Reinforcement Learning: Algorithms in the Brain
- Published:
- Author: Dr. Luca Bruder, Dr. Philipp Schwartenbeck
- Category: Deep Dive
Table of Contents

Our blog articles usually focus on business use cases and the analysis of business data. However, in this article, we would like to take a different approach. We will discuss how methods we use to solve business problems have provided insights into the field of neuroscience and the functioning of biological brains over the last century. The fields of artificial and biological intelligence have developed in parallel and have strongly influenced each other. Here, we will focus on reinforcement learning (RL) – a great example of how research into the functioning of biological systems on the one hand and research in statistics and computer science on the other can cross-fertilize to develop novel insights.
RL is originally a theory of learning that has been known in psychology for a long time. The underlying idea is that actions that are reinforced by rewards are likely to be repeated, while actions that do not lead to rewards or even punishment become less and less frequent (Figure 1). Sutton and Barto formalized the mathematical basis of this “reinforcement learning” and thus established a new branch of artificial intelligence (Sutton, R. S., & Barto, A. G. (1999). Reinforcement learning: An introduction. MIT press), which forms the basis for all the sophisticated algorithms that beat today's chess and Go world champions. Neuroscientists, in turn, use these mathematical formulations to study different brain regions and identify the parts of our brain that are responsible for reward-based learning. Decades of research suggest that RL, as formalized by Sutton, Barto, and colleagues, may be one of the central mechanisms by which humans and other animals learn.

Reinforcement learning in algorithms and biological brains
The basic concept of reinforcement learning is to improve behavior through trial and error. In this process, agents learn a so-called “value” V(t) of a state (or a state-action pair) at a given time t, which tells the agent how much reward it can expect for different options (e.g., how much would I like it if I ordered chocolate or vanilla ice cream). The key trick is to learn this value iteratively (I just ordered chocolate ice cream – how much did I like it?). To understand this, we can look at the mathematical formulation of one of the most central equations in RL, namely the iterative learning of the “value function” V(t):
V(t+1) = V(t) + α ⋅ (Reward-V(t))
This equation assumes that the value of the next time step V(t+1), which formally reflects the expectation of future rewards (how much pleasure do I expect if I choose chocolate ice cream now?), by updating the current value expectation V(t) by the difference between the reward received and the current expectation of what the reward should be (Reward-V(t)). This difference is often referred to as the Reward Prediction Error (RPE). The strength of the update based on the RPE is determined by a so-called learning rate (????, alpha). ???? essentially determines how strongly the reward received changes the expectation of future rewards. You can find a more detailed description in our blog article on basic RL terminology.
To establish the connection between RL and the brain, we need to take a brief detour into anatomy. The human brain is divided into the neocortex and the subcortical areas (Figure 2). The neocortex is a large, folded area on the outside of the brain and is the structure that is often imagined when talking about the brain as a whole. It consists of several different areas named according to their position in relation to the human skull. Of particular importance to us is the frontal lobe, which contains the prefrontal cortex, which forms the front part of the brain. Among many other important functions, such as language and executive control, it is thought to play a crucial role in representing important RL variables, such as the value we assign to objects and other rewards. Subcortical areas, on the other hand, are located deep within the brain. The most important area we would like to highlight here is a collection of neural structures called the basal ganglia. These structures play an important role in movement control, decision-making, and reward learning. Another important concept is that of neurotransmitters.
Neurotransmitters control communication between different parts of the brain (more precisely, communication between its subunits, the synapses between individual neurons). There are different types of neurotransmitters, which are believed to control different neural processes. The most important neurotransmitter that controls the interaction between the regions in the basal ganglia and the prefrontal cortex is dopamine, which is also considered the most important neurotransmitter for RL in the brain.

Dopamine has many functions in the brain, but here we will focus on its role in reward learning (Figure 3A). How does this work? Contrary to popular belief, dopamine release is not a pleasure or reward signal in itself, but rather a way of encoding the difference between expected and actual reward, i.e., our reward prediction error defined above . In other words, the brain releases a large amount of dopamine in response to an unexpected/surprising reward, and dopamine release is dampened when the expected reward does not occur. A fully expected reward, on the other hand, does not alter the dopaminergic firing pattern. The discovery of the close relationship between dopaminergic firing patterns and RPEs is one of the most significant neuroscientific findings of the last decades (Schultz, Dayan, & Montague, Science 1997).
