
In short, the answer is yes.
- Automized Machine Learning (Auto ML) does not make data scientists obsolete. Rather, it is a useful tool that makes data scientists more productive.
- The greatest benefit comes when data scientists use Auto ML tools to save time on repetitive steps such as model selection. This allows them to concentrate on other tasks.
- In fact, data scientists spend most of their time translating a business problem into a data science question, collecting, understanding and preparing data, tailoring a technical solution to a specific use case, improving inaccurate predictions, interpreting results and communicating them to relevant stakeholders.
- These tasks are difficult to automate because they are often very specific to the use case. In addition, the correct application of Auto ML tools often requires knowledge of machine learning. For these two reasons, there will continue to be a need for (human) data scientists for the foreseeable future.
Inhaltsverzeichnis
What is Auto ML?
Auto ML is an important new development in the evolution of machine learning. It has gained momentum during the last three years and is now available to businesses in different forms (see next section).
The goal of Auto ML is to automize as many steps in a machine learning project as possible. However, not all steps are equally easy to automate. Best suited are the steps of model selection and hyperparameter optimization since they are typically relatively independent of the specific use case. The automation of these two steps is what is commonly understood as Auto ML. But there are also attempts to tackle additional steps of a machine learning task, such as data cleaning, feature creation, feature selection, and making the predictions explainable. If domain-specific knowledge is not needed, Auto ML can partly support human data scientists in some of these areas as well.
Generally, we can think of Auto ML as one more level of abstraction. Just as data scientists typically do not start at a blank code editor when they want to train a machine learning model – there are already plenty of code packages available for that – with Auto ML, they do not need to call many different code packages and compare the best-performing model manually anymore. This can be done by a higher-level Auto ML tool. In the ideal case, the input is merely a cleaned data set, an error metric, and the maximum time to search for the best model. The output is a leaderboard of the tuned models, ranked by the error metric.
What kind of Auto ML tools exist and how can we use them?
Auto ML solutions can be roughly grouped into three main categories.
The first group is stand-alone code packages. They can be either open-source or proprietary. Popular open-source python packages are, for example, AutoGluon, H20 AutoML, and TPOT. Moreover, for the popular machine learning libraries Scikit Learn for tabular data and Keras for deep learning, there are Auto ML wrappers available, called Auto-Sklearn and Auto Keras. Using these packages requires coding experience in Python.
The second category is Auto ML solutions integrated into popular cloud services, such as Azure Machine Learning, Amazon SageMaker, or Google’s Vertex AI. These solutions can be convenient to use if you already have your data stored in a cloud. Plenty of computational resources are available there, too. Auto ML tools in clouds may require coding, but it might also be possible to use a graphical user interface.
The third category in which you can encounter Auto ML is specialized data science platforms. They differ from the more broadly orientated clouds mentioned above in that they are specialized in data processing, automized machine learning, and deployment. Examples are Dataiku, H20, RapidMiner, or DataRobot. These platforms have become increasingly popular over the last few years. They provide an easily accessible graphical user interface for end-to-end data science projects, from data cleaning to deployment. Based on the idea of a low code environment, data science platforms were built around Auto ML modules. However, recognizing the demand from data scientists to tailor their data science solutions to their specific use case, data science platforms have moved towards more flexibility by allowing for the insertion of the expert’s own code in their data science pipeline.
Last, Auto ML capabilities are also available from other providers that do not strictly fall into the three groups mentioned above. Examples are the Auto ML offerings by the more data-centric platforms of SAP or Databricks.
What are the benefits of Auto ML?
As mentioned in the beginning, Auto ML can be a useful tool that makes data scientists more productive. We can view it as an “assistant” that takes over mechanical tasks. The benefits for a human data scientist are:
- Less time needed for repetitive tasks such as model selection and hyperparameter tuning - and in turn more time to focus on the business problem, gathering and pre-processing helpful data, and communicating the approach and results to stakeholders
- Auto ML can provide a strong baseline for a proof of concept that can be further fine-tuned in later stages
Is there still a need for human data scientists?
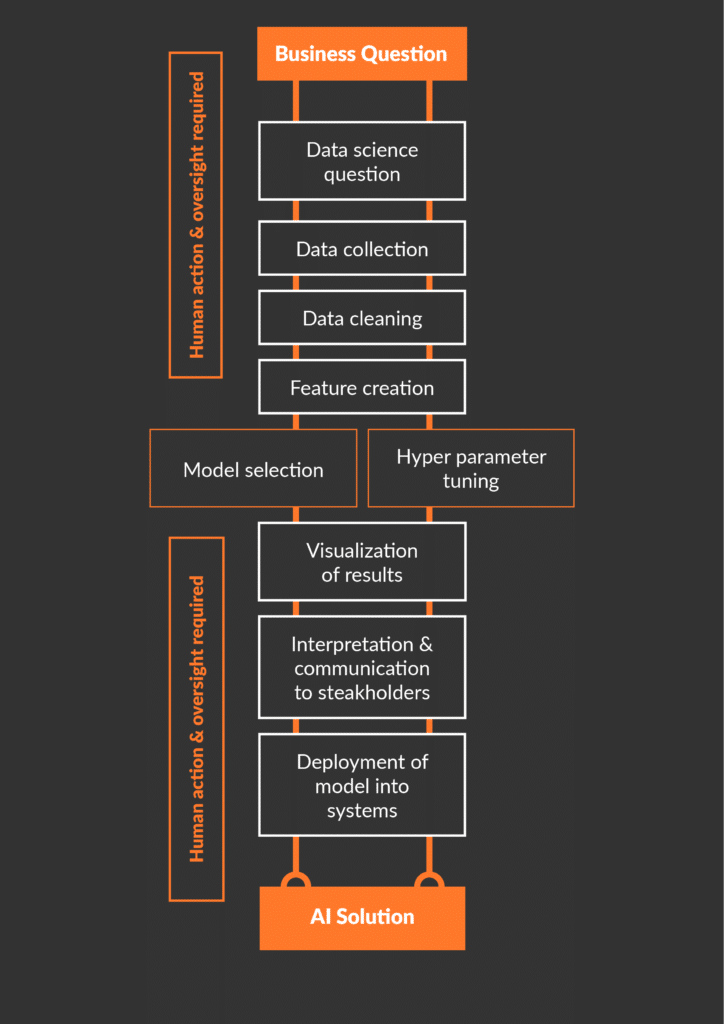
The discussion of whether Auto ML will replace human data scientists is misguided. A better question might be: how and to which degree can data scientists make effective use of new Auto ML tools? The general answer is, the less use-case specific a task, the better it can be automized. Let’s go through the different tasks of a typical machine learning project (see Figure 1) and evaluate their potential for Auto ML.
