
Artificial intelligence and machine learning have long since ceased to be marginal phenomena and have become fully mainstream in recent years. While self-learning systems were a topic more or less limited to research institutions and technology companies just a few years ago, machine learning has now arrived in many everyday applications.
Speech recognition on mobile phones, translation programmes on the internet, spam filters for computers and facial recognition for photos and videos are just a few examples of technologies that are based on self-learning systems today.
But also in many industries, products and processes have long been redesigned and optimised using machine learning. These include, for example, the optimisation of supply chains, predictive maintenance, online marketing customised for customers or automated energy management. A special focus is on manufacturing companies, machine builders and companies that already rely on the networked production such as the automotive industry.
All industries that have large volumes of data are predestined for the use of machine-learning systems. These include in particular banks and insurance companies, the healthcare sector and manufacturing companies. Machine learning can be used in these and other industries to increase efficiency, better meet customer needs, make faster decisions and improve the bottom line.
Inhaltsverzeichnis
What is Machine Learning?
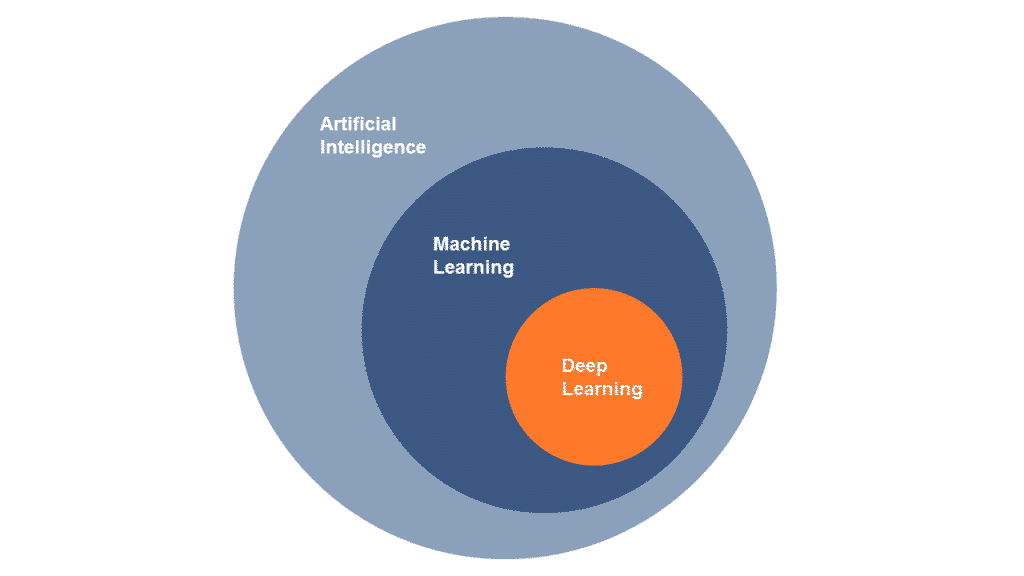
Machine learning is a sub-area of the humanities. artificial intelligence and a generic term for the artificial generation of knowledge from experience. In machine learning, an artificial system learns rules from examples, which it can generalise after this learning phase is complete.
Systems based on machine learning are capable of learning. They do not simply learn examples by heart, but are able to recognise patterns and regularities in data. On the basis of machine learning, correlations can be recognised, conclusions drawn and predictions made.
As an example, here is the topic Face recognition to name a few. Machine learning makes this possible because algorithms were first trained on the basis of millions of image data to recognise those structures in the data masses that define a face.