Impact of RL Algorithms in Neuroscience and Beyond
Since its discovery, much work has been put into developing experiments to uncover the dynamics of reinforcement learning in humans and other animals. RL experiments in neuroscience tend to differ somewhat from what data scientists do with RL models in business use cases. In data science, we create a simulation (“digital twin”) in which an agent learns how to optimize a specific task, such as controlling traffic lights or minimizing energy costs. The agents learn to take optimal actions to maximize rewards. In this way, we hope to create an agent that can perform and solve the task autonomously by optimizing its behavior to obtain the best possible rewards. In contrast, researchers in neuroscience ask (biological) participants to solve specific learning tasks and analyze how various manipulations affect their (reinforcement) learning behavior. To do this, agents for reinforcement learning are trained to mimic the behavior observed in the real participants of the experiment. Based on these trained agents, researchers can describe the behavior in mathematical terms by comparing the actions of the participants with the actions of the trained RL agents.
A very simple example of such an experiment is the bandit task (Figure 3B). In this task, participants must optimize their actions by selecting the best possible bandit. Each action has a certain probability of receiving a certain reward. The probabilities are not communicated to the participants but must be learned from experience by trying out the various options and observing the results. Often, the probability of receiving a certain reward for each action (= choosing a certain option) changes over the course of the experiment. This leads to a dynamic environment in which participants must keep track of the current state of each action. By using the above RL formulation and optimizing the parameter α for each participant, we can estimate how efficiently individual participants update their reward expectations and how this influences their behavior.
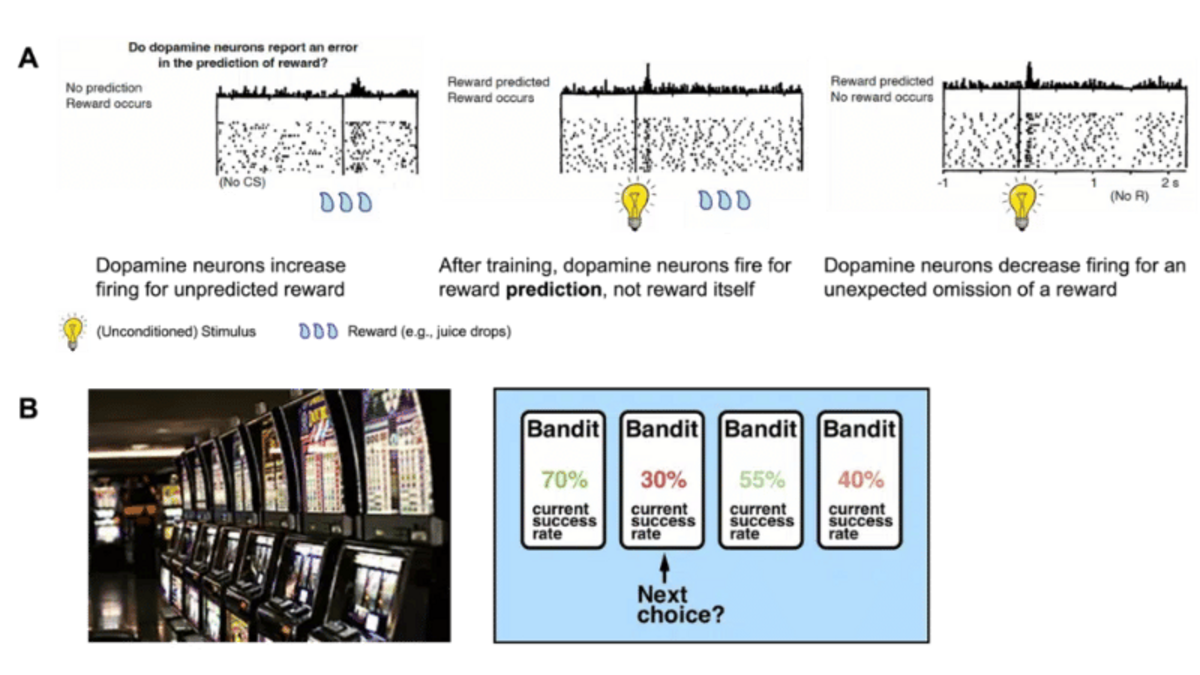
Studies with this and similar designs have shown a number of clinically important results. These results may help improve diagnosis and bridge the gap to new treatments for mental disorders by identifying the mechanisms behind clinically abnormal behavior. For example, it has been suggested that clinical disorders such as depression may be related to differences in learning from positive and negative feedback (Chong Chen, … & Ichiro Kusumi, Neuroscience and Biobehavioral Reviews 2015; Reinen, …, & Schneier, European Neuropsychopharmacology 2021). Imagine that you have not just one learning rate (α in the example above), but two, one for learning from positive feedback and one for negative feedback. What happens if they are not equal, but your “positive” learning rate is lower than the “negative” one? This leads you to update your knowledge of the world much more on the basis of negative feedback, resulting in a negatively biased representation of your environment. A second example relates to the representation of values themselves. In reinforcement learning, it is not only important to learn from experience, but also to accurately represent the values of the options themselves (V(t) in the example above).