We usually start with a business question and the domain knowledge of business processes. Here human expert input is key and gathering it to get a good understanding is a typical first task of a data scientist. Next, mapping a business problem and its requirements to a data science question is also often challenging and highly specific to the business environment. Therefore, it is difficult to integrate into an Auto ML tool.
Another crucial step in a data science project is data gathering and preparation. Selecting the right data sources, asking for additional data, and combining different data sets are often fundamental for the success of the project. Understanding and cleaning the data is another important part. It is often very dependent on the available domain knowledge and requires feedback loops with business experts.
In total, data collection and pre-processing usually account for the largest share of the time budget of a data science project. While some small standard mechanical tasks - such as bringing the entries of a column in the same format, removing stop words in NLP, or some data augmentation techniques for images - can be handed over to algorithms with human oversight, data preparation is often very use case specific and requires human actions. An important example of the need for human oversight is the detection and treatment of bias in the input data. Understanding the source of the data and how it was generated can be important to avoid bias in the predictions.
The next task is to prepare the cleaned data for a machine learning model. This often involves creating additional features. Models have different feature input requirements to function well. Here, Auto ML can contribute by transforming or creating new features that are standard for certain model classes. Examples are the one-hot encoding of categorical features in the case of tree-based models or the standardization of the data.
Once the data set is clean and features are created, Auto ML comes in handy when selecting the best-performing model for a data set. Quickly obtaining a leaderboard with an overview of the performance of different models and model classes speeds up the process. Tuning hyperparameters can similarly be automated. However, contrary to a common expectation, at least for structured data, these two steps typically only make up a small share of a data scientist’s overall workload.
Auto ML works best with clean data sets, standard models, and standard error metrics. Such conditions are often met in prediction challenges and tabular data, such as the ones found on Kaggle. Here, Auto ML tools as out-of-the-box solutions already reach an impressive performance. However, real use cases typically differ from such an ideal setting. The fact that data science platforms have made their no-code or low-code environments more flexible for human-provided code reflects the frequent need to customize machine learning pipelines to the use case, for instance, due to special error metrics or specific data pre-processing steps.
As mentioned before, flexibility in data science projects is often key. If this is the case, coding experience is needed to tailor the ML pipeline to a specific use case. Moreover, machine learning knowledge is required to interpret the results and to take actions to improve upon unsatisfactory or biased prediction results. Hence, Auto ML tools are best used by skilled data scientists.
And last, there is the step of translating the prediction results of a model back to the business domain to solve the original business question. This can include the visualization of results in a dashboard and integrating the model into an AI system that can easily be used and understood by the stakeholders. These are key tasks for which human data scientists are needed.
Zooming out, the experience shows there are also many data science projects in which machine learning is not the best solution to solve a data-related business problem. A smart use of descriptive statistics, a novel combination of data sets, operations research techniques, automating processes without machine learning, and visualizing data in interactive dashboards are examples for data science use cases that do not require machine learning. They remain in the domain of human data scientists. Generally, machine learning is itself only one possible technique in a data scientist’s toolbox. Maximizing the added value for stakeholders is the central objective for a data scientist, regardless of the tool that is used to reach that goal.
To sum up, Auto ML describes a new set of higher-level tools that can facilitate a data scientist’s work by automizing repetitive tasks in a machine learning project. Using these tools requires knowledge of machine learning and statistics. Therefore, they are typically used by human data scientists. For the foreseeable future, Auto ML will not replace human data scientists since many steps in a data science project are either very use case specific and thus difficult to automize, or they require human interaction.
PS: If you are as interested in automizing processes as I am, you may wonder whether this article could have been written by Open AI’s Chat GPT. I tried it. My experience was that its output was quite impressive for supplying arguments for the applicability of Auto ML. However, ChatGPT’s definition of Auto ML was not entirely to the point in my view and not all arguments were convincing to me. Generally, my takeaway is that only with pre-existing knowledge of a topic one can judge whether the answers of ChatGPT make sense. If expert knowledge is available, ChatGPT can be a useful tool to provide a first draft or to double-check one’s own text.









0 Kommentare