
In 2022 we will celebrate the 10th anniversary of [at] - Alexander Thamm.
In 2012, we were the first consultancy in the German-speaking world to take up the cause of Data & AI. Today, it can be said that artificial intelligence (AI) has the potential to make an important contribution to some of the major economic and social challenges of our time. AI plays a role in the energy transition and in responding to climate change, in autonomous driving, in the detection and treatment of diseases or in pandemic control. AI increases the efficiency of production processes and increases the adaptability of companies to market changes through real-time information as well as predictions.
The economic significance of the technology is increasing rapidly. More than two thirds of German companies now use artificial intelligence and machine learning (ML).
With our #AITOP10 we show you what's hot right now in the field of Data & AI. Our TOP10 lists present podcast highlights, industry-specific AI trends, AI experts, tool recommendations and much more. Here you get a broad cross-section of the Data & AI universe that has been driving us for 10 years now.
Inhaltsverzeichnis
Our Top 10 ML Algorithms - Part II
Recommender, clustering, regression, text analytics, anomaly detection... Machine Learning can be used today for a variety of problems and is faster and more accurate than ever. But what is it about the algorithms behind it? We take a look behind the scenes and show you which algorithms are really used in machine learning.
Rank 5 - k-nearest neighbours
Imagine you are looking for a job. Your 3 best friends are standing around you, advising you on whether you should become a data strategist or a data scientist. What consensus would there be among the three? And what would be the consensus among your 5, 10 or even 20 best friends?
K-NN solves this problem very simply: The one who is closest wins. So if you are standing right next to a data strategist, you are now one too. Now, however, it may be that this one Data Strategist desperately wants to convince you to become one too, because all around are only Data Scientists. This is where the "k" comes to the rescue: The k determines how many of your friends closest to you are included. If k=3, your 3 closest friends vote - quite democratically. Now it is possible that the data strategist stands all alone and is outvoted. This is how the prediction of k-NN works.
K-NN is an algorithm for clustering data. The goal is to assign a value that is not known to a certain category. This is done quite democratically: for example, all data points are displayed on a two-dimensional surface. The data are already divided into categories. But now I want to know to which category a new data point belongs. This is where the k comes into play. The data point is displayed on the surface and the categories of the k nearest neighbours are considered. Then a vote is taken: The most neighbours with the same category win.
K-NN can be used in the real world especially well for detecting outliers. This helps both in the financial industry to combat credit card fraud and in the monitoring of computer systems or sensor networks. Further down the line, k-NN can be used to pre-process and clean data if further ML algorithms are subsequently to be applied to a data set.
Rank 4 - Boosting
Boosting algorithms hold some life lessons for data scientists. Boosting is a relatively generic algorithm that can be used in combination with various algorithms. A boosting algorithm constructs a single strong ML model from several weak ML models. But how?
Connected, even the weak become powerful.
Friedrich Schiller in William Tell
We learn early in life that we are stronger and smarter together than alone. Moving the heavy kitchen table is almost impossible alone, difficult with two and no problem at all with four. Boosting algorithms make use of precisely this concept. Different models are trained, which individually have a high error rate and poor prediction accuracy, but together have a much better one. Those who have followed Part 1 of our ML algorithms series may have had a deja vu: Random Forests. But what is the difference?
