
The GPT-3 language model has impressively shown how AI understands our language and can write, analyse or summarise texts itself. Recently, text-to-image transformers have been making the headlines and showing in a powerful way what new AI models can do: Text-to-image transformers are able to create images from text that are frighteningly close to human-made artwork and photographs. How close? We've put together 2 images (see below) - one photo is real, one photo created by a text-to-image model like Midjourney or Stable Diffusion. So first a little quiz: Which of the two images is a real photo? The solution follows in the course of the article.


Do you need support with your Generative AI projects? From our Use Case Workshop to our executive training to the development and maintenance of GenAI products, Alexander Thamm GmbH offers its customers a wide range of services in the field of Generative AI. Find out more on our services page and contact us at any time for a no-obligation consultation:

By loading the video you accept YouTube's privacy policy.
Learn more
Inhaltsverzeichnis
From really realistic to completely bizarre
In January 2021, the US company brought OpenAI has developed a text-to-image transformer model of unprecedented quality: DALL:E. Based on the language model GPT-3 DALL:E can output an image by entering an instruction (called a prompt). The artificially created image is based on the elements requested in the instruction. The clou of the matter: It is not a kind of search engine that selects a suitable image from existing images, but a new, independent image that does not exist yet is created. What's more, it doesn't matter whether the object exists in reality - you can let your imagination run wild. For example, it is hard to imagine an armchair in the shape of an avocado. DALL:E already:

Initially, only images with quite low resolution and accuracy could be created. However, this has changed massively within the last one and a half years. Newer Transformer models from private companies such as OpenAI (DALL:E 2) or Google (Imagen), but also developer communities such as the merger between CompVis (Research group at LMU Munich), Stability.ai and LAION or research laboratories such as Midjourney can do more: they generate photos that are hardly distinguishable from reality, generate breathtaking works of art or bring totally different and unrealistic situations together in one picture.
Stable Diffusion by Stabilty.ai, released in August 2022, is open source, uncensored and can be used by anyone. Depending on the available computing power, it can be used to generate interesting images and, with a little experimentation, create fantastic fantasy worlds as well as hyper-realistic photos. But how?


Text-to-image transformers work with the help of so-called prompts. The task is to describe the image you want to create as precisely as possible, including the characters depicted, the art style, the camera used to "shoot" the image and the artist. Stable Diffusion recognises well-known film characters, celebrities, fantasy characters and brands - in other words, almost everything of which there are pictures on the Internet.
What's behind it?
Such models are created with a huge data set of images and their textual descriptions. With the help of NLP (Natural Language Processing), the descriptions of the images are interpreted and assigned to the images. In the case of Stable Diffusion, these images come from the LAION-5B database, a collection of 5.85 billion images with textual descriptions.
Training the models using these images can sometimes take a long time, depending on the hardware on which it runs. The first version of Stable Diffusion was run on an Ultracluster with 4,000 A100 GPUs trained. A certain level of hardware is also necessary to use the model: According to Stability.ai, anyone who wants to try out Stable Diffusion locally should have at least 10GB of VRAM available in their graphics card (in our tests, it even works with only 6GB on a GTX2060). Stable Diffusion is designed to work on your own home computer and not only in data centres and on GPU clusters.
Is this art or who is right?
The possible areas of application for Stable Diffusion, Midjourney & Co. are manifold, because: The prompt is subject to the copyright of the "inventor" depending on its length and complexity, but the images are not. According to the U.S. Copyright Office the image right cannot be transferred to an AI-generated artwork because it has no human author or creator. Therefore, at least as things stand, they can be used for any purpose.
The models are already popular in the art scene and many users use them creatively. With pictures, fantasy worlds, comics and the like, anyone can create very individual works of art. On the Colorado State Fair Art Competition the artist Jason Allen was even able to convince the jury with his artwork "Théâtre D'opéra Spatia" generated via Midjourney, promptly winning first place with his AI creation and causing a sensation in the art scene and beyond.

