
Did you know that the first Porsche, the P1 model from 1898, was an electric car? It had a range of 79 km and has since been forgotten while combustion technology prevailed. And did you know that our ancestors farmed their fields much more efficiently than is possible with modern agricultural methods? Today, agriculture is characterised by monocultures and the excessive use of fertilisers and pesticides - leading to degraded soils, malnutrition and accelerated climate change.
Only recently have we begun to question these developments. What we can learn from our experiences is to be inspired more by nature - and thus come up with more sustainable answers.
At the moment, we are experiencing hype around Deep AI. Industry experts believe that through AI, the Global economy to grow by $15 trillion by 2030 could. According to the latest IDC forecast, global AI spending will double to $110 billion over the next four years. Energy costs for Deep Learning increased 300,000-fold between 2012 and 2018. The most innovative language model in 2019 had 1.5 billion parameters. The 2020 version has 175 billion parameters. What's next?
Is there an end, a limit - or are we about to make the same mistake by following another unsustainable hype? We need to look at fundamentally different approaches to AI!
Inhaltsverzeichnis
Ordinary Intelligence for an Artificial General Intelligence
In a blog post last year, we outlined the milestones on the road to "true artificial intelligence" - a Artificial General Intelligence (AGI) - discussed.
The solutions used in the industry for artificial intelligence are often referred to as "narrow AI". They can usually only perform one task. A natural neural network like the human brain, on the other hand, is universal. One and the same network can perform an infinite number of tasks. Brains can dynamically recognise and take on new tasks that fit the context.
On the way to a more general AI, it is important to be aware of the differences between artificial and biological neural networks. Possible pitfalls of such comparisons will be discussed in later papers. For now, let's question the widely accepted idea of scaling existing approaches and explore alternatives.
Scaling is not the solution
You may have heard of the GPT models (Generative Pre-Trained Transformer Models) from OpenAI heard. The 175 billion parameters in the latest version, GPT-3, were trained with an incredibly large amount of text data (the English Wikipedia accounts for only 0.6 % of it). At launch, the model made huge waves in the media due to its amazing properties.
In the face of such developments, the temptation to believe that more is always better is great. Larger and larger networks are being trained with more and more data. The main justification for continuing down this path is that scaling up has worked so far.
However, we seem to be riding a self-perpetuating hype. The current models are getting bigger and bigger because "we can do it". We know how to scale them. We know how to train them. We are given more and more powerful hardware. And money is being invested to get even further ahead. One is reminded of high-tech trends in agriculture, such as modern management of monocultures for greater yields of profitable crops that ultimately deplete the soil. But the harvest does not scale over time. And yet these unsustainable practices are widespread and the problem largely unrecognised. A recent Netflix documentary called "Kiss the ground" attempts to shed some light on the issue.
Similarly, a 2019 paper from the Allen Institute for AI points out the diminishing returns of model size in all AI sub-areas. Many of the added nodes in the networks are not utilised after training - they only increase flexibility during training. Similarly, most neurons and connections in the brains of growing children are created as they experience the world. Instead, unused synapses and cell bodies in brains are removed and recycled (see video below). Therefore, only essential parts of the network consume energy. This is not the case in classical non-adaptive Deep Learning, where the dimensions of a network remain fixed once they are established.
While the models may have gained a few percent in accuracy and performance, their energy consumption has increased disproportionately. This happened even though computer hardware became more efficient. The cost of researching and training a state-of-the-art language model like BERT Transformer are equivalent to the cost of a 747 jet flying from New York to San Francisco. To put this in perspective: That's about the same amount of CO² as five average cars emit over their lifetime (including fuel). The US Department of Energy estimates that data centres contribute about 2 per cent of total energy consumption in the country. This is pretty much equal to the electricity consumption of the agricultural sector and ten times that of public transport.
Today, this energy comes mainly from traditional energy sources. The big tech companies are aware of this problem. Google, Microsoft, Amazon and Facebook claim to be carbon neutral or even on their way to having negative emissions. It is important to note that their focus is not on using less energy, but on using cleaner energy. What we are seeing is simply a growing demand for energy in this area. And the amount of green energy available is still limited (between 11 % and 27 % of the global electricity generation mix). For more figures on the environmental costs of AI, see WIRED magazine and MIT Technology Review. The DIN Deutsches Institut für Normung e. V. and the German Federal Ministry for Economic Affairs and Energy, in cooperation with 300 experts, have published a current industry guide. It is not surprising that the guide states "It must be ensured that the most energy-efficient variant of the analysis is chosen".