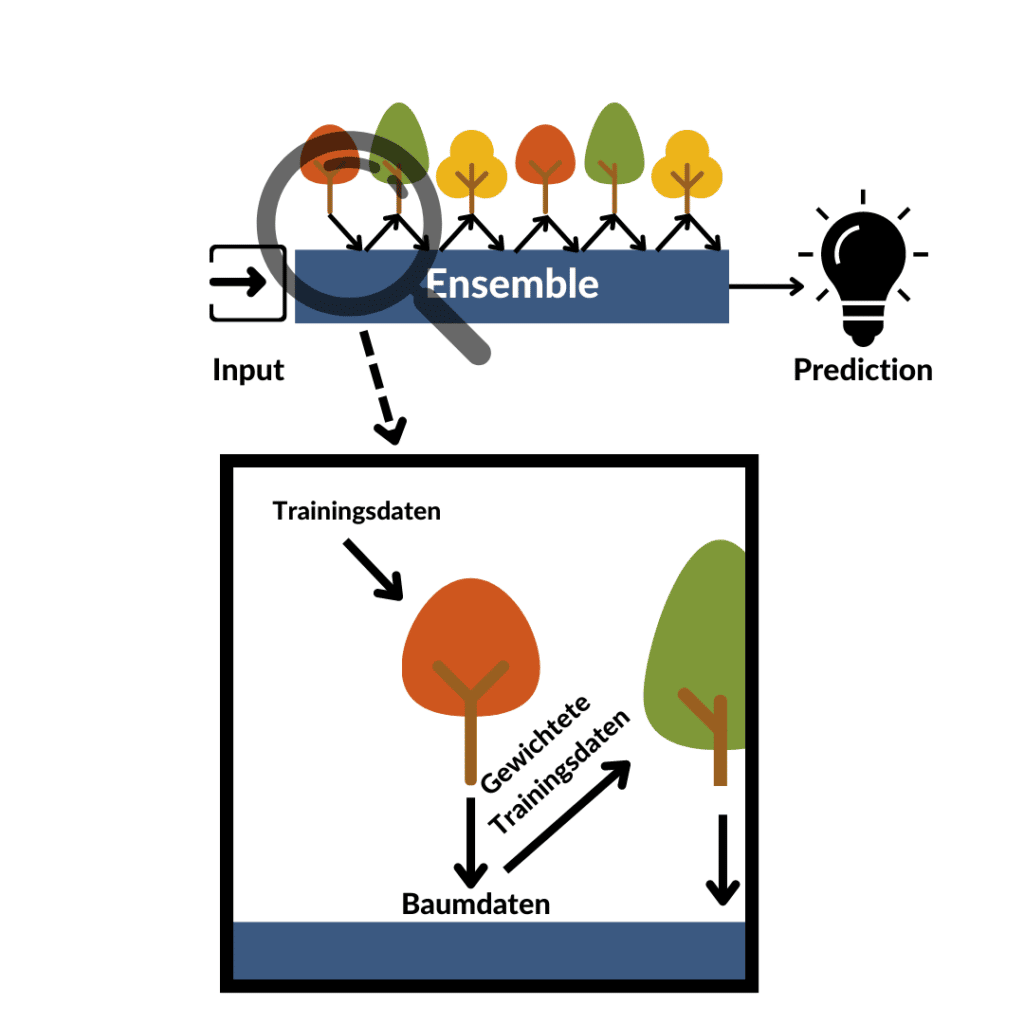
Boosting algorithms make use of another very well-known concept: learning from the weaknesses of others. If one of my classmates wrote the statistics exam before me and failed miserably at linear regression, he or she will advise me to focus on that. Of course, I now practice linear regression more before the exam, but the other exam topics are not ignored. That's how boosting works - learn from the past and use a whole ensemble of models to do so.
These two techniques are connected by iteration: The first model learns, is tested with regard to prediction accuracy and is stored. Weaknesses in the prediction of the model are identified, the associated data are weighted a little more and the next model is trained. All models are stored in an ensemble and thus make the prediction together at the end. There are different versions of boosting algorithms for determining the weakness or misclassified data points: AdaBoost uses the error rate for this, while Gradient Boosting uses the distance of the predicted point from the true value.
One implementation of boosting algorithms, for example, is the XGBoost-framework. Using regression trees, loss function minimisation through extreme gradient boosting, parallel processing and regularisation parameters, XGBoost is faster and more accurate than AdaBoost or Random Forest.
3rd place - Naive Bayes
Spam mails are annoying. Even more so if they do not end up in the spam folder but in the normal mailbox. In this way, they can sometimes cause a lot of damage and paralyse entire intranets. That is why we are now tackling this problem - with Naive Bayes.
The algorithm initially makes things easy for itself: To train an ML model with Naive Bayes, all the mails already present in the spam folder are first divided into words. The frequency of the existing words is then determined. For example: How often does the word "spam" occur in a spam mail? How often does the word "hello" appear in a normal mail?
The worst is now behind us. Now we can decide on the basis of a new mail whether it is likely to be spam or not. But how? With the help of the Bayes theorem! This states: how great the probability is that A occurs when B has already occurred. In other words, how likely is the email to be spam if it contains a certain word.