This was another important focus of research on individual differences and clinical symptoms. This individual sensitivity to value differences determines how much you actually care about whether one option is better than another. Let's say you've learned that you really like bananas and apples not so much. If these preference differences are very important to you, you will always choose bananas and ignore apples. If you are less sensitive to your preferences, you will choose both fruits more or less equally. What sounds like an artificial example is a central aspect of how artificial and biological agents navigate the world: if they are not sensitive enough to what they consider good or bad in the world, they will behave too arbitrarily, but if they are too sensitive to their preferences, they will always stick to one option and be unable to explore other alternatives or recognize changes in the world, such as a sudden improvement in the quality of apples (see the description of the changing bandits above).
This problem is at the heart of the so-called exploration-exploitation trade-off, which is central to reinforcement learning: How much should agents rely on their knowledge to choose the best option (exploit), and how much should they try new options to learn more about the changing world (explore)? It will come as no surprise to hear that both individual learning and resolving the exploration-exploitation trade-off are associated with dopaminergic function (Chakroun, …, & Peters, 2020 eLife; Cremer, …, Schwabe, Neuropsychopharamcology 2022), which is also an important focus of clinical neuroscience (Foley, Psychiatry and Preclinical Psychiatric Studies 2019; Iglesias, …, & Stephan, WIREs Cognitive Science 2016).
Current connections between AI and neuroscience
The bidirectional flow of information between artificial intelligence and neuroscience research continues to be fruitful (Hassabis, …, & Botvinick, Neuron 2017; Botvinick, …, & Kurth-Nelson, Neuron 2020). For example, it has been shown that the idea of storing experiences in a replay buffer and “reliving” them to increase an agent's RL training data can significantly improve the efficiency of reinforcement learning algorithms in AI (Schaul, ..., & Silver, arXiv 2015; Sutton, Machine Learning Proceedings 1990). Recent work has also shown that these algorithms bear striking similarities to the neural repetition found in the hippocampus, a central brain region for memory formation and navigation in the biological brain (Roscow, …, Lepora, Trends in Neurosciences 2021; Ambrose, … Foster, Neuron 2016).
Much research also focuses on the exact nature of the learning signal found in dopaminergic neurons. The key signature, a gradual shift of learning signals moving backward in time, has been both supported (Amo, …, Uchida, Nature Neuroscience 2022) and questioned (Jefong, …, Namboodiri, Science 2022; “A decades-old model of animal (and human) learning is under fire”, Economist 2023). Such biological insights are crucial for the development of resource-efficient algorithms for reinforcement learning in artificial intelligence.
Another exciting piece of work suggests that dopaminergic learning signals may not reflect the updating of individual numbers, but rather the learning of the entire distribution of possible rewards and their respective probabilities (Bakermans, Muller, Behrens, Current Biology 2020,Dabney, Kurth-Nelson, …, Botvinick, Nature 2020). This has important biological and algorithmic implications. Algorithmically, this means that reinforcement learning approximates not only the expected value of a reward, but its entire distribution, providing a much richer representation of the environment and thus significantly accelerating learning and action control. Biologically speaking, an animal on the verge of starvation needs to know where to find enough food to survive, even if this option is less likely than a safer alternative that does not provide enough food. This and similar work provide important insights into the nature of resource-efficient yet powerful reinforcement learning algorithms and, thus, into the nature of artificial and biological intelligence itself.
Conclusion
In summary, the flow of knowledge between neuroscience and theoretical RL approaches over the last century has provided significant insights into the principles of both biological and artificial intelligence.
Reinforcement learning is a key aspect of modern applications of artificial intelligence, ranging from solving challenging control problems to the success story of large language models, but it is deeply rooted in biological science. The development of increasingly powerful algorithms is leading to new insights into how our brains understand the world, and insights into biological intelligence are leading to more efficient and influential algorithms for reinforcement learning in business contexts.
Share this post: