
Recent machine learning models, such as those used in ChatGPT, have caused a sensation due to their amazing results. In general, large language models (LLMs) are having an increasing impact on daily work and are used in a variety of different fields of activity. The improved results in terms of quality of answers is, besides the Transformer Model introduced in 2017 (source: Attention is all you need) can be attributed in particular to the use of Reinforcement Learning from Human Feedback (RLHF). This article therefore deals with RLHF in the field of large language models. This technique is used here for improved fine-tuning of large language models. The mathematical background of reinforcement learning training processes is deliberately omitted at this point, as this information can be found in detail in our article "Reinforcement Framework and Application Examples" can be found.
Inhaltsverzeichnis
Large Language Models (LLMs)An introduction
LLMs are not new and have been used in a wide variety of applications for quite some time. Speech assistance systems such as Alexa and Siri make use of them, search entries on Google are processed using them and, at the latest since ChatGPT, their regular use has become widespread in society. But what is behind large-scale speech models and why are they receiving so much attention now, when they have been in use for a long time?
LLMs are large neural networks trained to understand and generate human speech (e.g. GPT-4, LaMDA, LLaMA etc.). These models can be used for various applications such as speech recognition, translation, summarisation and chatbots, making life easier in many work but also private areas.
In order for LLMs to develop a "language understanding", they need to be trained on a large amount of textual content. Usually, this textual data is collected by so-called scraping of internet content. Scraping involves an automated programme visiting a large number of web pages and extracting all the text. During the training phase, the language models learn to recognise contextual relationships within the text data and map these into a complex probabilistic model. Put simply, during the training phase, the language models learn to predict which word in a sequence is most likely to come next:
Training process visualised
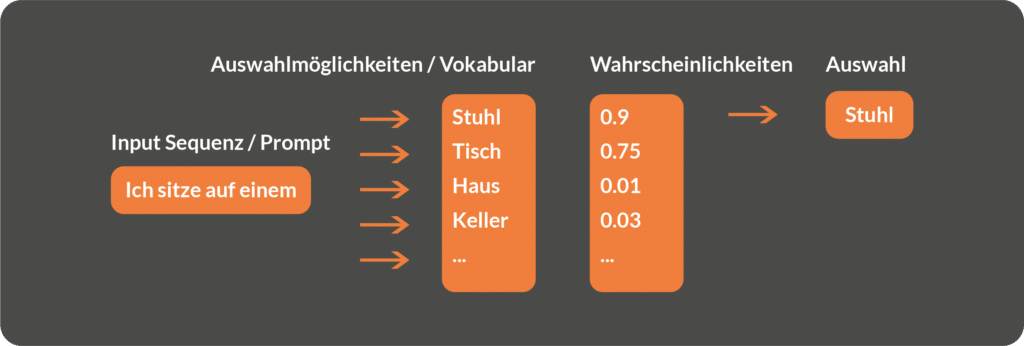
Iteration 2:
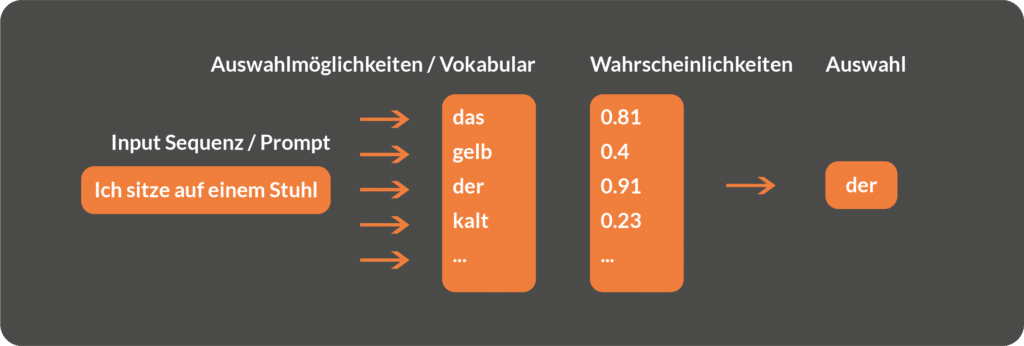
Iteration 3

However, training on unfiltered internet content and without controlling the text output bears the risk that the model learns to reproduce false information (fake news), malicious content or prejudices (biases). To reduce the risk of language models adopting this negative content and reproducing it when generating the text output, various procedures are used during the training process. On the one hand, pre-processing steps are applied to filter out undesirable passages from the text content on a rule-based basis, and on the other hand, additional machine learning models are trained with the help of human feedback, which in combination with the language model are intended to minimise the risk of producing malicious content. Furthermore, this multi-stage training process offers the possibility to better match the outputs of the language model to the instructions and intentions of the human input. A central component of this training process is the so-called "Reinforcement Learning from Human Feedback (RLHF)", which is discussed in more detail in the following section.

For an in-depth technical introduction to reinforcement learning that gives you a basic understanding of reinforcement learning (RL) using a practical example, see our blog post:
Reinforcement Learning from Human Feedback (RLHF)
In order to better control the training process and the output of large language models, reinforcement learning from human feedback is used in many cases during the training process. Here, in addition to the automated learning of language patterns based on text data, human feedback is included in the learning process. The idea behind RLHF is that a human gives feedback to the language model by telling it whether what the model has generated matches the instruction or the intention behind the input and does not contain any unwanted content. With the help of this feedback, the language model can continuously improve the output during the learning process.
The technical process of Reinforcement Learning from Human Feedback consists of a total of three building blocks:
1. Supervised Finetuning
The first step is supervised fine-tuning, where the technique of supervised machine learning is used to optimise the model. Supervised machine learning is an approach in the field of machine learning in which an algorithm learns from a training data set to make predictions or decisions for new, unknown data.
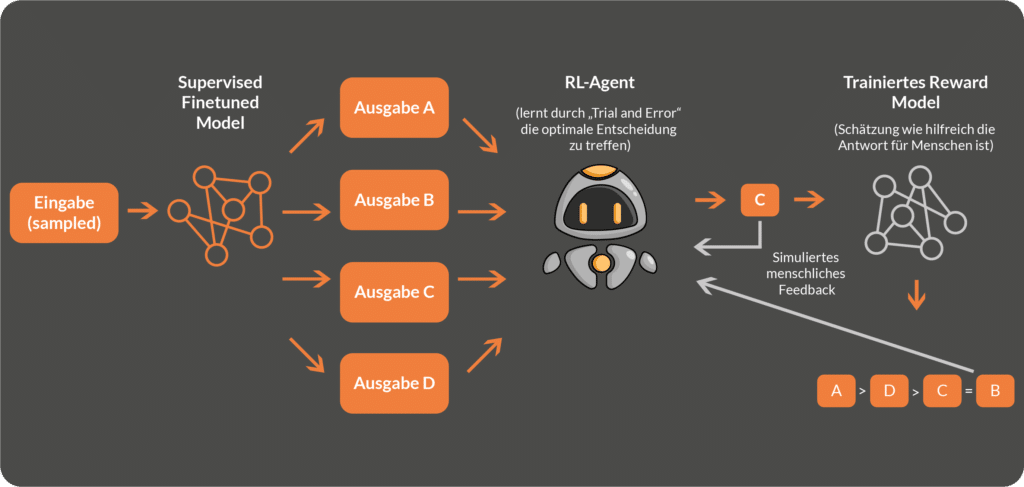
In the Supervised Finetuning step of Reinforcement Learning from Human Feedback, the input consists of a randomly selected text input, e.g. "What is Reinforcement Learning from Human Feedback? The language model generates an output based on this input, e.g. "Reinforcement Learning from Human Feedback is a subset of machine learning". At the same time, a human person writes an "optimal" response (label) to the same input, i.e. a response that the human person would have wanted to the given input. Then the model-generated response and the human-generated response are compared and the difference (the error) is used to adjust the model parameters. The adjustment of the model parameters is done automatically by means of backpropagation, whereby the model learns to generate responses that closely resemble the "optimal" human responses.