Anyone who has been reading carefully will have noticed that the word "spam" - which we counted before - is unlikely to be in a spam email. The probability of it being there is therefore 0. Anyone who listened carefully to probability theory at school knows that probabilities are multiplied by each other. 0 * 100% is still 0 ... what now?
To avoid this, we add an imaginary word to each word we have counted. This means that our word "spam" was not counted 0 times, but 1 time. In this way, Naive Bayes can be used to predict whether our email is spam or not.
A classic use case for Naive Bayes is document classification. A Naive Bayes Classifier can determine whether a document belongs to one category or the other. This also includes the identification of spam. Furthermore, language or text can be analysed for mood (are positive or negative emotions expressed here?). Naive Bayes is an alternative to many more complicated algorithms, especially when the amount of training data is comparatively small.
Place 2 - Support Vector Machines

Anyone who has ever been on a country road has almost certainly seen a tree there. Usually even several - a so-called forest. These trees have often been there longer than the road on which you are driving. But if they grow right next to the road, it can happen that roots get lost under the asphalt and cause annoying bumps or road damage. We want to prevent that. But how?
Rural roads often pass by or through forests. To connect two small villages, we want to build a road between a mixed forest and a coniferous forest. Support Vector Machines help us with this. In order to be able to drive on the asphalt for years to come and to preserve the peace of the forests, it is necessary to build the road as far away as possible from both forests. Support Vector Machines make exactly this possible: they determine a line that optimally separates two classes of data (mixed and fir forest). But what does optimal mean here?
Optimal means separating the two classes as far as possible. This has a very practical advantage: if one of the forests grows larger, the young foothills do not grow too close to the road and the asphalt remains free of road damage for years to come. This optimal dividing line is determined by vectors. It sounds mathematical, but it is not that complicated.
We introduce corridors to the right and left of the road that run parallel to the road. Then we widen them until they meet the next tree. Now it is possible that we have made a mistake in planning and could still widen the corridor if the road takes a different direction. To do this, we measure orthogonally the vector from the corridor to the second nearest point. If we can minimise this even further, there is a need for improvement. If the corridor is at 2 points, our road is optimally planned.
If a new tree sprouts from the ground (similar to a prediction), the corridor can be used to say quite precisely to which class the point or to which forest the tree belongs. The wider the corridor, the more promising the prediction.
In our example, we looked at a two-dimensional surface. However, Support Vector Machines can do the same even in a three-dimensional field. If the points do not lie next to each other in 2 classes, as here, but one is enclosed by the other, another dimension can be added with a transfer function. In this way the points can be subdivided again with a linear line.
Support vector machines are used in almost all areas: For face recognition, the boundary between background and body can be drawn, in handwriting recognition the algorithm serves for character recognition or helps to classify articles into different categories. The algorithm requires only short training times and is therefore more elegant and better suited for some problems than an artificial neural network, which is costly to train.
Rank 1 - Artificial Neural Networks
An artificial neural network is the "royal class" of ML algorithms. It requires a lot of computing power and sometimes has long training times. On the other hand, it can solve complex problems in almost all areas. For example, image and video recognition with ImageNet, NLP with GPT-3 (and soon OpenGPT-X), or image creation with DALL:E 2 are well-known tasks that are mastered with artificial neural networks. The catch is that artificial neural networks are incredibly complicated to understand.
The model of artificial neural networks is the human brain. Therefore, the functional principles of these two systems are similar. But since we are (unfortunately) not neuroscientists, this metaphor does not really bring us any closer to understanding artificial neural networks. So a more realistic example, the self-driving car.