Of course, we should not forget that AI also contributes to energy saving by enabling more efficient processes. One example of the profitable use of AI to save energy is smart buildings. AI can make a strong contribution to greater sustainability if it is used correctly, taking into account environmental, economic and social aspects.
The success of the scaling of GPT-2 to GPT-3 triggered widespread predictions about when we will reach artificial general intelligence. Such theses are often based on false assumptions and misleading comparisons with numbers in nature. This prompted deep learning legend Geoffrey Hinton (UCL) to make a Twitter joke:
By loading the tweet, you accept Twitter's privacy policy.
Learn more
What do we really understand?
It is rare for data scientists to design and train a complex neural network model without trial and error.
As the size and amount of generalised training data increases, the intuition behind these models is already more and more lost. Their creators are often surprised by the results of their own model - be they bad or good results. Sure, formulas can be written down. Diagrams can be drawn, and we may even have a vague idea of the flow of information and the transformations that take place. We can also quite successfully put together different networks where we have an idea of what is happening. But predicting which model architecture is best for a particular task becomes increasingly difficult as models and data sets grow.

From this point of view, it is not surprising that the results of the GPT-3 model were so startling. The architecture of this is very complex and its training data extremely non-specific, which is why there is no clear intuitive understanding of such a model.
Although the output can be surprising, it is ultimately "just" a "normal" model without magic and does not even come close to what a human brain can do. It was trained with no particular goal other than to produce a coherent sequence of words, and therefore its results were unpredictable. This is true of unsupervised learning methods in general. Especially when applied to massive unstructured data.
This raises a fundamental question: Given the success of GPT-3, do we even need to fully understand every element of a model? There seems to be a consensus in the field: Understanding is a "nice to have", but not essential for AI applications. This is expressed in the first two words of the following quote from Terrence Sejnowski, co-inventor of the Boltzmann machine:
"Perhaps one day an analysis of the structure of deep learning networks will lead to theoretical predictions and reveal deep insights into the nature of intelligence." - Terrence J. Sejnowski
Great tricks are invented to increase the accuracy of a model without really knowing why they work. For example, the Microsoft research group recently set out to solve "three mysteries of deep learning". Explanations for the success of methods are offered after the fact, long after they have been in use. This is typical of the industry.
Another typical strategy in Deep Learning is to inflate existing architectures and use more data for training (as in the development from GPT-2 to GPT-3). Often the motto is "Just try it!". In the case of GPT-3, this resulted in the fact that - although its model architecture does not provide a basis for proper understanding (as would be required for an artificial general intelligence) - it is able to imitate the writing behaviour of humans very well due to the huge amount of data. This is because the huge corpus of text provided for training contains a description for almost everything.
Given the attractiveness of such approaches, it is not surprising that in practice we hardly see network architectures that are fundamentally different. Models that are not differentiable are underrepresented. In such models, the approaches that lead to an optimal solution cannot be calculated. Training the parameters of such networks is again like blind guesswork.
It is even claimed that GPT-3 has learned arithmetic. Yes, it can do some simple calculations - just like those found in the training data. It can even generalise the concepts to some extent. However, GPT-3 had the goal of learning the joint probability structure of a massively large set of texts. A mathematician knows with certainty that the result is 123 (with a probability of 100%) if it is 12345.678/12344.678 calculated. A generative model like GPT-3 can only guess the outcome with residual uncertainty. It makes a best guess. It will probably even suggest a completely different result in this case. It may not have seen these numbers before. Therefore, the joint probability distribution of this input is inadequately represented. The input cannot be related to the correct output.
It is no surprise that the hype around this model has even prompted the CEO of openAI to intervene:
By loading the tweet, you accept Twitter's privacy policy.
Learn more
There are alternatives
Neurons under fire
The vast majority of neural networks used in machine learning and AI consist of highly simplified neurons. In contrast, so-called spiking neuron models attempt to more rigorously mimic biological neurons, which comes at the price of greater complexity. This complexity, in turn, allows for richer functionality and more powerful computations. One of the simplest and most well-known spiking neuron models is the leaky-integrate-and-fire model. With the technological advances in implementing such models directly in hardware, it is almost certain that we will hear more of such neuron models.
