
Transfer learning is a learning method in the field of machine learning that transfers learned knowledge from one use case to another similar use case. Initially, this technology was mainly used for image analysis, but in recent years transfer learning has also become increasingly important in the field of text processing / natural language processing (NLP). In 2018, Bidirectional Encoder Representations from Transformers (BERT) was released by Google and is considered the foundation for a new kind of text processing. This article aims to explain the basics of transfer learning and how Google BERT works.
People's search behaviour on Google has changed enormously in the last 15 years. Especially since the introduction of virtual assistants such as Siri, Alexa or Google Assistant, the complexity of questions has increased. The trend of search queries is moving strongly from short-tail questions to long-tail questions. By designing the neural transfer learning model BERT, Google improved the way users' queries are understood. Thus, the best possible results can be delivered based on their search queries. Language models like BERT are an example of how information learned from one dataset can be transferred to other datasets for specific tasks.
Inhaltsverzeichnis
Use & advantages of Transfer Learning
Generally based Machine Learning Methods This is because the training and test data come from the same feature space and the same distribution. However, if the distribution changes due to a new use case, such statistical models have to be built from scratch using newly collected training data. However, extending the required training data or building new models is in many cases too expensive, if not impossible. To reduce the effort of collecting new training data, transfer learning is a particularly helpful method. The increase in new training data that is aggregated in the course of transfer learning also enables the model to learn quickly and thus recognise a connection between complex issues.
Training data is therefore essential for the further development of a machine learning model. Transfer learning offers the advantage that Less training data needed to solve a system be used. If new training data of an already completed model can be accessed via transfer learning, much less existing data is sufficient for further development. The reason for this is that a model can already learn features from another data set via transfer learning. In addition, transfer learning makes it possible to shorten the training time. Suppose a model is to be developed that recognises domestic cats in pictures and there is already a pre-trained model that recognises predatory cats in pictures. With transfer learning, an attempt can be made to adapt the model for the recognition of domestic cats with the help of the predatory cat data. It helps that many structures or patterns in the data are similar and do not have to be learned again.
Basics Google Bert
BERT stands for Bidirectional Encoder Representations from Transformers and is described by Google as one of the most significant updates in recent years. It is a special application of transfer learning and is considered the cornerstone of a new kind of Natural Language Processing. NLP refers to an area of AI and deals with text analysis and /processing of natural language. The computer should be able to understand the way people communicate naturally. The Algorithm model BERT based on neural networkswhich up to now has functioned exclusively as a standard in image processing. Google thus makes it possible to display more targeted answers for search queries. A significant difference to its predecessor RankBrain is that BERT improves the content of search queries and especially the understanding of individual words in the overall context in so-called long-tail search queries. This is thanks to a calculation model called Transformer.
A transformer not only tracks the meaning of each word in a sentence, but additionally relates a word to all other words in that sentence. It also improves the recognition of the meaning of filler words such as "for", "on" or "to". This helps Google understand the actual intention of Better understand long-tail search queries. After the update of BERT, it is thus possible to ask a question as if you were asking a good friend for advice.
Especially since the introduction of virtual assistant such as Siri, Alexa or Google Assistant and the resulting higher popularity of "voice searches", longer search queries are becoming more and more important. The statistics service Comscore illustrates this with a statistic. The share of voice searches is expected to reach 50 percent by the end of 2020. BERT wants to make Featured Snippets more prominent. These are highlighted entries after entering a Google search, which serve the user to find answers more quickly and clearly.
How BERT Transformer works
By developing models called transformers, Google's research team can train BERT's own state-of-the-art question answering system. In order to understand the intention behind a search query, the Words processed in relation to all other words in a sentence, instead of one after the other in sequence. Thus, the BERT Transformer can more accurately represent both recurrent and highly complex models such as translation quality. In addition, the BERT Transformer is also much more suitable for modern machine learning hardware, as it requires fewer computations to train translation models.
When transformers are used, a mechanism is applied at each step that models direct relationships between words regardless of their sentence position. To calculate the relationship for a particular word, such as 'grammar school', the transformer compares it to every other word in the sentence. The result of this comparison is called the 'Attention Score'. It thus determines the relationship to every other word in the sentence. The word "Gymnasium" can therefore receive a high Attention Score if the model determines a connection with university.