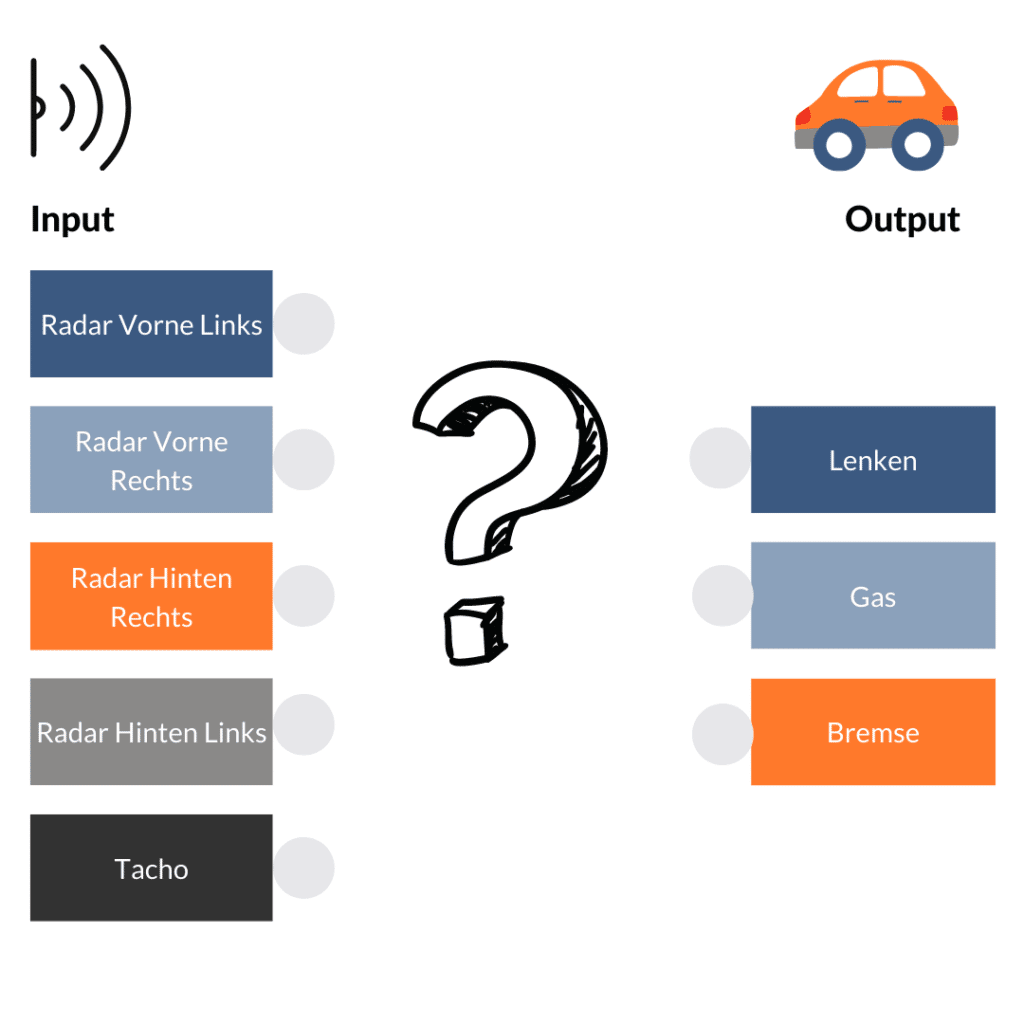
The cars developed today by various car manufacturers use various technologies such as cameras, LIDAR technology and proximity sensors. Of course, we all know how to drive a car, but an artificial neural network does not. So we use as inputs four radar sensors (front left/right, rear left/right) and measure the speed of the car. Our options for controlling the vehicle, i.e. the outputs, are limited to accelerator, brake and steering. And how do we wire the whole thing?
Quite simply: everything with everyone. Each input and each output represents a neuron. Unfortunately, this also means that a signal from the rear radar sensor would trigger the brake or a signal from the front radar would trigger the accelerator. So for the time being, our car will not get going. But now comes the clou and the reason why artificial neural networks are so difficult to see through. So far, our artificial neural network consists of 2 layers: Input and output. In between, however, we now insert a layer of additional neurons, a so-called "hidden layer". This is cross-connected with the input and output layer. It can add, invert, aggregate or even subtract the input signals through various computing operations. This changes the signal flow depending on the input. But can our car drive yet? Unfortunately, still not.