Reservoir Computing
In some areas of AI, reservoir computing is a promising approach. In short, this approach exploits the complexity of highly nonlinear dynamic systems such as recurrent neural networks with fixed parameters. Feeding data sequentially into such a system triggers resonant behaviour. It is like the impact of a stone or a raindrop on the surface of a small pond. Or creating an echo in a cave. The reactions within such systems are difficult to predict.
Even though most of the network seems to be just doing chaotic nonsense, one part of the system may actually be doing something as complex as frequency analysis. Another part may be doing smoothing or classification.
Reservoir computing does not even attempt to train the parameters of such systems. Instead, it learns where to find the interesting computation within such systems. This is extremely promising, considering how much time is currently spent training network parameters. Moreover, it is not even necessary to simulate networks here. We can - or could - just use physical systems like a simple bucket of water. Since there is no need to run huge computer clusters to learn networks, reservoir computing can operate with minimal energy consumption. It is not yet clear how to maximise the potential of this approach, but the field is evolving.
Let the monkey design the model
A fundamentally different but promising approach that will gain attention next year is Neural Architecture Search (NAS) and related techniques. Here, many different network architectures are tried out and then only the best options are selected. The way the architectures are built can be completely random and still lead to very good results. It's like a monkey sitting in front of a computer designing the next breakthrough architecture. Here's what the authors of a 2019 paper from Facebook report:
"The results are surprising: several variants of these random generators yield network instances that have competitive accuracy on the ImageNet benchmark. These results suggest that new efforts focused on designing better network generators can lead to breakthroughs by exploring less constrained search spaces with more room for novel design." - (Xie et al. 2019, Facebook AI Research)
Of course, we can also educate the monkey to type less randomly. One search strategy that comes in handy in this context is the class of evolutionary algorithms.
Making models smarter
Researchers from Boston and Zurich brought a promising idea to the public just a few months ago: Shapeshifter Networks. Instead of reusing neurons within a network as in brains, they propose to reuse at least some of the connections between neurons. This can drastically reduce the effective number of parameters to be learned: They create powerful models even if they use only 1% of the parameters of the existing models. This in turn leads to a reduction in training time and energy consumption.
Free lunch in the depth?
We have presented several alternative AI strategies. However, it is important to note that there is not one universal solution to all optimisation problems. This theorem is called the no-free-lunch problem (NFLP) of machine learning. Deep learning methods can often be used quite universally. Nevertheless, the theorem still applies.
Stuck in the deepest valley
In the future, the discussion of alternative approaches to traditional machine learning will be guided by a key insight from biology: There is no optimal solution when it comes to interactions with an incredibly complex and dynamic physical reality. Evolution does not face the NFLP because it does not work towards an optimal solution. Nevertheless, it is the most successful path to intelligence that we have discovered so far.
Biology makes use of the existence of several suboptimal solutions. In this way, it is possible to jump back and forth between them, which is what makes the flexible action of living beings possible in the first place. This is also how the nanomachines that make up our bodies work. For example, look at the opening and closing of the ion channel of a biological neuron in Figure 6.
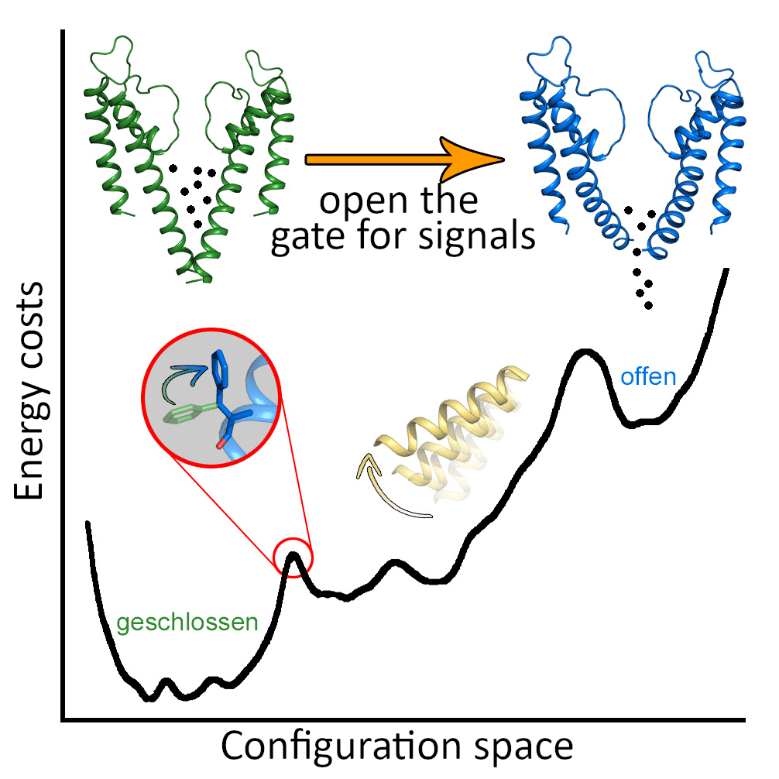
If everything were to move only towards a global optimum, all momentum would be gone. Let's take our body as another example: it would be stuck in an optimal pose as long as there were no significant changes in the environment that would shift the optimum and trigger a new search for it. A changing world simply cannot be described by a fixed weight matrix that has been trained to perform only a finite number of tasks.
