
From time to time, a new software system appears on the horizon of the technology landscape. In this paper we look at such a new data access and processing layer: the feature store. It will play an important role in the construction of intelligent systems based on machine learning (ML) algorithms.
But does the increasingly heavy technology toolbox of data engineers need yet another tool? Yes, because feature stores are great. They reduce the complexity of a system and thus shorten the deployment cycle of ML models. To find out why, we first need to define what a feature is, what the purpose of a feature store is and how it can help us achieve better results in ML projects. Ready? Let's go!

Inhaltsverzeichnis
What is a feature?
A feature is an independent, measurable variable that serves as input for training an ML model. Statisticians refer to a feature as statistical variable. For data engineers, on the other hand, a feature is an attribute in the Schema of a relational databaseIt can therefore be described as a single column of a data table.
Feature stores get their name from the feature vectors that are used as input to ML models. Depending on the ML model, there are different requirements for a feature vector. Random forests, for example, are fairly unrestricted and allow categorical data and non-standard numerical data, while neural networks, on the other hand, only work with standard numerical data.
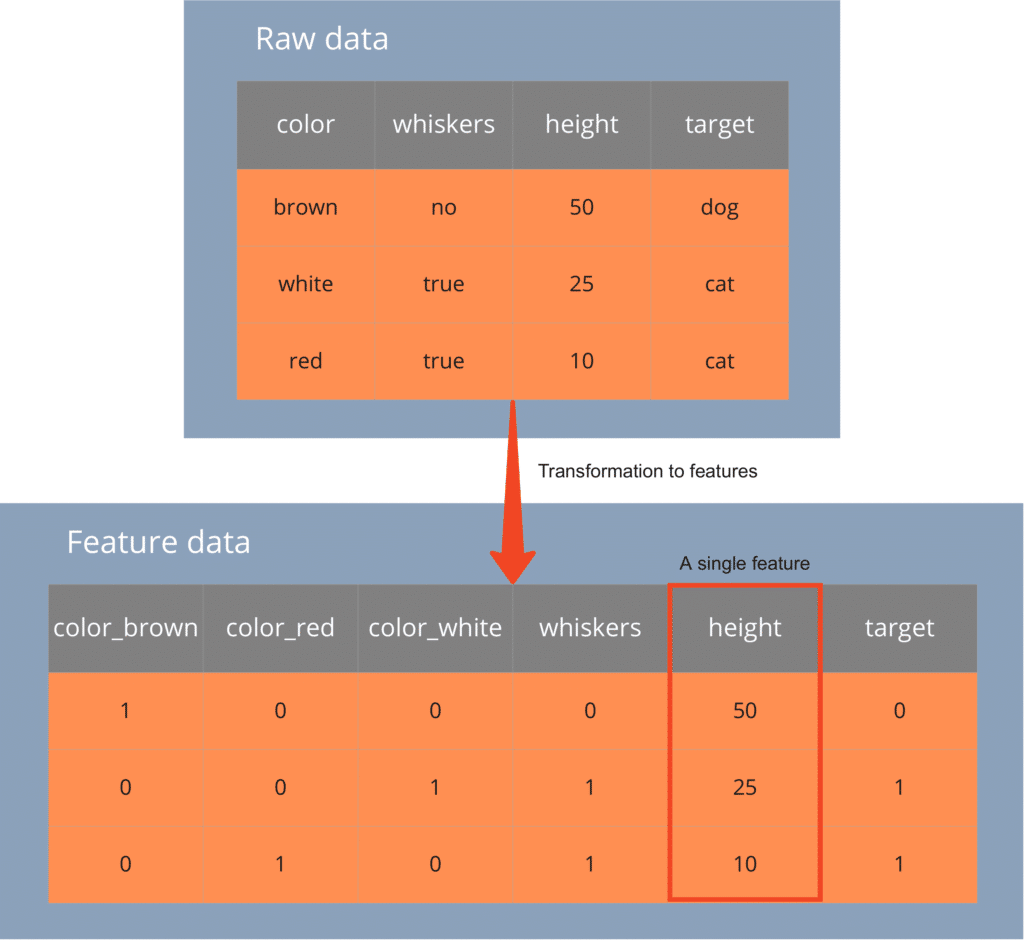
Example: The table above shows three attributes and one prediction attribute (column "target"). The hypothetical model we want to train requires numerical inputs to perform a supervised classification into the two values of the prediction attribute, Dog (dog) and Cat (cat)to be carried out. Therefore, we need to transform the categorical and Boolean attributes. The lower, transformed table contains the final features. On the initial attribute Colour we have a One-Hot-Coding and applied to the Boolean attribute Whiskers a binarisation.