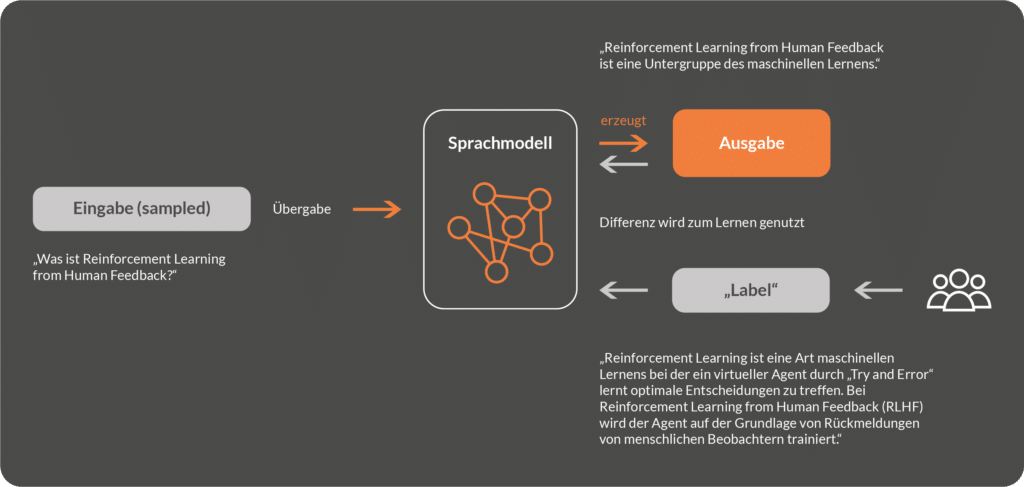
Once the desired match between human-generated - and model-generated responses exists, or the error between input and output has been minimised, the supervised finetuned model is used to train a so-called reward model.
2. training of a reward model
In the second step of reinforcement learning from human feedback, a so-called reward model is trained. As in Supervised Finetuning, human feedback is used to further optimise the text output. To do this, a (new) text input is selected and passed to the language model optimised in step 1. This then generates a number of outputs that differ from each other to a certain degree - a so-called candidate set. Analogous to step 1, this candidate set is evaluated or ranked by humans. At the same time, a new neural network, the "reward model", is created with the aim of calculating a ranking score for each of the text output candidates that comes as close as possible to the human assessment.
Training of the reward model is done by increasingly minimising the difference between the ranking score of the reward model and the human ranking.
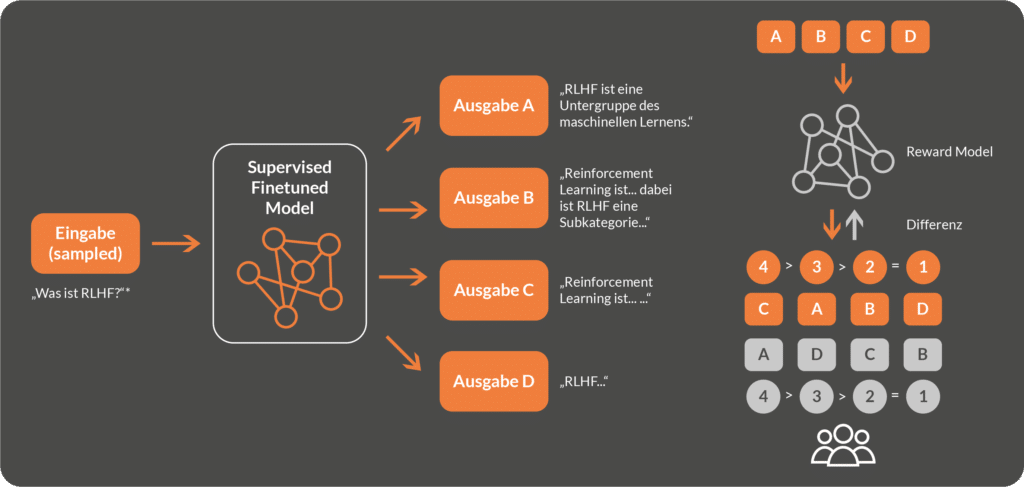
At the end of the training phase, the Reward Model has learned to evaluate the responses generated by the language model and assign a ranking score. The human feedback in this case serves to help the reward model learn to approximate the usefulness of the responses to humans.
3. training of the reinforcement learning agent with proximal policy optimisation (PPO)
The reward model from step 2 generates a ranking from a set of answers generated by the optimised language model from step 1. Now, it could be assumed that the answer with the highest ranking will be issued as the final answer to the end user, but this is a fallacy, as such a static selection could lead to the following problems in practice:
- Lack of exploration: In reinforcement learning (RL), it is important to balance both the exploration of new strategies and the exploitation of known, good strategies. Simply selecting the answer with the highest ranking can lead to the agent getting stuck in a suboptimal solution without a chance to find better or innovative solutions. RL algorithms allow for some exploration to discover new strategies and further optimise the agent's performance (see RL terminology article).