Currently, the industry addresses this problem with active and adaptive learning approaches, where weights are continuously updated based on new experiences. However, a sudden jump from one configuration (suboptimal solution) to another, triggered by changing circumstances, is not really taken into account yet. Instead, sub-networks with a massive number of nodes are trained under the bonnet for each of the possible circumstances (which could be called different tasks). But as we have seen, cultivating ever larger networks is not the only solution! It would be more elegant if AI systems could detect and respond to changing circumstances. Especially in the context of hyper-automation, which Gartner has identified as one of the current Top trends in technology has been identified. AI systems must be enabled to automatically change the configuration of their existing architecture. Or even to dynamically change the readout of their computational reservoir. Just like in nature.
Sooner or later, therefore, we should probably say goodbye to the idea of learning the optimal weights of a neural network. Such parameters can only be optimised with respect to stable conditions.
It is not wrong to be suspicious of mainstream approaches. Geoffrey Hinton even encourages thinking outside the box:
"The future depends on some PhD student who deeply distrusts everything I have said... My view is to throw it all away and start again." (Geoffrey Hinton, UCL)
New performance indicators are needed
Normally, an artificial neural network is evaluated based on its accuracy (or another performance metric) in a task. An interesting alternative, which will become more and more important in the future, is accuracy in relation to energy consumption. As a network scales, each additional unit also requires more energy and energy is expensive. Besides the impact on the environment, low energy consumption will also play an essential role in the world of IOT, small medical devices and blockchains for huge for the economy. Thus, in the context of more general-purpose AI, another performance indicator is crucial for comparing different network architectures: the number of possible applications in terms of energy consumption. How many tasks can the network handle at what energy cost?
"The human brain - the original source of intelligence - provides important inspiration here. Our brains are incredibly efficient compared to today's deep learning methods. They weigh a few pounds and require about 20 watts of energy, barely enough to power a dim light bulb. And yet they represent the most powerful form of intelligence in the known universe." - Rob Toews @ Forbes Magazine
Energy consumption not only costs money, but also CO2. A recently published ML CO2 Impact helps you estimate the CO2 consumption of machine learning applications. Tools like this help to implement the proposed KPIs for your next AI project.
Free lunch for you
An important message for leaders is certainly that the very desire to create intelligence that is close to the human being repeatedly fosters enormous talent and produces promising technologies that find their way into practice. It is therefore important not to be blinded by lofty promises, nor to close your mind to innovative approaches beyond the established ones. Lofty goals may be riskier, but if they succeed, the positive effect is all the greater.
Yes, it is good advice to evaluate promises in the field of AI by comparing them to what we find in nature. However, this comparison should be made with caution. Nature is an incredibly good guide and provides inspiration for the most promising and sustainable technologies. And so far, it works (much) better than anything mankind has invented - including AI.
Conclusion
In the 1940s, AI pioneers mimicked the structure of the human brain. Since then, AI has evolved and achieved enormous successes of its own, but the current state of the art of deep learning is still far from human intelligence. The industry likes to apply the discipline "as is". However, recent research shows how fruitful the use of biologically inspired hardware and software could be. This article aims to highlight some promising work in this direction and encourage those using AI to be open-minded about these advances.









0 Kommentare