The table below contains a single feature vector per row. Each entity, i.e. each individual "dog" or "cat", is associated with one row. Each individual feature, for example the Size (height), is represented by a column. This process of generating features is called feature engineering. The goal is to output features with a high information gain and combine features with minimal correlation. In this way, ML models can generalise predictions as well as possible while at the same time Errors of the first and second kind minimise. To get high quality features, an iterative approach is needed. Manually, this process is very tedious and can be inconsistent. This is where the Feature Store comes to the rescue.
Why do we need a Feature Store?
Feature stores take data timeliness to a new level, enabling more accurate models through access to more consistent data, helping to make more accurate predictions. Feature computation and storage enable the discovery, registration and use of consistent features across individual project boundaries.
Advocates of agile software development preach iterative approaches to meet or validate customer requirements faster. Iteration is enabled by automation. Small changes are made to the source code, then checked against another code to make sure the changes don't break anything. In an intelligent system, however, iteration is a big challenge because data experts - who are needed to design and build the system - speak different languages.
A Data Scientist receives an initial data dump, the raw data, and creates a model using a pre-processing pipeline in the context of the notebook. Then a data engineer operationalises this pipeline to account for the volume and velocity of the data. For this, data engineers use distributed data processing platforms such as Spark or Flink. Finally, an ML engineer integrates the model into an application, possibly rewriting the model to optimise interference time and reduce a model's computational requirements.
The process described and the different capabilities of the actors slow down the introduction of new models into a production environment. Even more serious are inconsistencies in the re-implementation of data transformations. Inconsistencies lead to bias in training and interference data - which is detrimental to a model's predictive results. It also isolates features that are generated in different projects - which in turn makes them difficult to discover. The MLOps movement aims to answer these problems in general. However, there is a tendency for MLOps to focus more on ML models and less on data and features. Therefore, there is a need for technology that supports the capabilities of different data experts and creates a common understanding of data pipelines.
Objectives of a feature store:
- Reduced friction between different roles (Data Scientist, Data Engineer, ML-Engineer)
- Easy findability of features between different projects
- Uniform naming and data types of features
- Preventing different distributions of features between training and inference
What is a Feature Store?
A feature store is a platform where all features are centralised and accessible to all so that they can be reused in different projects. The Feature Store is considered the "single source of truth" for all ML projects, enabling consistent discovery, computation and use of features.
Most feature stores have three common components: a transformation layer, a storage layer and a delivery layer. Depending on the requirements of a data application and the stakeholders involved in a project phase, the three components can often be used in a kind of batch or stream processing.
Feature stores aim to solve the full set of data management problems encountered when building and operating operational ML applications.
David Hershey (@tectonAI)
Transformation
The Coursera founder and ML expert Andrew Ng explained already 2013We know that feature engineering is a crucial step in the development of an intelligent system. Therefore, we need to approach the transformation step with increased attention. Several steps are required in the transformation of raw data into a feature:
First, the data from different data platforms must be integrated. Then, the quality must be ensured by including all steps that are associated with the Data Wrangling connected, are performed. Finally, the data tuples are prepared so that they can be used by an ML model. This last step involves transformations such as one-hot coding or standardising the range of values of a feature. In rare cases, it is even possible that the transformation itself uses a sophisticated ML model to generate features. An example of this is sentence embeddings obtained from natural language. This complex pipeline is applied to the raw historical data. However, exactly the same steps have to be performed to create the input feature vectors at inference time. The feature store thus serves as a "single source of truth" and ensures that the features for training and operation are generated by the exact same pipeline definitions. Pipelines for ML applications can thus be created iteratively by using the expertise of data scientists as well as data engineers.
Persistence
When storing features, there are two different scenarios that a feature store needs to support. In the first scenario, a feature store needs a backend for storing historical features. Historical features serve as training data for ML models. Usually, data warehouse systems are used for this task. Sometimes features are also stored directly in a data lake. In the second, features are created by streaming transformation and persisted in a key-value store. In both cases, the creation of the storage backend of a feature store should be managed by a data engineer.
