
In the first part of our blog series we introduced some of the first Transformers and gave an overview of what exactly makes them so powerful. In this part, we introduce the next wave of transformer-based architectures such as Transformer-XL, XLNet, XLM and CTRL. These surpass their predecessors in many ways and deliver even better performance in NLP tasks.
Inhaltsverzeichnis
Transformer-XL1
Let's start with the Transformer-XL. It was introduced in 2019 by researchers at Carnegie Mellon University and Google AI. While they praise how Transformers can capture long-term dependencies, researchers criticise that these models can only do so in a limited context. For BERT and GPT there is a limit of 512 or 1024 tokens.
It is precisely this problem that the two contributions deal with. The first solution is to use a segment-level recursion mechanism that ensures the flow of information between words within a segment, as shown in the animated figure below.
However, applying the approach to a standard transformer would not work easily. This is because these use fixed-position embeddings, i.e. they use integers (0, 1, 2, etc.) to represent the position of each word.
If you split a longer sequence into segments, you would get repetitive positional embeddings (0, 1, 2, 3, 0, 1, 2, 3, etc.) that would confuse the network. Instead, Transformer-XL uses Relative Positional Encoding. It uses the relative distance (e.g. 2 or 3 words) between each pair of words to better encode their relationship in the overall context.
Transformer-XL enables the processing of much longer text sequences. BERT, for example, can only work with 512 tokens, which is comparable to a tweet. With Transformer-XL, it is theoretically possible to work with infinitely long documents.
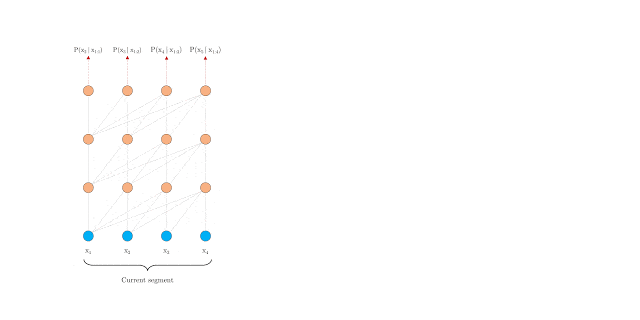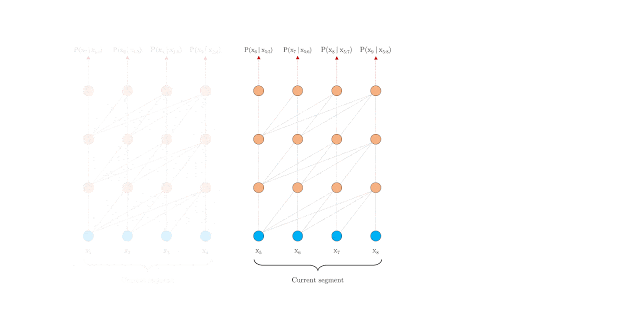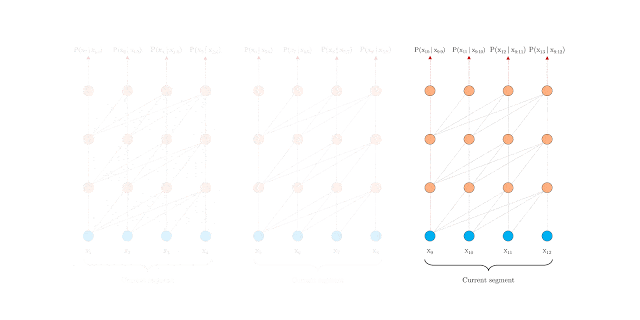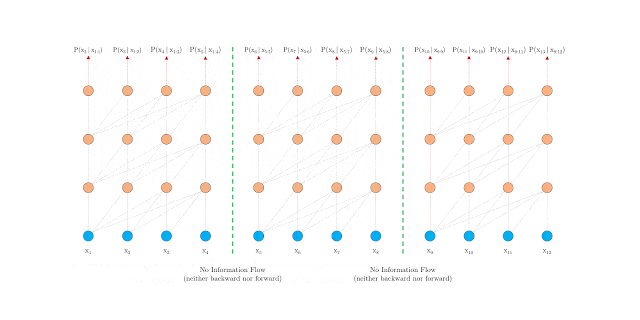
XLNet2
The research group that introduced Transformer-XL has also created an extension to it, XLNet. With this, they address a few other critical points of BERT. The first is the "independence assumption" that BERT makes regarding the hidden tokens it must predict.