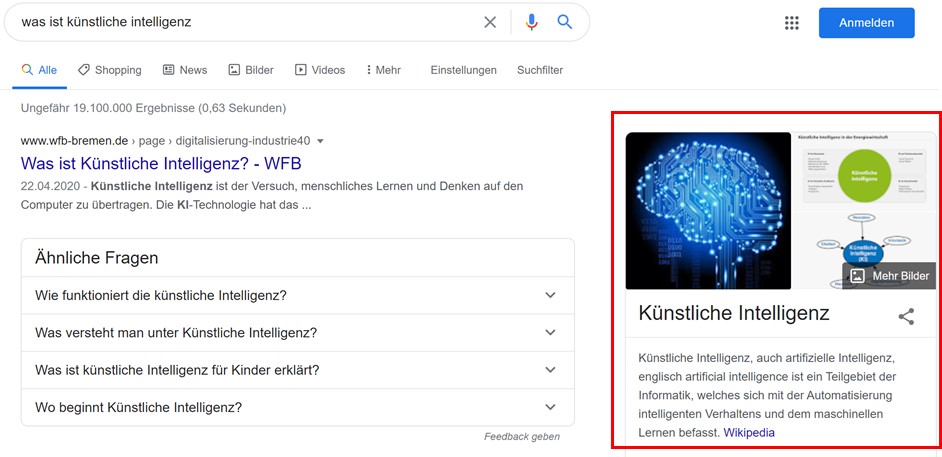
The attention score of each word is used in the following step for a weighted average of all words. These are then fed into a fully connected network to create a new connection between the words "Gymnasium" and "Universität" that reflects the chronological order of the two institutes. The BERT Transformer is the midpoint between text input and text output, using a so-called encoder for text input and a decoder for text output.
The illustration below shows that the encoder component is a series of individual encoders and the decoder component is a series of individual decoders. The encoders are divided into the Feed Forward Neural Network and SelfAttention layer. Here, the encoder's input first passes through the Self-Attention layer, which is used to look at all words while the encoder encodes a specific word. The output of the Self-Attention layer is then transferred to the Feed Forward Neural Network layer, which is applied independently to each item. The same process is carried out in the decoder, the only difference being the Attention layer, which helps the decoder to focus on the relevant words in the input sentence.
Each input word is transformed into a 512-byte vector using an embedding algorithm. Embedding algorithm is a natural language modelling technique where words or expressions from the vocabulary are mapped to vectors of real numbers. The embedding of the vectors is done exclusively in the lowest encoder.
Procedure in the encoder
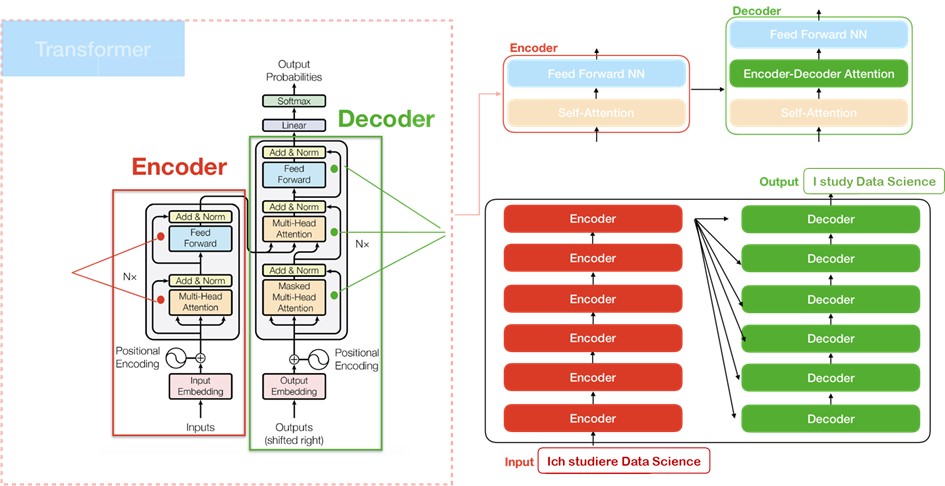
All encoders receive a list of vectors of 512 bytes each. After the words are embedded in the input, each word flows first through the Self-Attention and then through the Feed Forward layer of the encoder. A particular advantage of BERT Transformer is that each word in each position by its own path flows in the encoder. The Self-Attention layer calculates the weighting of a word within the sentence using vectors. For each word entered, three vectors are first created that have already been pre-trained:
- Query vector (queries): 64 bytes
- Key vector (Keys): 64 byte
- Value vector (Values): 64 byte
Then the Self-Attention score is calculated. In the following picture, the two words "Thinking" and "Machines" are given as examples.
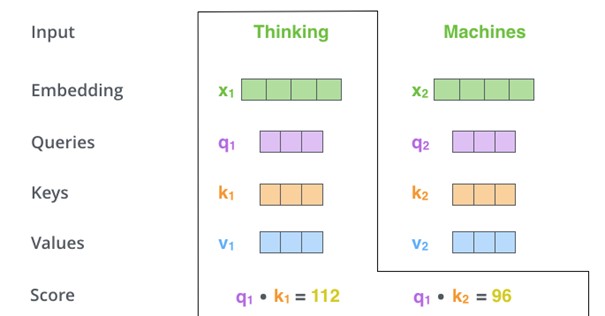
The score determines how much focus to place on other words in the input set when a word is encoded at a particular position. The score of the evaluating word is calculated by multiplying the query vector q1 and the key vector k1. When processing the self-attention for the word "thinking", the score 112 results from q1 and k1. The second score with a value of 96 results from q1 and k2. To normalise the values for a positive result, the next two steps consist of dividing the two scores by 8 (The square root of the bytes - 64) and then running a softmax operation.
Softmax normalises the scores so that they are all positive and add up to 1. In this case, the Softmax number is 0.88 for score 112 and 0.12 for 96. This means that q1 multiplied by k1 has a higher recognition value than q1 multiplied by k2. The fifth step consists of multiplying the single value vector by the softmax value. Step Six is to combine the weighted value vectors, resulting in the output of the Self-Attention layer. The resulting vector is passed to the feed-forward neural network.
Procedure in the decoder
The encoder initially processes the input word. As can be seen in the following figure, the output of the last encoder is then converted into a set of attention vectors K and V. These are used by each decoder in its 'encoder-decoder attention layer to help the decoder focus on appropriate locations in the input sequence. The figure also shows that once the encoding phase is complete, the decoding phase begins. Each step in the decoding phase outputs an element of the output word, such as in this case the translation of 'I' to the English word 'I'.
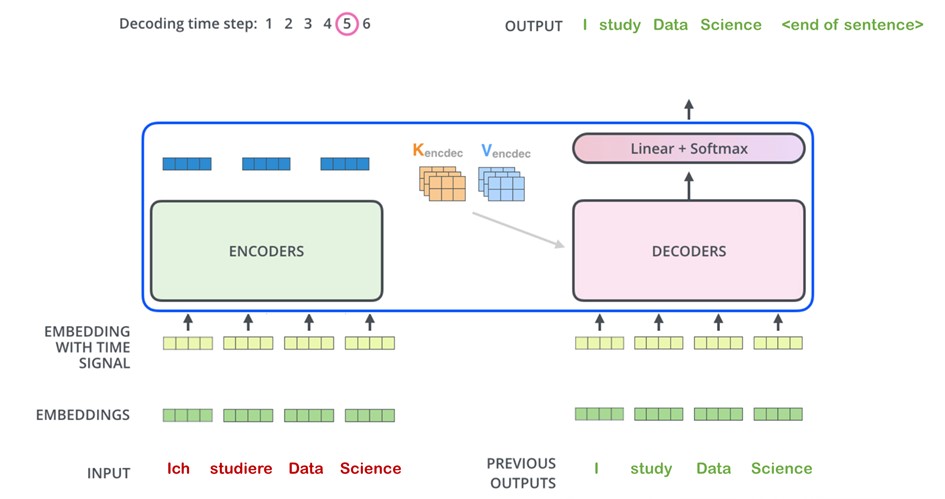
In the following steps, the process of translating each word is repeated until the translation from 'I study Data Science' to 'I study Data Science' is completed. Then an icon appears indicating the completed output of the Transformer Decoder. For the final step after the output of the decoder, the Linear layer and Softmax layer are used. The linear layer is a simple, fully connected neural network that projects the output set of the decoder into a larger vector called a logistic vector.