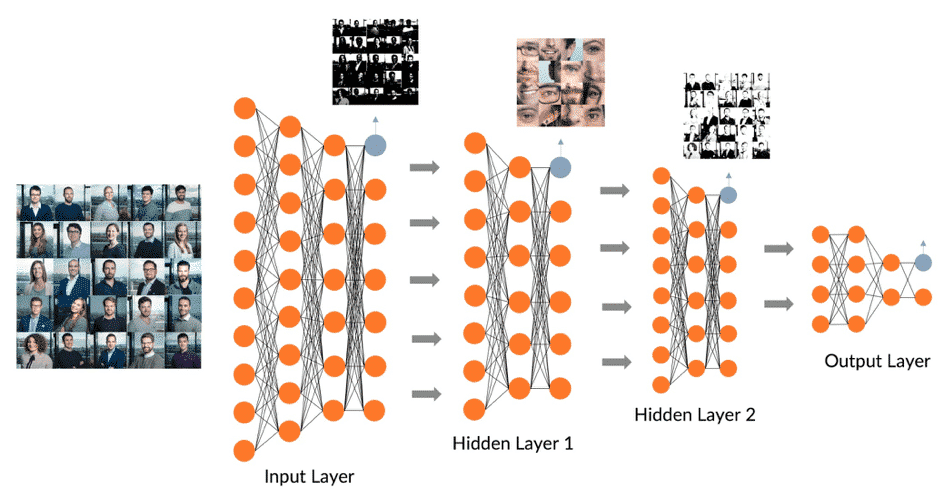
Against this background, the great advantage of a machine-learning capable system is its ability to handle very large amounts of data. On this basis, machine learning can be used to analyse highly complex issues and develop highly specialised systems for individual tasks.
The starting point for many companies is large, previously unused amounts of data and especially machine data. There is a reason why machine learning methods are so relevant. Many companies are currently realising that they have to generate an enormous amount of data and manage it accordingly.
In Machine Learning A distinction is made between four types:
- Unsupervised Learning
- Supervised Machine Learning
- Semi-Supervised Learning
- Reinforcement Learning
The essential difference here is in the learning process.
2. unsupervised machine learning
Unsupervised learning, on the other hand, is needed when implicit relationships are to be recognised in unrelated data sets. A typical task for unsupervised learning is to recognise objects in photos (image recognition). Using a neural network, image data can be examined for patterns and similarities.
Here, too, the machine learning process differs from the "human" approach. The algorithm breaks down the images into their smallest components and searches for the basic constituents. In this case, the more training data available, the better the recognition rate.
For example, it is a great challenge to recognise one and the same face even when it is shown from different perspectives. The problem is that a programme has no spatial imagination. This is why this task is only successful if the ability has been trained in advance using many different views of faces. This is also called Affective Computing.
In our blog article on Unsupervised Learning learn more about the characteristics and modes of operation.
Supervised Machine Learning
Supervised Learning is used wherever there are already results for a particular context or for an existing training set. These findings are then to be transferred to other use cases for which no results are yet available. A typical use case would be classification, for example, when a sorting machine is to automatically assign the apples of a harvest to different quality classes. The results are used in supervised learning to teach a system.
A learning algorithm of the system tries to find a hypothesis on the basis of which the results known in advance are achieved as accurately as possible. Depending on the predicted result, the system receives feedback (praise for correctness or punishment for errors). Based on these repetitive feedback loops, the system will constantly optimise its learning algorithm and, over time, come closer and closer to the fixed results. Supervised machine learning is thus based on the trial-and-error principle.
4 Semi-Supervised Learning
Semi-supervised learning is a mixture of supervised and unsupervised learning. It is essentially used for the same purposes as supervised machine learning. In contrast to supervised learning, however, in semi-supervised learning the associated results are only known for part of the basic data. In order to be able to work with sufficiently large data sets, partial-supervised learning therefore also uses basic data for which the target variable is not yet available.
As a rule, systems in partial-supervised learning work with a small stock of data with a known target variable and a large stock of data without a known target variable. The reason for this is that in practice the acquisition of data sets with known target variables often involves a great deal of effort and is therefore very cost-intensive. Semi-supervised learning is therefore a good choice if a large number of data sets are to be analysed at economically justifiable costs. A very common use case of semi-supervised learning is the identification of faces on video recordings.
5 Reinforcement Learning
Reinforcement learning (also called "reinforcement learning") is a subfield of machine learning in which a system learns a strategy independentlyto maximise the rewards received. The system is not shown which action is best in which situation, but receives a positive or negative reward (praise or punishment) at fixed times. Based on this reward feedback, the system learns over time to execute a long-term benefit-maximising strategy.
The concept of reinforcement learning is borrowed from psychology and attempts to replicate learning behaviour in nature. Human and animal children also learn the right decision-making strategies for them on the basis of a reward system.
In contrast to supervised and unsupervised learning, no data is required in advance for reinforcement learning. The system teaches itself the ideal strategy on the basis of the simulation environment in many test runs.
Reinforcement learning is the basis for forms of artificial intelligence that can solve complex control problems without prior human knowledge. Compared to conventional solution approaches, such tasks can be solved much faster, more efficiently and ideally even optimally by AI based on reinforcement learning.