Delivery
Similar to the previous components of a feature store, the Web API for feature delivery also supports a batch and a low-latency mode. The batch API is used by data scientists to obtain training data for models, and the low-latency API applies the transformation pipeline to a single datum (or multiple datums) so that it can be used by a downstream model.
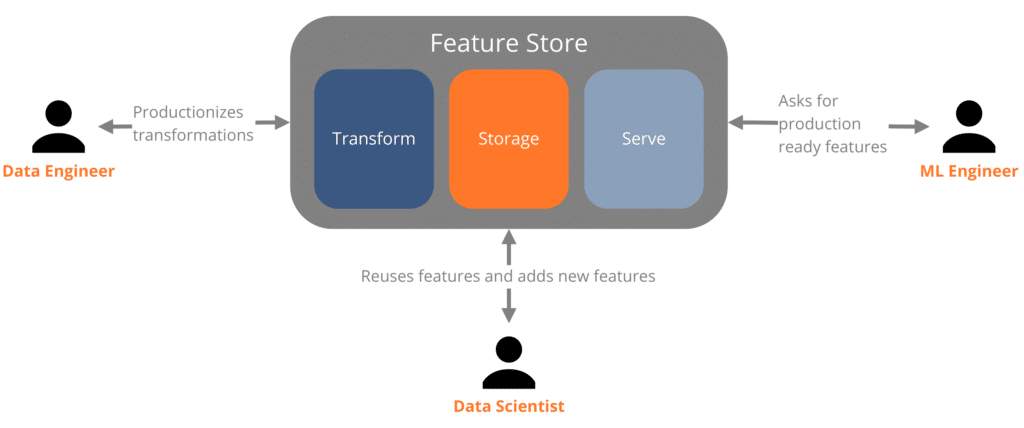
These are the three most common components of an archetypal feature store. There are other components such as a monitoring system for the APIs, the automatic detection of Concept Drifts as well as a metadata repository to make it easier to find features between projects. However, this still quite young technology is still very fluid, with the three core pieces (transformation, persistence and delivery) always being the foundations of a feature store.
Three feature stores

Tecton
Tecton is a hosted SaaS feature store aimed at companies working on AWS. One of the biggest users is Atlassian, the company behind Jira, Confluence and Trello. Atlassian reports that it has shortened the deployment of new features for ML models that were already in production from 1 to 3 months to a single day. Under the bonnet, Tecton is powered by Delta Lake, S3 and DynamoDB for storage and uses Spark for transformation. From an operational perspective, the delivery component runs on Tecton's cloud environment. The transformation and storage components are in the hands of the user (more information at DeployingTecton).
Feast
Feast is an open source feature store that can be deployed in any Kubernetes environment. Tecton is one of the key players in the development of Feast. The features of Feast are a subset of those of Tecton. The main difference is that Feast does not provide a central instance for feature transformations and therefore only stores pre-computed features. In addition, Tecton provides more monitoring functions, e.g. to detect shifts in the distributions of features. We recommend using Feast for a small proof-of-concept and then migrating to Tecton. Since the feature delivery APIs of both systems are very similar, the migration is quite simple.
Databricks Feature Store
The Databricks Feature Store is tightly integrated into the Databricks cloud-agnostic ecosystem and forms a sub-component of the Databricks Machine Learning Platform. Should a team already have experience with transformations in Spark, using the Databricks Feature Store is a breeze. In addition, features generated by the Databricks Feature Store can be used directly with MLFlow's model-serving capabilities. Internally, the Databricks Feature Store stores the features in a table with a version history, which is a Tracing the origin of data enables. However, compared to Tecton, the Databricks Feature Store lacks data quality monitoring features. Apart from this minor drawback, the Databricks Feature Store offers the best user experience among the three feature stores presented due to its tight integration with other Databricks services.
Conclusion
Those who want to promote more consistent pipelines, more discoverable and constant features, and iterative collaboration should consider implementing a feature store. A feature store consists of three components that support both batch and streaming processing and promote exploration and delivery of consistent features at multiple levels. Covering all the concepts and features of this (still) new technology would be something for a book rather than a blog post, yet the basic goal should be clear: Feature Stores enable the implementation and reuse of consistent features and promote iterative collaboration between different roles in the ML lifecycle. In the long run, the technology has the potential to fundamentally change the way we develop intelligent systems.








0 Kommentare