The models can also be used creatively for illustrations: Using Img-to-Img functions, existing images can be edited, elements that were not there before can be inserted or disturbing elements can be deleted.
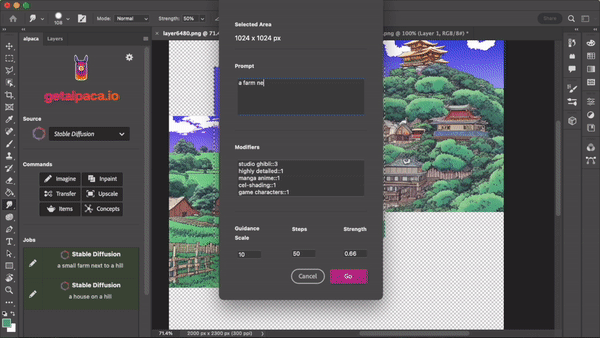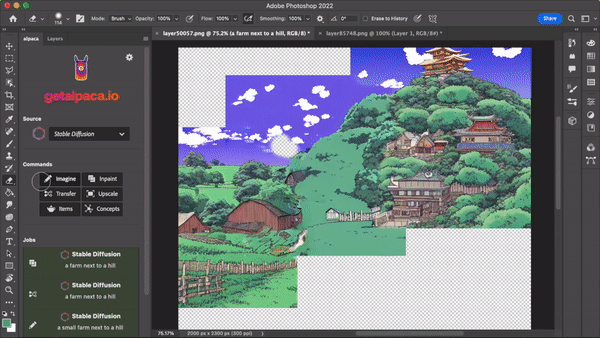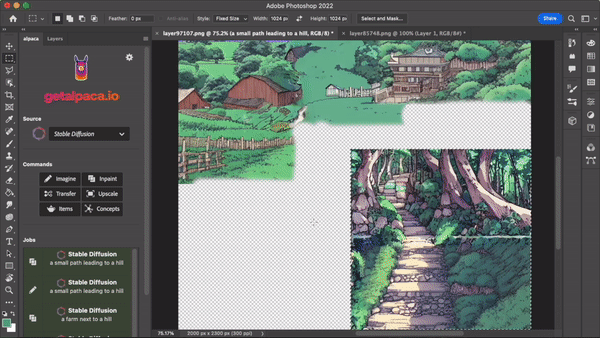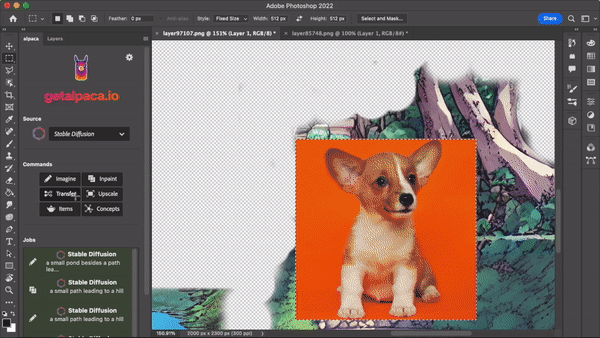
Stable Diffusion & Co. can be used, for example, in product design, interior design, logos or illustrations for editing or collecting inspiration. The possible areas of application are manifold and have not yet been exhausted.
But what can the models really do? After we have already shown some examples here, here is the solution to the quiz above. The correct answer: Both images were generated by an AI - one by Midjourney, the other by Stable Diffusion. After upscaling and colour correction, the images now look deceptively real. The interesting thing is that the two people in the pictures do not exist, they were merely created by the two models after inputting the prompt.
How do you become an AI artist?
If you want to test Stable Diffusion or Midjourney (the two models that can be used "for free") yourself, you can do so completely without any programming experience. In the meantime, there are freely downloadable applications - and because Stable Diffusion is open-source, you can even let off steam here with some Python programming experience on the model itself (available via HuggingFace). However, if you do not have a GPU cluster in your house, it is better to choose the following options:

Midjourney The easiest way to do this is via the Website use. Here you can join the official Discord channel and try out for free whether you are a "prompt artist". There is also the option of upscaling the images. Upscaling artificially increases the resolution of the images using AI.
Stable diffusion is also easiest to use via their official platform. With the beta of the web app Dreamstudio you can write your own prompts online and have Stable Diffusion create interesting images from them. However, the native images of the model are available in a resolution of 512×512. The resolution can be artificially increased here - but this also increases the number of tokens needed to create them.

AI, quo vadis?
As the first open-source text-to-image model, Stable Diffusion has not been on the market long (22 August 2022). Nevertheless, the first applications, integrations and apps are rapidly developing for use - and the trend is rising rapidly. Theoretically, it is also possible to train others on the basis of such models, for example to read out speech or generate music.
It is important to remember that videos consist of several frames per second. With the help of adequate computing power, upscaling and the combination of text-to-image and image-to-image models, animations or videos can be created, for example here shown.


And what does AI have to say about it? We asked Midjourney what the future looks like: What these pictures are supposed to tell us, we don't quite know ourselves yet - but maybe soon. 😉









0 Kommentare