
Künstliche Intelligenz (KI) ist einer der wichtigsten Data-Science-Trends. Dabei gibt es nach wie vor ein sehr breites Spektrum an Auslegungen, was unter dem Begriff wirklich zu verstehen ist. Einerseits ist Künstliche Intelligenz in aller Munde. Andererseits nutzen laut einer jüngsten Studie von PWC erst 6 % der Unternehmen KI. Dieser Befund ist aus zwei Gründen erstaunlich. Denn zum einen ist selbst den Befragten der Studie der Nutzen von KI bewusst. Zum anderen ist das Spektrum an Anwendungsmöglichkeiten für Künstliche Intelligenz enorm.
Inhaltsverzeichnis
Definition von Künstlicher Intelligenz
Zunächst ist Künstliche Intelligenz ein Sammelbegriff, unter dem eine Reihe von Teilgebieten der Informatik und Mathematik zusammengefasst sind. Das Ziel der darin erforschten Methoden ist, komplexe Aufgaben zu lösen. Häufig handelt es sich um Problemstellungen, die bisher nur mithilfe der menschlichen Kognition gelöst werden konnten.
Zu den bekanntesten Methoden in diesem Bereich gehören: Machine Learning, Deep Learning, neuronale Netze und Natural Language Processing (NLP). Darüber hinaus gibt es in jedem dieser Forschungsfelder zahlreiche weitere Methoden. Eine der Herausforderungen in der Praxis ist demnach, das Problem richtig zu erfassen und eine passende Methode zu dessen Lösung zu identifizieren. Die Grundfragestellung bei der Entwicklung der Künstlichen Intelligenz lautete vereinfacht gesagt: Können Computer das menschliche Gehirn nachahmen? Zahlreiche KI-basierte Methoden bilden daher die Funktionsweise des menschlichen Gehirns ab. Die menschliche Nervenzelle fungierte wie eine Art Blaupause für künstliche Neuronen.
