processing-Algorithmen werden speziell für die Verarbeitung von Textdaten verwendet und können beispielsweise Themen in Texten identifizieren oder semantische Ähnlichkeiten zwischen Wörtern berechnen. Gängige Algorithmen sind:
- Latent Dirichlet Allocation (LDA)
- Word2Vec

Die natürliche, gesprochene Sprache des Menschen ist der direkteste und einfachste Weg zur Kommunikation. Erfahren Sie, wie Maschinen und Algorithmen NLP innovativ nutzen:
Natural Language Processing (NLP): Natürliche Sprache für Maschinen
Unsupervised vs. Supervised Learning
Der wesentliche Unterschied zwischen Supervised und Unsupervised Learning liegt bei den Trainingsdaten. Beim Supervised Learning ist ein Satz von Trainingsdaten mit gelabelten Antworten (z. B. Klassifikationen) vorhanden, während beim Unsupervised Learning keine gelabelten Antworten vorgegeben sind und das System selbst Muster und Zusammenhänge in den Daten erkennen muss.
Die Zielsetzung beider Modelle ist auch komplett unterschiedlich. Beim Supervised Learning soll ein Modell trainiert werden, das in der Lage ist, neue, ungelabelte Daten korrekt zu klassifizieren oder vorherzusagen. Dagegen ist das Ziel beim Unsupervised Learning, verborgene Strukturen oder Muster in den Daten zu erkennen und zu verstehen.
Ein weiterer wichtiger Unterschied ist, dass Supervised Learning tendenziell für eng umrissene und spezialisierte Aufgaben wie Bilderkennung, Sprachverarbeitung und Vorhersage von Kundenpräferenzen verwendet wird, während Unsupervised Learning eher für Aufgaben wie Clustering, Anomalieerkennung und Dimensionalitätsreduktion eingesetzt wird.
Trotz dieser Unterschiede gibt es auch Gemeinsamkeiten zwischen Supervised und Unsupervised Learning. Beide Techniken nutzen Machine-Learning-Algorithmen, um Muster und Zusammenhänge in Daten zu erkennen und Prognosen zu treffen. Beide Techniken können in vielen verschiedenen Anwendungsbereichen eingesetzt werden, um Erkenntnisse und Vorteile zu generieren. Und schließlich können beide Techniken zusammen in hybriden Ansätzen, wie Semi-Supervised Learning, verwendet werden, um noch bessere Ergebnisse zu erzielen.

Weitere Informationen zu Supervised Machine Learning erhalten Sie in unserem Grundlagenbeitrag für Einsteiger und Fachkundige:
Was sind Vorteile von Unsupervised Learning?
- Keine gelabelten Daten erforderlich: Im Gegensatz zum Supervised Learning sind keine gelabelten Trainingsdaten erforderlich. Dies kann sehr nützlich sein, wenn es schwierig oder teuer ist, gelabelte Daten zu beschaffen.
- Erkennung verborgener Muster: Unsupervised Learning kann verborgene Muster und Strukturen in Daten erkennen, die auf den ersten Blick nicht offensichtlich sind. Dies kann dazu beitragen, neue Erkenntnisse und Einsichten zu gewinnen, die sonst nicht entdeckt worden wären.
- Erkennung von Anomalien: Unsupervised Learning kann Anomalien oder Ausreißer in Daten erkennen, die auf Probleme oder Abweichungen hinweisen können. Dies kann in vielen Anwendungen wie Betrugserkennung, Sicherheit oder Gesundheitsüberwachung nützlich sein.
- Flexibilität: Unsupervised Learning ist flexibel und kann auf viele verschiedene Arten angewendet werden. Dies macht es zu einem vielseitigen Werkzeug für die Datenanalyse und das maschinelle Lernen.
- Skalierbarkeit: Unsupervised Learning kann auf große Datensätze angewendet werden und ist in der Regel skalierbar, was bedeutet, dass es auch für komplexe Probleme und große Datenmengen eingesetzt werden kann.
Insgesamt bietet Unsupervised Learning eine effektive Möglichkeit, Daten zu analysieren und Muster zu erkennen, die zur Lösung von komplexen Problemen beitragen können.
Was sind Nachteile von Unsupervised Learning?
Obwohl Unsupervised Learning viele Vorteile bietet, gibt es auch einige Nachteile, die berücksichtigt werden sollten:
- Schwierigkeit bei der Bewertung: Da es bei Unsupervised Learning keine Zielvariablen gibt, ist es schwieriger zu beurteilen, wie gut der Algorithmus funktioniert. Es gibt keine klare Möglichkeit, die Vorhersagen des Modells zu bewerten, dadurch sind die Ergebnisse schwieriger zu interpretieren und zu validieren.
- Fehlinterpretation von Ergebnissen: Es ist möglich, dass das Modell falsche Muster erkennt oder interpretiert, die keine Bedeutung haben. Wenn diese Muster dann als Grundlage für Entscheidungen herangezogen werden, können sie ungenau oder irreführend sein.
- Overfitting: Unsupervised Learning-Modelle können zu Overfitting tendieren, insbesondere wenn die Anzahl der Merkmale in den Daten hoch ist. Das Modell kann dann Muster erkennen, die nur in den Trainingsdaten vorhanden sind und nicht generalisierbar sind.
- Benötigt Expertenwissen: Unsupervised Learning-Modelle erfordern in der Regel eine gewisse Menge an Expertenwissen, um richtig konfiguriert und interpretiert zu werden.
Es ist wichtig, diese Nachteile bei der Anwendung von Unsupervised Learning-Techniken zu berücksichtigen und geeignete Maßnahmen zu ergreifen, um die Ergebnisse zu validieren und zu interpretieren.
Fazit: Warum wird Unsupervised Machine Learning eingesetzt?
Unsupervised Machine Learning ist ein wichtiges Instrument, mit dem Unternehmen wertvolle Erkenntnisse aus ihren Daten gewinnen können. Durch Techniken wie z. B. Clustering, Dimensionalitätsreduktion und Assoziationsanalyse kann Unsupervised Learning verborgene Muster, Strukturen und Zusammenhänge in den Daten aufdecken. Dies ermöglicht es, Kundenverhalten zu verstehen, Betrugsfälle zu erkennen, Produktsegmente zu identifizieren und vieles mehr. Unüberwachtes Lernen hat seine Vorteile in Bezug auf die Flexibilität bei der Datenanalyse und die Möglichkeit, neue Erkenntnisse zu gewinnen. Es ist jedoch wichtig, die Grenzen und Herausforderungen von Unsupervised Learning zu verstehen und die richtigen Algorithmen und Techniken für spezifische Anwendungsfälle auszuwählen. Durch die Kombination von Unsupervised Learning mit anderen Methoden des maschinellen Lernens können Unternehmen ihr Wissen erweitern und fundierte Entscheidungen treffen, um ihren Geschäftserfolg zu steigern.









0 Kommentare