- Uncertainty of the Reward Model: The reward model can be inaccurate or incomplete, especially if it is based on human feedback, which can be subjective and inconsistent. By using an RL approach such as PPO, the agent can not only learn based on the current reward estimate, but also consider how its policy (see RL terminology article) should adjust over time to account for potential uncertainties in the reward estimates.
- Stochastic environments: In many real-world situations, the environments in which the agent operates are stochastic and unpredictable. In such cases, simply selecting the highest ranking answer may lead to less than optimal results. An RL approach such as PPO can help the agent to better respond to environmental uncertainties and adapt its strategy accordingly.
- Long-term optimisation: The goal of reinforcement learning is to maximise cumulative reward over time, not just to consider immediate reward. Simply selecting the highest ranking answer focuses on the immediate reward and may ignore long-term effects and optimal strategies. In other words, long-term optimisation considers answers that deliver more value to the user over the course of the dialogue with, for example, ChatGPT. RL approaches such as PPO aim to consider long-term decision making and optimal strategies to improve the agent's overall performance in the dialogue.
- Learning and adapting: In many cases, the environment or the problem changes over time. For example, when using ChatGPT, new facts are supplied to the model as additional context during the conversation, or the user:in wants to change the tone of the text output. By using an RL approach, the agent can learn from its experience and adapt its strategy to new situations. Simply selecting the highest ranking answer may not provide such adaptability and learning.

For a compact introduction to the definition and terminology behind reinforcement learning, read our basic article on the methodology:
Therefore, after the training of the reward model, a further, third training step in reinforcement learning from human feedback is carried out in which a reinforcement learning agent learns to make the best possible decision in each (conversational) situation with the help of proximal policy optimisation (PPO). This step is intended to minimise the problems mentioned above. Proximal Policy Optimisation (PPO) is a modern method in the field of reinforcement learning that aims to improve the training stability and performance of policy gradient approaches. PPO optimises the agent's so-called policy or action plan to maximise the expected cumulative reward. PPO has proven effective in many RL tasks and is known for its robustness and good performance in a wide range of applications. Detailed information on how RL agents work can be found in the article linked here: RL Terminology article.
The connection between the Reward model and the PPO model in Reinforcement Learning from Human Feedback is that the Reward model is used to provide feedback to the agent about the quality of its actions, while the PPO algorithm uses this feedback to efficiently update the agent's policy. The main goal of this collaboration is to get the agent to make human-like decisions (approximated by the Reward Model) when solving complex tasks or operating in environments where the optimal solution is not readily available. By combining human feedback with effective RL algorithms such as PPO, the agent can benefit from human expertise and extend its learning ability to tackle more challenging problems and better adapt to different situations.
It should be noted that the type of reinforcement learning from human feedback described here is one of several ways to integrate RLFH into model training. For example, it is also possible to use the LLM itself as a reinforcement learning agent and thus improve the responses not only by selecting from n candidates, but directly generating the LLMs by learning from rewards.
Overall, using a reinforcement learning approach with PPO instead of simply selecting the answer with the highest ranking of the reward model can help the agent to better respond to uncertainties, environmental changes and long-term effects, and allows for better exploration and adaptation to new situations. Although a simple selection of the highest ranked answer may be sufficient in some scenarios, reinforcement learning methods generally provide a more flexible and powerful solution for complex problems and dynamic environments.

Deepen your understanding of the concept of the "Deadly Triad" in reinforcement learning, its implications and approaches. This Deep Dive provides you with an overview of RL concepts, introduction of the "Deadly Triad" and its coping strategies.
Conclusion
Reinforcement Learning from Human Feedback is an approach that on the one hand minimises the risk of misinformation and at the same time increases the quality of responses from large-scale language models by influencing the training process with human feedback. By combining human knowledge and effective RL algorithms such as PPO, agents can master complex tasks and achieve or even surpass human-like performance.
The use of human feedback in the reward model allows the agent to benefit from the intuition and experience of real people, while ensuring the agent's ability to adapt and learn through reinforcement learning. This approach helps to improve the exploration and exploitation of strategies, adaptation to environmental uncertainties and consideration of long-term effects, leading to better performance overall.
Overall, Reinforcement Learning from Human Feedback offers a way to further develop artificial intelligence and apply it to a wide range of applications and challenges. This approach opens up new avenues for collaboration between humans and machines and enables the boundaries of AI to be pushed and innovative solutions to complex problems to be developed.









0 Kommentare