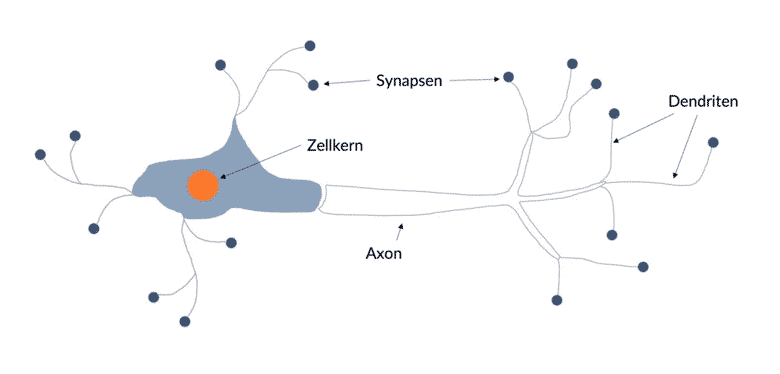
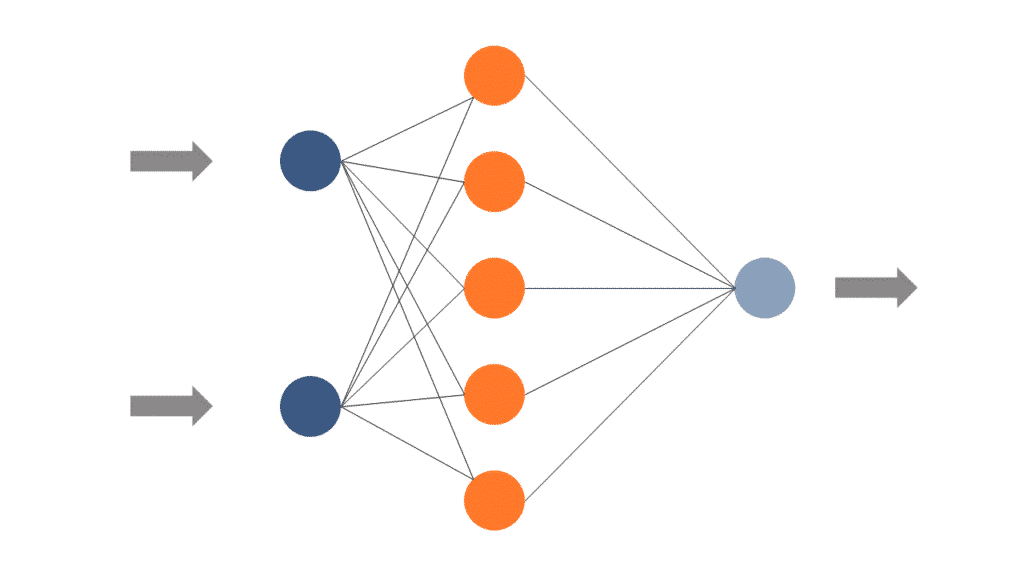
Dieser einfache Aufbau von Input, Signalverarbeitung und Output findet sich als Grundprinzip in nahezu allen gängigen KI-Methoden wieder. Dieser Versuchsaufbau liefert aber nur dann sinnvolle Ergebnisse, wenn er entsprechend trainiert wird. Dabei geht es um das Erlernen von Regeln, die bestimmen, wie das eingehende Signal verarbeitet werden soll.
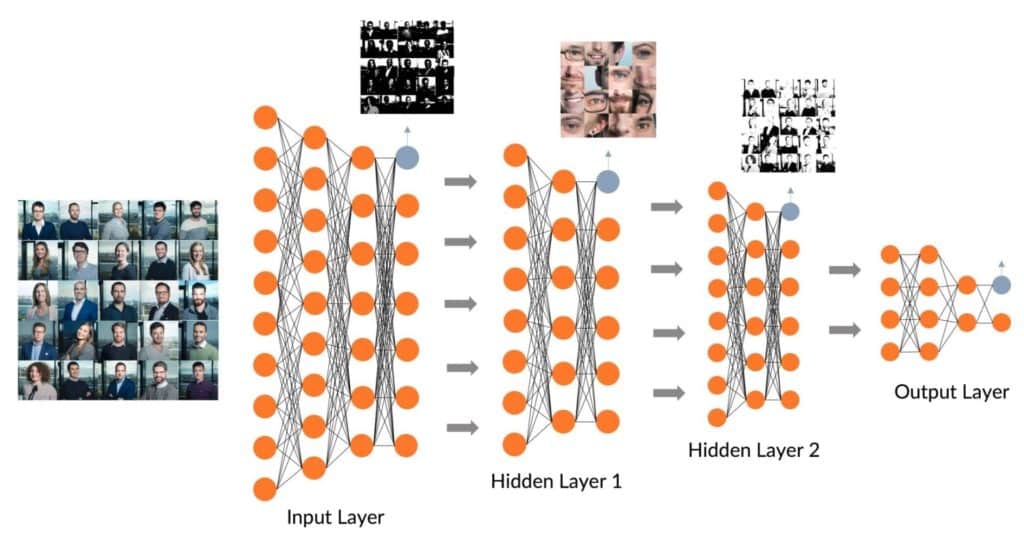
Nehmen wir zum besseren Verständnis das Beispiel Bilderkennung. In diesem Fall soll eine Künstliche Intelligenz darauf trainiert werden, Gesichter auf Bildern zu erkennen. Dazu muss eine passende Methode gefunden werden, mit der ein Neuronales Netz trainiert wird. Jede der Hidden Layer untersucht charakteristische bedeutungsunterscheidende Merkmale, um in den Bilddaten Gesichter zu erkennen. Während des Lernprozesses bekommt jeder einzelne Punkt im Netz eine bestimmte Gewichtung.
Die Grundlage
Die zentrale Grundlage für alle KI-Anwendungen ist eine ausreichende Menge an Daten. Zudem müssen sie eine entsprechende Datenqualität aufweisen. Diese Daten sind notwendig, weil die KI-Systeme für ihren Einsatz in der Praxis trainiert werden müssen. Erst dann können sie ihre Aufgabe erfüllen.