Many AI researchers see reinforcement learning as a promising method for achieving general artificial intelligence. Reinforcement learning makes it possible for any machine, similar to a human, to successfully master any as yet unknown intellectual tasks.
6. machine learning methods
In Unsupervised Machine Learning, the expected output is not known at the beginning of the learning process. This open-ended approach is therefore exploratory in nature. The learning process takes place when the algorithm tries to cluster data in a certain way or to identify anomalies.
Although there are a large number of machine learning methods and tasks that fall into one of these two categories of algorithms, a small set of Standards turn out to be.
In the case of supervised machine learning, the Classification and Regression to the standard methods; in the case of Unsupervised Machine Learning, the Clustering and Frequent Patterns frequently used methods.
Classification and regression
In order to properly grasp the importance of machine learning methods such as classification and regression, it is important to keep in mind that these are the Basic elements of what is covered by the concept of Artificial Intelligence is captured.
The mathematical and statistical methods help intelligent systems learn to order things and events. They do not do this consciously, of course, but as in this case with the help of Data Scientiststhat monitor the learning processes. As in the case of unsupervised learning you can read in our blog article on Unsupervised Machine Learning methods.
There is not the oneThere is no single algorithm or method to solve all classification tasks. Rather, there is a great variety ofSub- and special forms. Many of them have their origins in mathematics or statistics.
Linear Classification
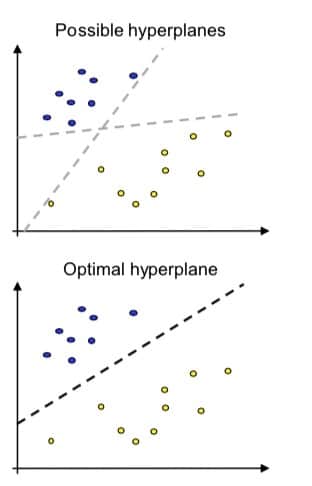
TheLinear Classification- sometimes also called "Linear Classifier" - aims to determine a very specific, linear function. This function describes a boundary that divides data into two classes:
What initially sounds like a very simple method is used in numerous and sometimes complex variations. The most popular linear classifiers includeSupport Vector Machines. These are applied to divide data in a vector space into two different classes. The "art" of linear classification is to define the linear classifier as optimally as possible.
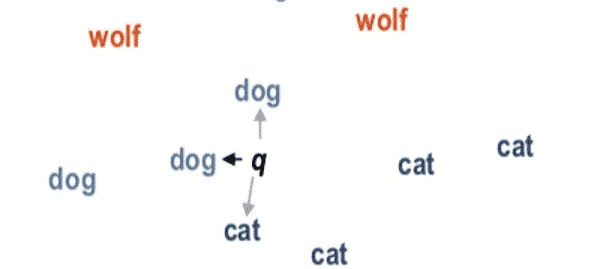
Nearest Neighbour or the NN Classification
TheNearest Neighbours (NN) Classificationrespectively theNearest Neighbour Classifieris a simple method with the aim of identifying similar objects. In the training phase, an algorithm is trained to find the similarity between different training objects.
The Bayes Classifier
One form of classification is the so-called Bayes Classifier. This is a probability-based approach that goes back to Bayes' theorem - a mathematical theorem by the British mathematician Thomas Bayes. The Bayes Classifier is often used to determine cost measures or risks.
Here, too, the starting point is existing training data. These data sets are sorted into certain classes according to a certain probability of their belonging. The more data is available for training, the more precise the classification. A practical example can illustrate how a concrete benefit can arise with classification.
Credit Scoring: Classification in practice
For one of our clients in the banking sector, we developed a scoring system with the help of a classification algorithm to better assess the risk of default when granting loans (credit scoring). It was about small emergency loans between 100 and 200 euros. Since most customers had entries with Schufa, an alternative scoring system had to be developed.
n order to determine the probability of default, we used data from personal credit history and transactions as well as social media activities. This enabled us to classify customers into groups according to certain criteria, which allowed us to draw conclusions about payment behaviour and the likelihood of repayment.