As an example, a model is shown with 100,000 unique English words that are already known from a training dataset. Thus, the logistics vector would accordingly be 100,000 cells wide, as each cell corresponds to the score of a unique word. The Softmax layer then converts the scores into probabilities. The cell with the highest probability is selected so that the connected word is represented as the output record.
For this reason, the pre-trained BERT model with the newly developed components of the transformer can predict relatively accurately whether the translation from the German sentence into the English sentence is correct and whether the order of the words within the sentence is logically structured. After the model has been trained for a sufficiently long time on a sufficiently large data set, the results of the probability distributions can be seen in the following figure.
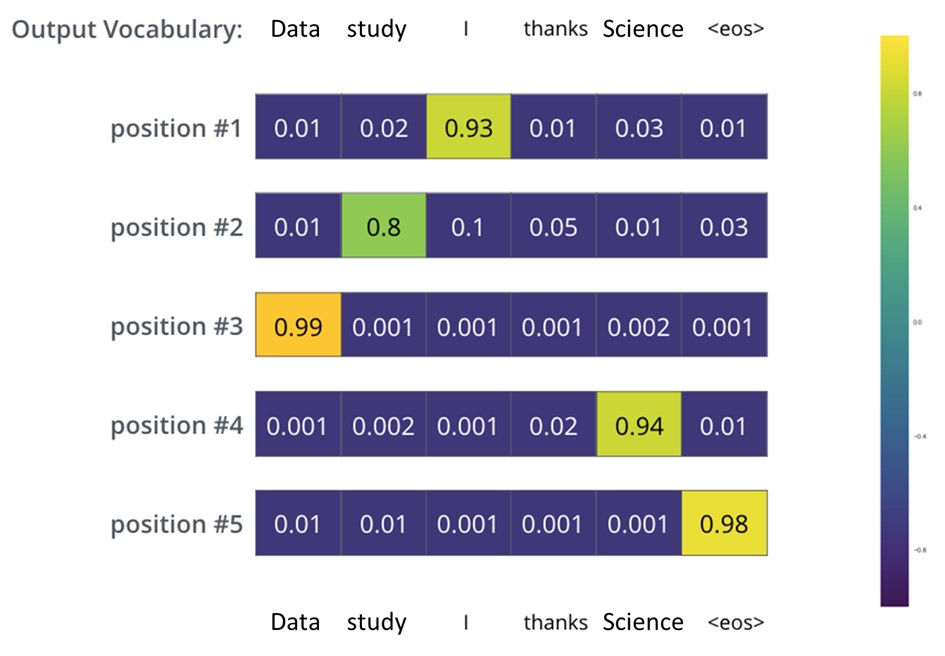
The probability distribution of each word is represented by a vector. In the first probability distribution (position 1), the cell associated with the word 'I' has the highest probability. The second probability distribution at position 2 has the highest probability in the cell associated with the word 'study'. This procedure is repeated until the end of the sentence is marked with the symbol 'eos'. The best-case scenario that lists each position with a probability distribution of 1.0 would be optimal, but this does not correspond to reality. Compared to other neural networks, the accuracy level of BERT performs very well.
The Stanford Question Answering Dataset (SQuAD) shows an average accuracy factor of 93.16 % for Bert. It is striking that BERT is only listed in position 7 in this ranking. This is due to the fact that BERT was listed in 2018 as one of the most important milestones in transfer learning history and has since served as a predecessor model for many other models.
This blog article has followed the work of Maximilian Linner and Timo Müller on the topic of "Use of transfer learning based approaches to text analysis".






0 Kommentare