Dies wird am Beispiel von Verfahren zur Bilderkennung deutlich. Eine Künstliche Intelligenz lernt dabei zunächst anhand von Millionen von Bilddaten bestimmte Elemente auf den Bildern zu erkennen. Erst nach diesem Lernvorgang kann dieses System auf unbekannten Bildern dieses Element zu erkennen. Dabei kann es sich um Hunde, Katzen oder Gesichter von Menschen handeln.
Wohl eins der bekanntesten Beispiele dafür ist das „Muffin-Chihuahua Beispiel“. Sogar für den Menschen ist es manchmal auf den ersten Blick schwierig zu unterscheiden, ob es sich um einen Muffin oder ein Chihuahua handelt.

Grundsätzlich unterscheidet man zwischen zwei Arten von KI, der schwachen und der starken KI.
Schwache KI – Heute längst Realität
Als schwache KI werden all diejenigen Anwendungen von Künstlicher Intelligenz bezeichnet, die auf eine einzelne Aufgabe beschränkt ist. Alle heute existierenden Ausformungen fallen in den Bereich der schwachen KI. Entgegen der häufigen Annahme ist hier der Mensch nicht der Maßstab. Schon heute überschreiten die Fähigkeiten von schwacher KI die Leistungsfähigkeit des Menschen bei der Bewältigung derselben Aufgabe.
Starke KI – Eine Zukunftsvision
Von starker KI ist dann die Rede, wenn eine Künstliche Intelligenz die Intelligenz des Menschen in allen Bereichen überschreitet. Besonders, wenn es gleich noch um die Gefahren von Künstlicher Intelligenz gehen wird, ist in der Regel die starke KI gemeint. Diese zeichnet sich durch eine bestimmte Eigenschaft aus. Sie wäre dazu in der Lage, nicht nur eine Aufgabe besser als der Mensch zu bewältigen, sondern beliebig viele. Aufgrund dieser Fähigkeit wird diese Form der Künstlichen Intelligenz auch Artificial General Intelligence genannt.
Die Frage wann und ob eine starke KI jemals entwickelt werden wird, ist aber bis heute nicht geklärt. Zwar gibt es erste erfolgversprechende Versuche, die im Zusammenhang mit Reinforcement Learning erzielt wurden. Neben der technologischen Entwicklung müssen aber vor allem noch gesetzliche Rahmenbedingungen geschaffen. Dazu gehört auch eine gesellschaftliche Debatte über Fragen der Anwendbarkeit und der Ethik. Uneinigkeit herrscht auch ganz grundsätzlich hinsichtlich der Einschätzung, ob eine starke KI über Bewusstsein, Empathie oder emotionale Intelligenz verfügt. Der Erfolg der mit der starken KI verbunden Zukunftsvision steht und fällt aber nicht nur mit ihren Fähigkeiten. Mindestens ebenso wichtig ist das Vertrauen, das die Menschen in darin haben.
Die Gefahren von Künstlicher Intelligenz
Das Thema KI polarisiert. Warnungen und Angst begleiten die Entwicklung der Künstlichen Intelligenz seit jeher. Dabei lässt sich zwischen unbegründetem Alarmismus und realen Gefahren unterscheiden. Beispielsweise gibt es bislang keine Belege, dass KI zur Massenarbeitslosigkeit führen wird. Im Moment scheint viel eher das Gegenteil der Fall zu sein. Wahr ist, dass Künstliche Intelligenz ein großes Potenzial hat, die Arbeitswelt zu verändern.
Es gibt zahlreiche irrationale Ängste, wenn es um die zukünftige Entwicklung der starken KI geht. Dazu zählt etwa der Glaube, dass intelligente Maschinen ein Bewusstsein entwickeln und sich gegen den Menschen richten könnten. All diesen Szenarien sind aus heutiger Perspektive vor allem ein Argument entgegenzuhalten. Nämlich, dass nur sehr wenige Forscher sich überhaupt mit der Entwicklung einer starken KI beschäftigen.