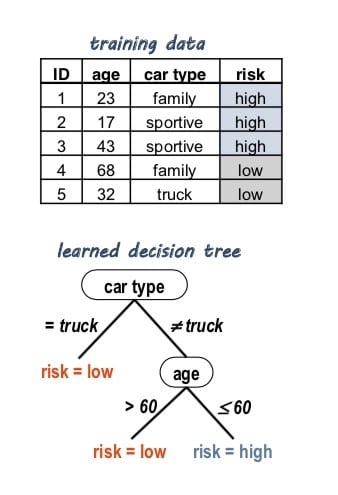
Decision trees help
Decision trees are another important special form of data classification. The trained machine learning model adopts a tree structure. This model is particularly intuitive, so that the classification takes place on the basis of easily comprehensible criteria.
In practice, several decision trees are often used in combination to increase the accuracy of decisions. In this context, the term forest is used.
Regression
At first glance, regression tasks seem very similar to classification tasks, but they are used to answer different questions. This can be easily explained with a concrete example.Delays in rail or air traffic are common and therefore it is important to know how likely they are.
This way, flights can be divided into two classes "a" and "b" - "a" being the delayed flights and "b" being the non-delayed flights. A classification model would be trained to predict how likely a particular flight is to arrive late. For example, the prevailing wind conditions could be used as the basis for classification.
In contrast, a regression model establishes a relationship between input and output. A question for a regression model could be: How many minutes is a flight likely to be delayed under certain wind conditions?
How does machine learning work in practice?
Use case 1: Demand forecast for warehouse optimisation
In times when the supply chains of the global economy function on a just-in-time basis, correctly forecasting demand to optimise inventory is a prerequisite for most companies' own economic survival. Companies that are not able to optimise their warehousing face high additional costs that represent a massive competitive disadvantage.
A typical application of such a demand forecast for warehouse optimisation based on machine learning is an internationally operating dealer of spare parts for construction machinery. The objective for such a spare parts dealer is to stock his warehouses according to demand in order to optimise his costs, but at the same time to ensure an optimal short-term supply to his customers.
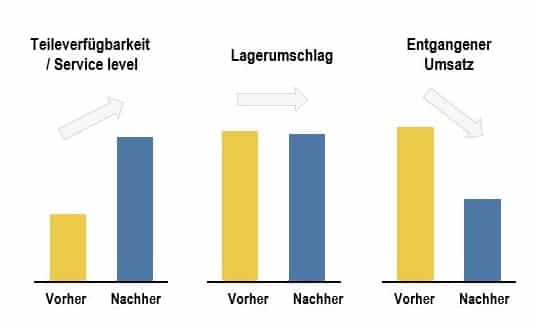
As a data basis for such a use case of machine learning, company-internal data on the historical demand quantities for certain products at different locations can be used. This internal data can be combined with other external data that have a great influence on general construction activity (such as the economic situation and the weather situation).
With the help of machine learning, the specific demand for certain products at different locations can be predicted with high accuracy. As a result, the retailer's parts availability can be improved and inventory turnover increased, which in turn reduces costs while increasing sales.
Use case 2: Diagnosis in power plants
In practice, power producers are often confronted with complex issues relating to energy production and distribution. A permanent challenge is to perfectly understand all processes in power plants and to control them ideally accordingly.
A typical example of process optimisation in power plants is the prevention of steam superheating in a steam power plant, which leads to soot and ash deposits and impairs heat transfer.
Machine learning can be used to define learning algorithms that help understand the relationship between sootblower activity and the effects on superheat levels. Based on this understanding, an intelligent system can then be installed to automatically control the injection cooling.
Use case 3: Reduction of risk questions for insurance companies
Machine learning offers unimagined optimisation potential, especially with regard to the data-driven digitalisation that is rapidly advancing in all industries. Due to the high availability of valid data, the insurance industry is one of the industries in which the greatest improvements are possible with machine learning.
A typical example of process optimisation in insurance is the simplification of the application process for new customers. Insurance application forms that are too long and complex deter many customers from taking out a new insurance policy.
At the same time, insurance companies have a high interest in finding out as much risk-relevant information about their customers as possible. Machine learning makes it possible to combine the best of both worlds - fewer questions in the insurance application while maintaining the same risk forecast for the insurance company.
In this specific case, machine learning can replace risk questions by automatically evaluating data from external providers. An algorithm is able to analyse a catalogue of thousands of features and identify the appropriate features to replace risk questions. In this way, it is possible to massively reduce the number of risk questions in the insurance application without negatively affecting the prognosis quality for the insurance.








0 Kommentare