Over the past decade, terms like "data science", "big data", "data lake", "machine learning", "AI" and so on have come to the fore (and sometimes back again). However, regardless of their wide use (or perhaps because of it!), there seems to be little agreement on what many of these terms mean. I don't want to get into an extended argument about unified nomenclature, but there are two commonly used terms that are of particular interest to me: "Data Scientist" and "Machine Learning Engineer".
In the broadest sense, these two terms could be defined as "technically skilled people who provide solutions in the field of Machine Learning develop " should be understood. "Data Scientist" is a term that over the years has been associated with a kind of generalist mathematician or statistician who can also do a bit of programming and knows how to interpret and visualise data. More recently, the term "machine learning engineer" has been associated with software developers who have learned some mathematics in the process.
Link tip: In this series of articles we present the most important Machine Learning Methodssuch as clustering and classification.
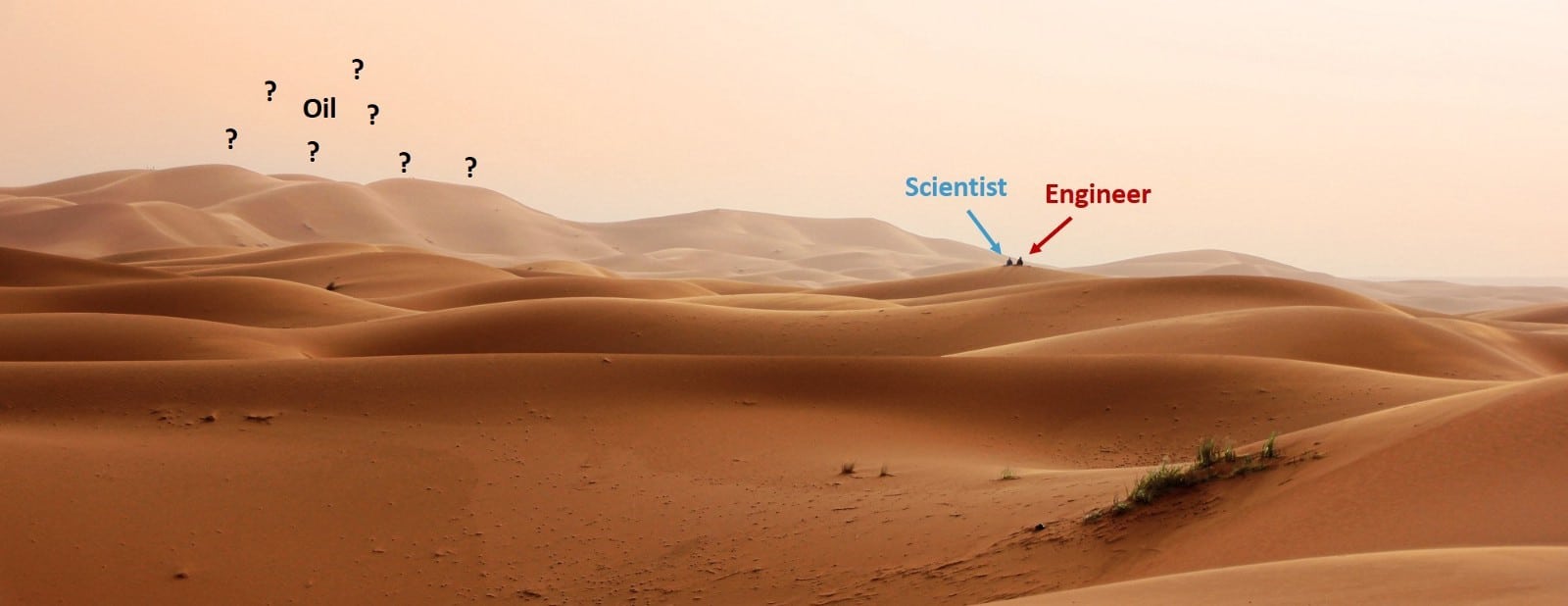
While there is certainly some truth in these interpretations, I don't find any of them particularly useful. Therefore, at the risk of adding to the confusion, I would like to illustrate my interpretation of what these roles mean through a little parable of two intrepid adventurers - a scientist (Data Scientist) and an engineer (Machine Learning Engineer) - who set out in search of oil in an unknown and possibly endless desert....
Inhaltsverzeichnis
According to their tasks, the engineer and the scientist are equipped differently
The scientist is light on his feet. He has a backpack, a compass, a spade and some simple but precise measuring instruments. He makes a few trips into the desert, never very deep, but deep enough to assess which direction is most promising. Within a few days of taking measurements and digging a few holes with the spade, he has an idea of where there might be oil.
The engineer, on the other hand, brings heavy and sophisticated machinery. At the moment, he is not yet concerned with where oil can be found. But once it is found, it has to be transported, so he spends the first few days drawing up a design for a pipeline.
The collaboration allows the two researchers to combine their strengths and become more effective
After a few days, the explorers confer and the scientist declares that he will make more extensive forays for the next few days, as he is now much more certain where he will find the oil. As the scientist drives off, the engineer starts up his machine and - following the scientist's footsteps - builds the first section of the pipeline. Finally, he catches up with the scientist who had discovered a small well!
Together they set up a drill at the site and connect it to the pipeline. This pipeline makes the scientist's work much more efficient and although they have not yet found a really big well, this smaller well is already yielding some profits and the engineer can use it to test his pipeline.