Eine reale Gefahr besteht jedoch darin, dass Entscheidungsprozesse zu sehr auf den Analysen von Algorithmen basieren. Zum Problem wird dies vor allem dann, wenn ein tiefgreifendes Verständnis für Datenanalysen fehlt. Die Annahme, Programme würden die eigenen Fähigkeiten übersteigen, ist also eine Gefahr. Denn sie schaltet die eigene Urteilsfähigkeit aus und überträgt die Verantwortung an die Maschine.

By loading the video you accept YouTube’s privacy policy.
Learn more
Vor- und Nachteile von KI
Da diese Debatte über die Gefahren von KI die Teilnehmer lediglich in zwei Lager spaltet sollte sie versachlicht werden. Hier sollen darum die Vor- und Nachteile von KI aufgeführt werden. Auf diese Weise wird zum einen deutlich, wie Unternehmen vom Einsatz von KI profitieren können. Zum anderen werden Handlungsfelder aufgezeigt, in denen Risiken bestehen.
Die Vorteile
- Optimierung von Prozessen und Steigerung der durch Steigerung der Effizienz
- Einsparung von Kosten durch Automatisierung und Teilautomatisierung von Routineaufgaben
- Verbesserung des Schutzes vor Cyber-Attacken und Hackerangriffen
- Schaffung von Grundlagen für datengetriebene Geschäftsmodelle
- Verbesserung der Customer Journey durch Personalisierung
- Steigerung der Qualität von Datenanalysen
- Erhöhung der Sicherheit beim Einsatz von Robotern oder autonomen Fahrzeugen
- Förderung von Wissen aus Daten
Neben diesen bewusst eher allgemein gehaltenen Vorteilen ließen sich zahlreiche konkrete Vorteile benennen, die aus einzelnen Anwendungen resultieren. Beispielsweise lassen sich Krankheiten durch Künstliche Intelligenz besser diagnostizieren, die Entwicklungszeit von Medikamenten signifikant verkürzen oder im Fall des autonomen Fahrens die Zahl der Unfälle verringern.
Realistische Chancen
Beim Thema Künstliche Intelligenz wiederholt sich ein Reaktionsschema, das sich auch bei anderen Phänomenen wie Big Data oder Social Bots zeigte. Neue Technologien lassen sich zum Guten und zum Schlechten einsetzen. Darum ist es wichtig, sich mit den realen Gefahren und den Möglichkeiten auseinanderzusetzen.
Für Unternehmen ist es darum wichtig, mit Data-Science-Anwendungen, Chatbots oder Big Data positive Erfahrungen zu sammeln. Nur dann können sie ihren Mitarbeitern ein realistisches Bild von den damit verbundenen Chancen vermitteln.
Mitarbeiter müssen durch Workshops und Data Science Schulungen mit dem entsprechenden Wissen ausgestattet werden, um produktiv mit den neuen Technologien umzugehen. Ein proaktives Vorgehen lohnt sich allein aufgrund der Wettbewerbssituation. Wer früh Kompetenzen ins Unternehmen bringt und eine Bereitschaft sowie eine positive Einstellung bei seinen Mitarbeitern schafft, wird am meisten von den Vorteilen profitieren, die Künstliche Intelligenz mit sich bringt.
Die Nachteile und Risiken
- Entscheidungsprozesse werden zum Teil nicht verstanden
- Neue Risiken im Zusammenhang mit Datenschutz und Datensicherheit
- Unrealistische Erwartungen an KI-basierte Anwendungen
- Verantwortlichkeiten für neu entstehenden Bereiche oft unklar (Data Governance)
- Ungeklärte Fragen bezüglich Haftung und Ethik
- Verwischung der Grenze zwischen Wahrheit und Fake (Deepfake)
Insbesondere der letzte Punkt zeigt, dass die Risiken und Nachteile von KI einen Handlungsdruck erzeugen. Die Schaffung von gesetzlichen Rahmenbedingungen und die Aufklärung über die neuen Möglichkeiten sind unerlässlich. Denn auch das gehört zur Künstlichen Intelligenz: Die täuschend echte Manipulation von Daten wie im folgenden Video.