BERT's goal of hidden language modelling prevents the model from learning how the predicted words relate to each other. Second, there is "input noise" because of the way tokens are hidden during training by the word "[MASK]". It never occurs as input to the model when applied to a target problem.
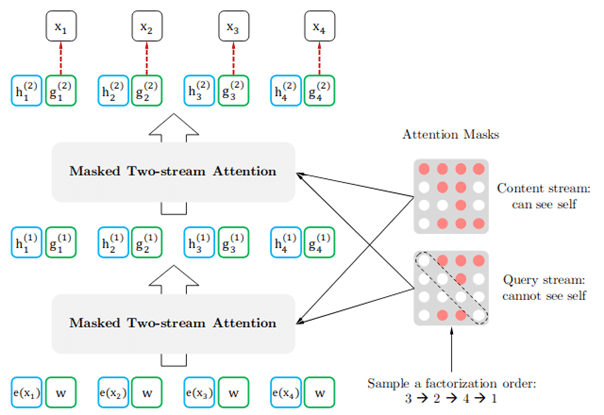
To solve the above problems, XLNet introduces the following two techniques. First, the researchers introduced a new language modelling goal called Permutation Language Modelling. This is an extension of standard causal language modelling (CLM).
PLM takes all possible factorisation sequences (permutations) of words within a sentence and trains the model on the different sequences with the same words. This way it can better learn to deal with a bidirectional flow of information between the words in a sentence.
The second innovation is an extension of the architecture of the Self-Attention mechanism of the Transformer by adding a second Self-Attention stream. The first and original stream, called the Content Stream, focuses on the content of the words. The new one, the query stream, instead works only with the position information of the predicted token. However, it does not know which word it is.
XLNet introduces techniques that help him to work with various NLP tasks perform better overall than GPT-2 or BERT. However, this is at the expense of additional parameters and computational costs.
XLM3
So far, all transformer architectures discussed have been considered in the context of English. A team of researchers at Facebook is looking at cross-language scenarios. They are investigating the already common training targets MLM and CLM in a multilingual environment.
The work tests the two training goals in machine translation and cross-language classification, demonstrating their success. Furthermore, they show that transformers pre-trained on multilingual data can also perform tasks in low-resource languages.
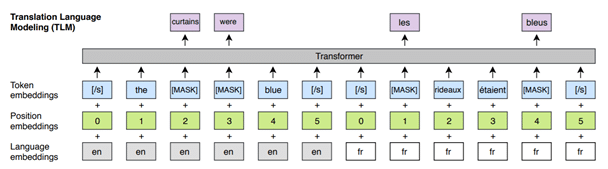
Finally, as part of XLM, the researchers introduce a new training objective, Translation Language Modelling (TLM). This is an extension of MLM. A sentence and its translation in another language are concatenated into a sequence. Then words are randomly masked, just like in masked language modelling, and the model has to predict them. Since words from both languages are masked, the model can learn representations of the words from both languages.
The main advantage of XLM is that the model can perform better in cross-language contexts. BERT also has a multilingual version. However, XLM can provide more accurate results in scenarios where languages are mixed.
CTRL4
A research team at Salesforce has published a new language model that enables controlled generation of speech. Their work introduces the Conditional Transformer Language Model (CTRL), which uses special control codes to regulate the generated text according to various criteria.
Causal language generation models such as GPT are only trained for a specific task, which limits them greatly for other tasks. Normally, the model is conditioned on the initial text prompt and generates a new sequence based on this.
CTRL addresses this problem by proposing the concept of control codes provided along with the prompt. The researchers report that the idea comes from generative models used in the field of computer vision.
Most control codes allow you to control certain text features by specifying a domain. In the excerpt below we see two examples where two different control codes, "horror" and "reviews", are used with the same prompt, "knife". Two very different examples of speech are produced. The first sounds like a horror story. The second feels more like a review you might see in an online shop.
CTRL shines with its ability to control text generation based only on a prefix. This allows training of only one model for solving multiple problems. In contrast, taking GPT-2 as an example, one has to train separate instances of the network for each task to be solved.

Conclusion
In this part of the series, we have given an overview of many additions that have been made to the Transformer architecture to improve its overall capabilities.
We explained how to use it with Transformer-XL for even longer sequences. XLNet demonstrated how the model can learn bidirectional representations with the permutational language modelling taks.
XLM showed how to use transformers in scenarios (e.g. machine translation, cross-language classification, etc.) that involve multiple languages. Finally, through CTRL, we know how to reuse transformers across control codes in multiple settings without having to retrain them.
However, this is not the end of the series. In the next part, we will discuss optimisations related to the computational footprint of transformers.








0 Kommentare