After a few months of smooth cooperation, both discoverers are ready for the first major breakthrough
In preparation for the next phase of their adventure, the engineer builds a lightweight oil drill and instructs the scientist how to use it. With this specialised drill, the scientist is now able to open wells without the engineer's presence. For a while, the scientist continues to work on finding new wells while the engineer continues to connect them to the pipeline.
Next, the engineer now also designs lightweight pipes that the scientist can connect to the pipeline without the engineer's help. This allows the scientist to speed up his explorations considerably and at the same time frees the engineer from redesigning large parts of the pipeline, making them more stable and efficient.
Similarly, the scientist is developing a new standardised set of measurements that the engineer can incorporate into the measurement logs of the main hub so that the scientist no longer has to travel to the drilling sites to monitor their performance.
After months of hard work, they reach the big oil well they have been looking for. Together they attach the well to the pipeline and install sophisticated measuring equipment. By now the routine is well regulated. Measure, drill, fix, pump, measure. Done. In no time at all, the big oil well is gushing.
After a while, they go their separate ways - the engineer stays on site while the scientist contributes outside the project
Soon after, the scientist packs up and heads home. He is no longer needed on site, but is still available to analyse the well's measurements.
The engineer stays a little longer. He is not yet happy that the whole system is working perfectly. A crew of operators arrives and together they correct any remaining problems. Then the engineer hands over the system to the operators and goes home, promising to return if there are any problems.
Reunion of the scientist and the engineer
Our two explorers meet again soon. They reflect on their little desert adventure and start making plans together for their next exploration - apparently there might be oil in the Arctic and they are ready to find out!
Data Scientists and Machine Learning Engineers have different roles
Perhaps you can see from the story above some of the elements that go into a successful machine learning project.
I chose this little parable of two explorers because I believe that machine learning - although it has made great strides in the last five to ten years - remains an area that largely requires forays into uncharted territory. I believe that a spirit of exploration (quick prototyping) is just as relevant as it was five years ago, but it is also increasingly important to start preparing production systems (quick scaling) at the very beginning of the project.
For my two explorers, I chose a (data) scientist and a (machine learning) engineer to illustrate the importance of their collaboration for fast and effective value creation.
There are undoubtedly many different definitions for these two roles, but for me the defining characteristic is that the Data Scientist is someone who asks: "What is the best algorithm to solve this problem?" and tries to answer this question by quickly testing different hypotheses (searching for oil wells). The Machine Learning Engineer, on the other hand, asks: "What is the best system to solve this problem?" and tries to answer this question by setting up an automated process (building an oil pipeline) that can speed up the testing of hypotheses.
Despite the different roles between the Data Scientist and the Machine Learning Engineer, their collaboration is crucial for machine learning projects
Whether or not these two definitions of 100% are correct, it is important that collaboration happens when two talented professionals with these mindsets come together. In my example, the Data Scientist is looking for new model architectures to try; new methods to measure performance; new data sources to ingest, etc., while the Machine Learning Engineer is looking for ways to integrate the Data Scientist's work into a scalable system. As the system scales, the Data Scientist becomes more efficient because he has better tools. The Machine Learning Engineer becomes more effective because the tools he develops are used to deliver more and more valuable results.
However, for the Data Scientist, the focus will be on quick results rather than developing sustainable software. As such, the tool of choice for Data Scientists - since the whole thing is typically set in the Python world - will be the extensive use of Jupyter Notebooks, which actively support an exploratory way of working; the end product of this work is typically prototype scripts.
However, the machine learning engineer writes software. I can't stress this enough. (If you are very good at machine learning and create clearly structured, well documented and easy to maintain scripts, then you are the best Data Scientist we can ask from Alexander Thamm on a project - not a Machine Learning Engineer!) The Machine Learning Engineer focuses on developing software that scales quickly. Much of this will also scale in the Python world, which means IDEs (integrated development environments) like PyCharm are typically used as the tool of choice. (It goes beyond Python, however, as scaling also means mastering tools that orchestrate resources for model training and serve trained models to end-user systems, but that's a discussion for another time).
Different phases of the project require different involvement of Machine Learning Engineers and Data Scientists
The last thing to talk about is the phases of the project and who is involved and when. If you look at a project progression that goes through the phases of "hypothesis"; "proof of concept"; "prototype" and "production" - it is tempting to say that the first two are the domain of Data Scientists, while the last two are the domain of Machine Learning Engineers. I would only partially agree.
The data scientist and the machine learning engineer standing on the edge of the desert, looking into the distance and wondering if there could be oil out there: This is the "hypothesis" phase. The scientist walking around in the desert digging lots of little holes with a spade to see the first signs of oil, while the engineer draws the designs for his pipeline, is what I would call "proof of concept". A full-scale pipeline is built, and the first small well tapped is what I would call a "prototype". And the large-scale, fully refined and highly efficient system, maintained by a team of operators, is what I would consider "production".
The Machine Learning Engineer and the Data Scientist are crucial throughout the project.
Perhaps the right way to look at it is to recognise that each of the phases will require input from both roles, but that the appearance of that input will change. In particular, at the beginning, the machine learning engineer will be heavily dependent on the exploration by the data scientist, and later the data scientist will be heavily dependent on the tools that the machine learning engineer develops. But each will remain relevant - even indispensable - throughout.
And in the end, they both move on to the next step, which will probably be yet another voyage of discovery - this time to the Arctic?
Original blogpost on Medium by our Head of AI & Leading Machine Learning Engineer Karl Schriek.








0 Kommentare