Organisationen müssen sich auf den Einsatz von Künstlicher Intelligenz vorbereiten. Dies gelingt, indem die Mitarbeiterinnen und Mitarbeiter geschult werden und ein Verständnis, dafür bekommen, wie sie Daten und Künstliche Intelligenz gewinnbringend nutzen können.
Künstliche Intelligenz im Alltag
KI sorgt für zahlreiche Fortschritte in der Forschung wie beispielsweise in der Medizin oder im Rahmen der Industrie 4.0 und findet sich aber auch längst in zahlreichen Bereichen des alltäglichen Lebens wieder. Ohne dass es den Nutzern immer bewusst ist, profitieren sie häufig von den Vorteilen von KI-basierten Algorithmen. Beispielsweise nutzen Recommender-Systeme zur individualisierten Empfehlung von Content Künstliche Intelligenz. Das Prinzip „Wenn Dir A gefallen hat, gefällt Dir auch B“ findet sich inzwischen bei zahlreichen Plattformen wieder. Sei es bei Produktempfehlungen in Web-Shops oder bei Content-Anbietern wie Netflix oder Spotify.
Der Grund, warum die Qualität der personalisierten Empfehlungen in den letzten Jahren kontinuierlich zunahm, ist Künstliche Intelligenz. Während ältere Empfehlungsdienste noch ohne Künstliche Intelligenz auskamen, konnten mit den neuen Analysemethoden wesentliche Verbesserung erzielt werden.
Auch viele Chatbots und Sprachassistenten verstehen und imitieren die natürliche Sprache des Menschen dank Methoden wie NLP. Das zeigte Google spätestens bei der Vorführung des Google Assistent bei der Entwicklerkonferenz I/O im Jahr 2018 eindrücklich. Der Google Assistent führte auf völlig natürliche Art und Weise ein Telefonat mit einem Restaurant, um einen Termin zu koordinieren.
Auch die Fähigkeiten von anderen Sprachassistenten wie Amazons Alexa wachsen dank Künstlicher Intelligenz Jahr für Jahr. Ein anderes Beispiel bietet die Automobilbranche, die vor einer großen durch KI ausgelösten Transformation steht. Angefangen bei der Entwicklung, über die vernetzte Produktion bis hin zu Betrieb und Wartung. Letzteres zeigt sich insbesondere an neuen Wartungsansätzen wie Predictive Maintenance.
Überall finden sich Prozesse, die durch den Einsatz von Künstlicher Intelligenz verbessert und optimiert werden können. Und nicht zuletzt sind autonom fahrende Fahrzeuge ein wichtiges Beispiel für den zukünftigen Einsatz von KI im Alltag.
Künstliche Intelligenz in der Wirtschaft
Über Künstliche Intelligenz und ihre Auswirkungen in der Wirtschaft wird oft im Zusammenhang mit Befürchtungen diskutiert, dass durch den technologischen Fortschritt Arbeitsplätze verloren gehen. Doch oft sind die Vorstellungen darüber, was Künstliche Intelligenz tatsächlich ist, diffus und manchmal sogar falsch.
Unternehmen, die den Einsatz von Künstlicher Intelligenz erwägen, sollten aufgrund von den eingangs erwähnten Missverständnissen und damit verknüpften Unsicherheiten frühzeitig Aufklärungsarbeit leisten. Oft sind Ängste unbegründet und hemmen vielmehr bei der Einführung von neuen, innovativen Projekten.
Wer erfolgreich Künstliche Intelligenz im Unternehmen anwenden will, muss seine Mitarbeiter mitnehmen. Ängste und Hemmungen müssen abgebaut werden und der tatsächliche Nutzen und Zweck erläutert und bewusst gemacht werden.