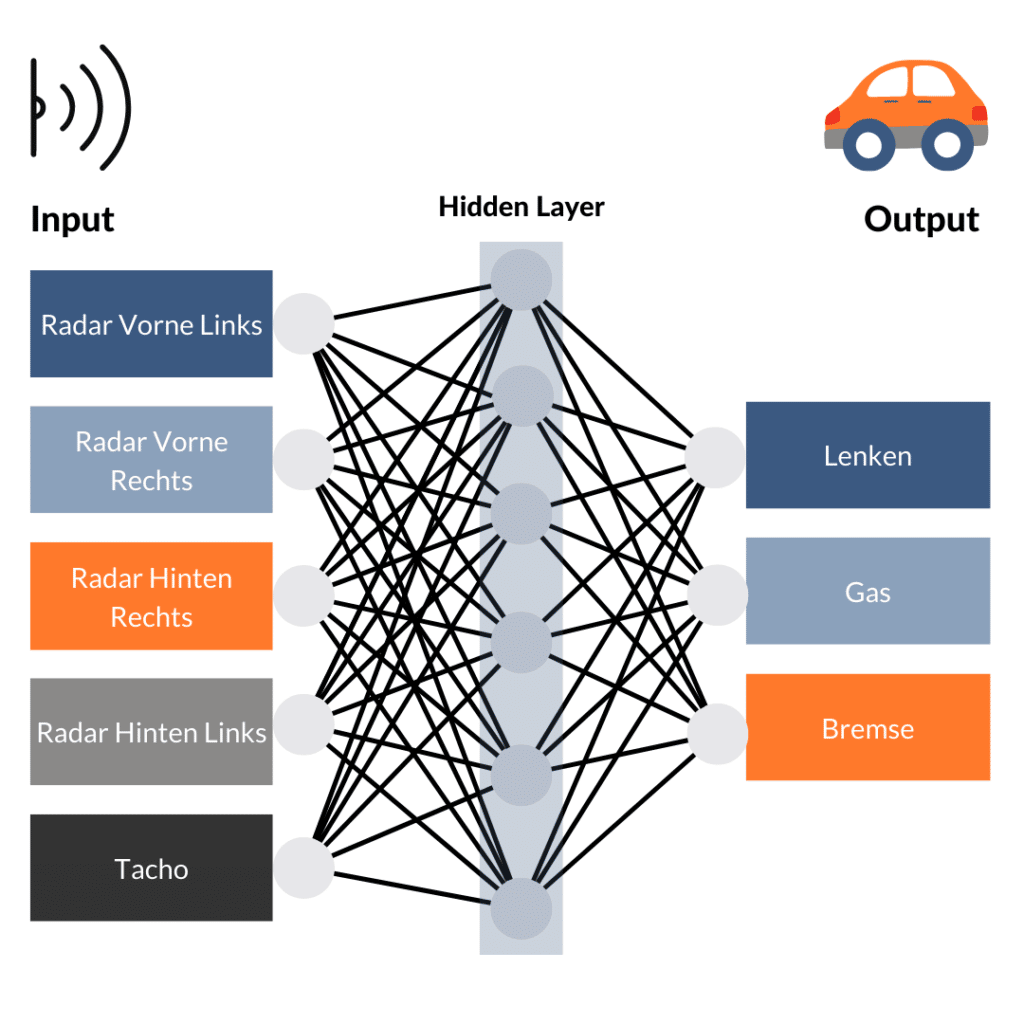
Now this model is trained. In this process, it tries to arrive at the correct output, i.e. the correct reaction, through trial and error with the given input. With the help of training data, the model is trained and finds out which connections lead to the correct result with a certain transformation in the "hidden layer". If the output is wrong, the functions of the neurons are changed and the model is trained again. Once it has reached a certain level of accuracy, it can be tested with unknown data and, if it passes, implemented in the self-driving car.
In reality, artificial neural networks have several layers. The input is also different: sometimes it is numbers, but also words or even pictures or videos. The output of complicated models such as DALL:E 2 is an entire image, i.e. a large number of individual values. Other models only recognise a handwritten number - i.e. exactly one output. But it is precisely this versatility that makes artificial neural networks stand out. They can solve a wide variety of problems in almost any industry, regardless of the type of data involved. Only the amount of training data and the available computing power must be relatively large in order to train effective artificial neural networks.
Artificial neural networks are used by almost all tech companies - such as Google, Facebook, Apple, Netflix, Amazon, Microsoft - and can be used for a wide variety of purposes: For generating user insights, text analysis, recommender systems, discovering medicines or even for groundbreaking scientific findings, such as the development of new technologies. AlphaFold From Deepmind.
Test neural networks yourself
These are our top 10 ML algorithms. If you missed Part I, read here and find out what else trees and machine learning have in common.









0 Kommentare