By loading the video you accept YouTube’s privacy policy.
Learn more
Warum die Angst vor Künstlicher Intelligenz unbegründet ist
Stark verkürzt lässt sich Künstliche Intelligenz als Fähigkeit definieren, kognitive Prozesse digital abzubilden und nutzbar zu machen. Eine Vorstellung, die im Moment in die Irre leitet, bringt Künstliche Intelligenz sehr schnell mit menschenähnlichen Maschinen in Verbindung.
Die Idee, dass intelligente Maschinen Menschen überlegen sind und sie bald ersetzen können, ist oft durch Hollywoodfilme inspiriert. Dort finden sich zahlreiche Beispiele, in denen Maschinen mit Künstlicher Intelligenz den Menschen gegenüber feindlich eingestellt sind. Filme wie Terminator, Matrix oder Ex Machina prägen bewusst oder unbewusst unsere Erwartungshaltung gegenüber Künstlicher Intelligenz. Zugleich wird dadurch ein realistischer Blick auf die Thematik erschwert.
Die (unbegründete) Angst vor menschenleeren Fabriken und autonom arbeitenden Maschinen
Insbesondere in Betrieben der industriellen Fertigung geht diese Angst um, dass alle Arbeitsplätze dort zukünftig durch intelligente Maschinen ersetzt werden. Dabei wird übersehen, dass mit der Künstlichen Intelligenz nicht einfach nur der Grad an Automatisierung erhöht wird. Vielmehr ist es so, dass die Produktion als Ganzes transformiert wird und sich grundlegend verändert.
Künstliche Intelligenz läutet das Ende der Ära der automatisierten Massenproduktion ein. In der Smart Factory sind neue Produktionsformen möglich wie beispielsweise die „Lot-Size-One-Production“ oder „Losgröße-1-Fertigung“. Der Begriff bezeichnet die industrielle Fertigung von Einzelstücken.
By loading the video you accept YouTube’s privacy policy.
Learn more
Heute erleben wir mit dieser Entwicklung den Übergang in das Zeitalter der flexiblen Spezialisierung. Individuelle Kundenwünsche zu berücksichtigen wird heute durch den hohen Technologisierungsgrad bei der Produktion auf dem Level der Massenproduktion möglich. Sprich: Anstatt tausende Werkstücke der gleichen Sorte zu produzieren, können individuelle Kundenwünsche bei jedem einzelnen Auftrag berücksichtigt werden.
Menschen in Fabriken werden bei Szenarien wie diesen durchaus noch gebraucht. Und aus einem bestimmten Grund mehr denn je: Erst durch die Errungenschaften im Bereich der Künstlichen Intelligenz wird es möglich, dass es zu einer intensiveren Mensch-Maschine-Kooperation kommt. Die bisherige Entwicklung im Bereich Automatisierung schloss aufgrund ihrer eingeschränkten Möglichkeiten den Menschen eher aus.
Fazit und Ausblick
In den letzten Jahren erlebten altbekannte Methoden wie die des maschinellen Lernens eine Renaissance. Obwohl diese seit den 1970er Jahren theoretisch entwickelt wurden, war die Entwicklung im Bereich Rechenleistung und Speichertechnologie letztlich ausschlaggebend. Spannend bleibt die technologische Entwicklung wie etwa die des Quantencomputers. Sehr viel wichtiger wäre jedoch, das bereits heute vorhandene Potenzial von KI tatsächlich zu nutzen. Dafür muss das Bewusstsein geschärft werden, in welchen Fällen sich ein Einsatz von Künstlicher Intelligenz tatsächlich lohnt. Es gibt eine ganze Reihe von Gründen, warum es Unternehmen bisher kaum gelingt, Mehrwert aus ihren Daten zu generieren. Viele dieser Hindernisse können einfach beseitigt werden, um die Grundlage für den Einsatz von KI zu schaffen. Eines ist aber schon heute klar: Künstliche Intelligenz ist aus dem Leben nicht mehr wegzudenken.









0 Kommentare